Progressive Searching for Retrieval in RAG
作者: Taehee Jeong, Xingzhe Zhao, Peizu Li, Markus Valvur, Weihua Zhao
分类: cs.IR, cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出渐进式搜索算法,提升RAG系统中检索效率与准确性,适用于大规模数据库。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 向量检索 渐进式搜索 多阶段搜索 大规模数据库 信息检索
📋 核心要点
- RAG系统依赖高效检索相关文档,但现有方法在大规模数据库中面临检索速度和准确性的挑战。
- 论文提出渐进式搜索算法,通过多阶段搜索,从低维到高维逐步细化候选集,降低计算成本。
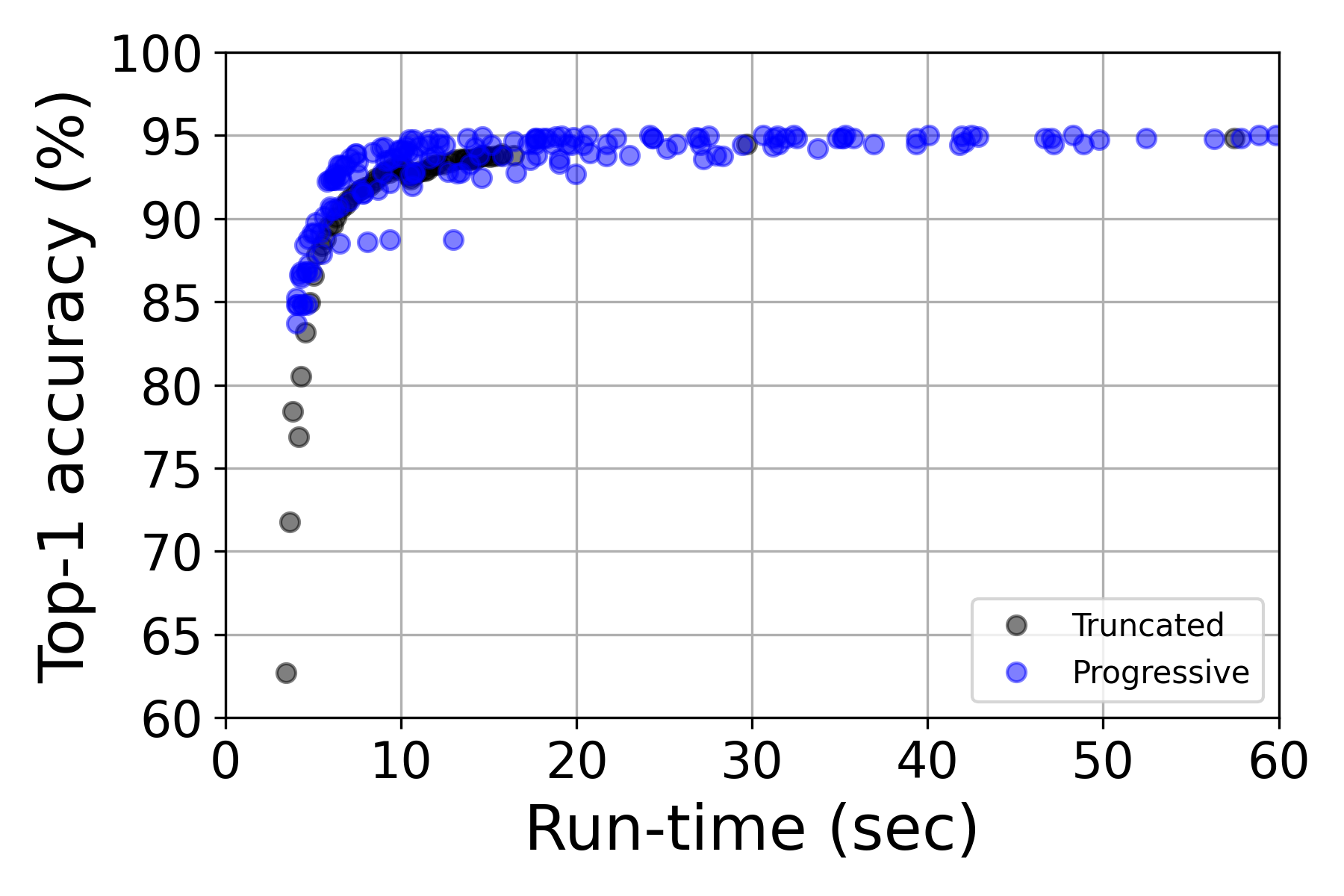
- 实验结果表明,该方法在保证检索准确性的前提下,显著提升了RAG系统的检索效率,适用于大规模数据库。
📝 摘要(中文)
检索增强生成(RAG)是一种有前景的技术,可以缓解大型语言模型(LLM)的两个关键限制:信息过时和幻觉。RAG系统将文档作为嵌入向量存储在数据库中。给定一个查询,执行搜索以找到最相关的文档。然后,将最匹配的文档插入到LLM的提示中以生成响应。高效准确的搜索对于RAG获取相关信息至关重要。我们提出了一种经济高效的搜索算法用于检索过程。我们的渐进式搜索算法通过搜索层次结构逐步细化候选集,从低维嵌入开始,然后进入更高的目标维度。这种多阶段方法减少了检索时间,同时保持了所需的准确性。我们的研究结果表明,RAG系统中的渐进式搜索实现了维度、速度和准确性之间的平衡,即使对于大型数据库也能实现可扩展和高性能的检索。
🔬 方法详解
问题定义:RAG系统在处理大规模文档时,检索速度和准确性之间存在权衡。传统的检索方法,例如直接在高维空间中进行相似度搜索,计算成本高昂,导致检索速度慢。现有的近似最近邻搜索方法虽然可以加速检索,但可能会牺牲一定的准确性,影响最终生成结果的质量。
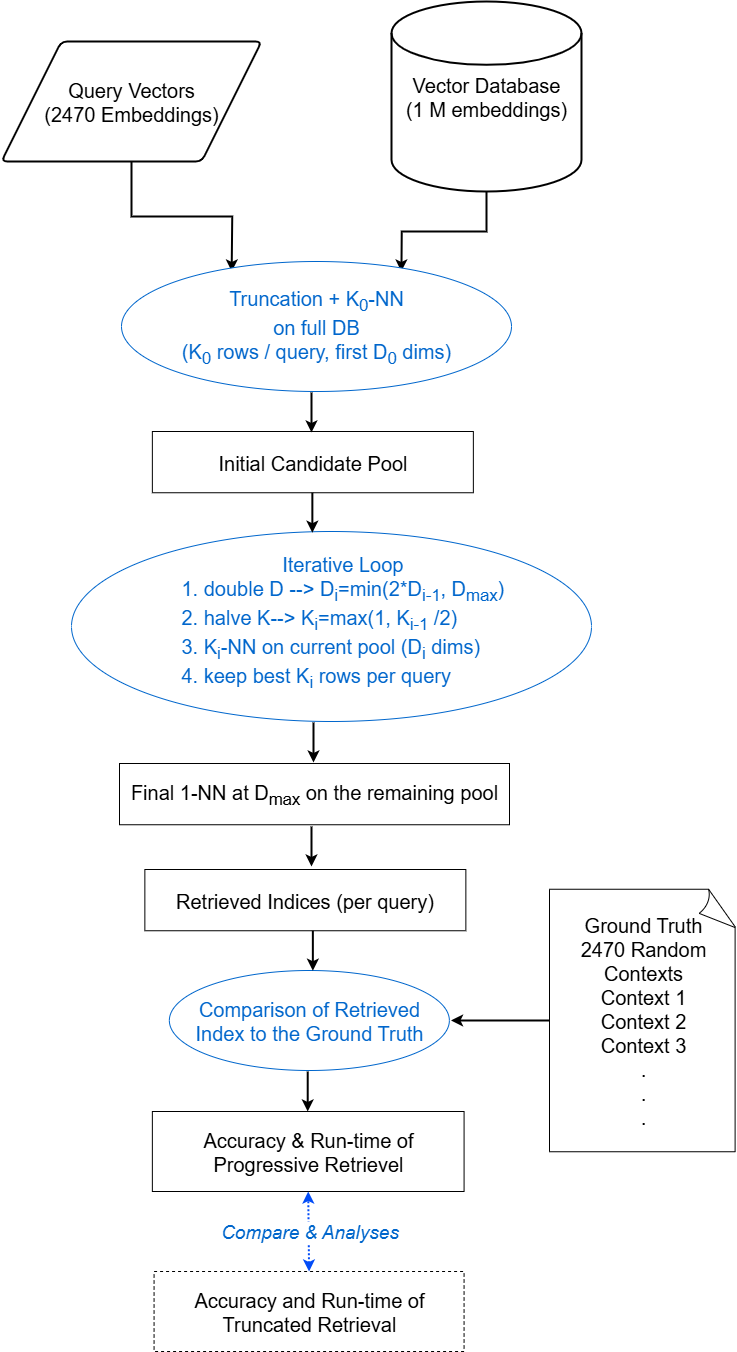
核心思路:论文的核心思路是利用文档嵌入向量的不同维度层级,进行渐进式的搜索。首先在低维空间进行粗略筛选,快速缩小候选集范围,然后在高维空间进行精细搜索,保证检索的准确性。这种分阶段的方法可以有效降低计算复杂度,提高检索效率。
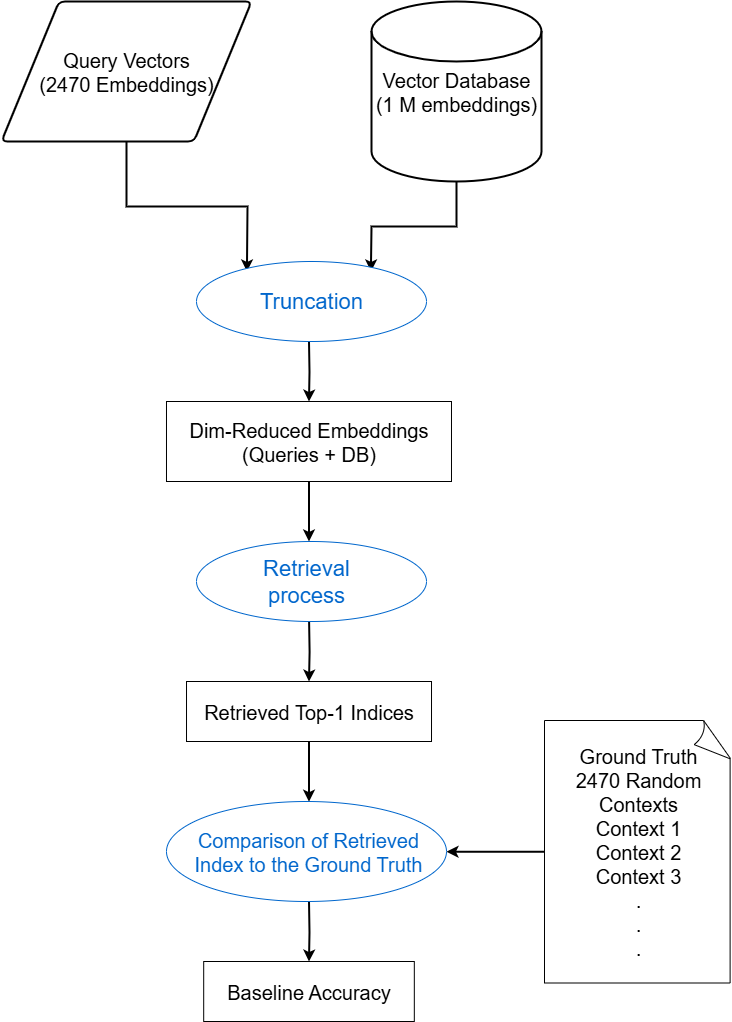
技术框架:渐进式搜索算法包含以下几个主要阶段: 1. 低维搜索:使用低维嵌入向量进行初始搜索,快速筛选出与查询相关的候选文档。 2. 中间维度搜索(可选):根据需要,可以增加中间维度搜索阶段,进一步缩小候选集范围。 3. 高维搜索:使用原始高维嵌入向量,对候选集进行精确搜索,找到最相关的文档。 4. 结果排序:根据相似度得分,对检索到的文档进行排序,选择Top-K个文档作为检索结果。
关键创新:该方法最重要的创新点在于提出了多阶段、分层级的搜索策略。与传统的单阶段搜索方法相比,渐进式搜索能够有效降低计算复杂度,提高检索效率,同时保证检索的准确性。这种方法充分利用了不同维度嵌入向量的信息,实现了维度、速度和准确性之间的平衡。
关键设计:关键设计包括: 1. 维度选择:需要根据具体应用场景和数据集,选择合适的低维、中间维度和高维嵌入向量。 2. 相似度度量:可以使用余弦相似度、点积等方法来衡量向量之间的相似度。 3. 阈值设置:在每个搜索阶段,需要设置合适的阈值来控制候选集的规模,避免过度过滤或遗漏相关文档。 4. 索引结构:可以使用诸如IVF(倒排索引)或HNSW(分层可导航小世界)等索引结构来加速搜索过程。
🖼️ 关键图片
📊 实验亮点
论文提出的渐进式搜索算法在RAG系统中实现了检索效率和准确性的平衡。实验结果表明,该方法能够在保证检索准确性的前提下,显著降低检索时间,尤其是在大规模数据库中,性能提升更为明显。具体的性能数据和对比基线(例如传统的高维向量搜索方法)在论文中进行了详细展示。
🎯 应用场景
该研究成果可广泛应用于各种需要RAG的场景,例如智能问答系统、知识库检索、代码生成等。通过提升检索效率和准确性,可以显著改善用户体验,提高生成内容的质量。尤其是在处理大规模知识库时,该方法能够有效降低检索成本,提高系统的可扩展性,具有重要的实际应用价值。
📄 摘要(原文)
Retrieval Augmented Generation (RAG) is a promising technique for mitigating two key limitations of large language models (LLMs): outdated information and hallucinations. RAG system stores documents as embedding vectors in a database. Given a query, search is executed to find the most related documents. Then, the topmost matching documents are inserted into LLMs' prompt to generate a response. Efficient and accurate searching is critical for RAG to get relevant information. We propose a cost-effective searching algorithm for retrieval process. Our progressive searching algorithm incrementally refines the candidate set through a hierarchy of searches, starting from low-dimensional embeddings and progressing into a higher, target-dimensionality. This multi-stage approach reduces retrieval time while preserving the desired accuracy. Our findings demonstrate that progressive search in RAG systems achieves a balance between dimensionality, speed, and accuracy, enabling scalable and high-performance retrieval even for large databases.