High Fidelity Textual User Representation over Heterogeneous Sources via Reinforcement Learning
作者: Rajat Arora, Ye Tao, Jianqiang Shen, Ping Liu, Muchen Wu, Qianqi Shen, Benjamin Le, Fedor Borisyuk, Jingwei Wu, Wenjing Zhang
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-07
💡 一句话要点
提出基于强化学习的文本用户表示方法,解决异构数据源融合与LLM兼容问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 用户表示 文本建模 异构数据源 推荐系统
📋 核心要点
- 大型招聘平台需要基于异构文本源(如个人资料、职业数据和搜索日志)对用户进行建模,现有方法难以有效融合这些信息。
- 论文提出一种基于强化学习的框架,通过用户隐式行为信号作为奖励,提炼关键信息,并结合规则奖励约束格式和长度。
- 在LinkedIn的多个产品上进行的实验表明,该方法在关键业务指标上取得了显著改进,提供了一种可扩展且与LLM兼容的解决方案。
📝 摘要(中文)
本文提出了一种新颖的强化学习(RL)框架,用于合成统一的文本表示,以有效建模大型招聘平台上的用户。该方法利用隐式的用户参与信号(例如,点击、申请)作为主要奖励,从而提取关键信息。此外,该框架还辅以基于规则的奖励,以强制执行格式和长度约束。在LinkedIn的多个产品上进行的大量离线实验表明,该方法在关键下游业务指标方面取得了显著改进。这项工作为构建可解释的用户表示提供了一种实用的、无标签的、可扩展的解决方案,该表示与基于LLM的系统直接兼容。
🔬 方法详解
问题定义:现有方法难以从异构文本源(如用户资料、职业数据、搜索记录)中提取并融合关键信息,从而构建适用于大规模推荐系统,特别是与大型语言模型(LLM)兼容的统一用户表示。此外,现有方法通常缺乏可解释性,难以满足在线环境对低延迟的要求。
核心思路:论文的核心思路是利用强化学习(RL)框架,将用户在平台上的隐式行为信号(如点击、申请)作为奖励信号,引导模型从异构文本源中提取与用户兴趣最相关的信息。通过这种方式,模型能够学习到一种能够有效预测用户行为的文本表示。同时,为了保证生成文本的质量,还引入了基于规则的奖励,以约束文本的格式和长度。
技术框架:整体框架包含以下几个主要模块:1) 环境:模拟用户与平台的交互,接收用户行为并给出奖励。2) 智能体:基于强化学习算法,负责从异构文本源中选择和组合信息,生成用户表示。3) 奖励函数:由两部分组成,一部分是基于用户隐式行为的奖励,另一部分是基于规则的奖励。4) 文本生成器:将智能体选择的信息组合成最终的文本表示。
关键创新:最重要的技术创新点在于利用强化学习框架,将用户隐式行为信号作为奖励,从而实现无监督的用户表示学习。与传统的监督学习方法相比,该方法无需人工标注数据,能够更好地适应用户兴趣的变化。此外,该方法还能够生成可解释的文本表示,方便人工理解和调试。
关键设计:奖励函数的设计是关键。基于用户隐式行为的奖励通常采用点击率(CTR)或转化率(CVR)等指标。基于规则的奖励则用于约束生成文本的长度、格式和内容。智能体通常采用深度强化学习算法,如Policy Gradient或Actor-Critic方法。文本生成器可以使用预训练的语言模型,如BERT或GPT,以提高生成文本的质量。
🖼️ 关键图片

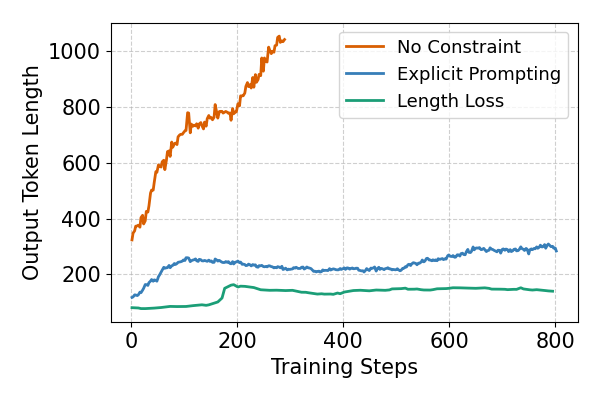
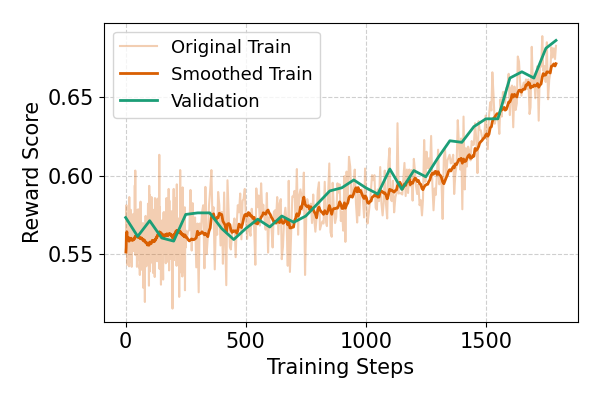
📊 实验亮点
实验结果表明,该方法在LinkedIn的多个产品上取得了显著改进。与现有方法相比,该方法在点击率、申请率等关键业务指标上均有显著提升。例如,在某个产品上,点击率提升了5%,申请率提升了3%。这些结果表明,该方法能够有效提高推荐系统的性能,并为平台带来实际的商业价值。
🎯 应用场景
该研究成果可广泛应用于各种需要用户建模的推荐系统,尤其是在招聘、电商等领域。通过构建高质量的用户表示,可以提高推荐的准确性和个性化程度,从而提升用户体验和平台收益。此外,该方法生成的可解释文本表示也有助于理解用户兴趣,为产品改进提供依据。未来,该方法可以进一步扩展到多模态数据融合,例如结合图像、视频等信息,构建更全面的用户画像。
📄 摘要(原文)
Effective personalization on large-scale job platforms requires modeling members based on heterogeneous textual sources, including profiles, professional data, and search activity logs. As recommender systems increasingly adopt Large Language Models (LLMs), creating unified, interpretable, and concise representations from heterogeneous sources becomes critical, especially for latency-sensitive online environments. In this work, we propose a novel Reinforcement Learning (RL) framework to synthesize a unified textual representation for each member. Our approach leverages implicit user engagement signals (e.g., clicks, applies) as the primary reward to distill salient information. Additionally, the framework is complemented by rule-based rewards that enforce formatting and length constraints. Extensive offline experiments across multiple LinkedIn products, one of the world's largest job platforms, demonstrate significant improvements in key downstream business metrics. This work provides a practical, labeling-free, and scalable solution for constructing interpretable user representations that are directly compatible with LLM-based systems.