Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
作者: Pengrui Han, Xueqiang Xu, Keyang Xuan, Peiyang Song, Siru Ouyang, Runchu Tian, Yuqing Jiang, Cheng Qian, Pengcheng Jiang, Jiashuo Sun, Junxia Cui, Ming Zhong, Ge Liu, Jiawei Han, Jiaxuan You
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-02-07
💡 一句话要点
Steer2Adapt:通过动态组合steering vectors实现LLM的高效适应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型适应 激活Steering 动态组合 语义先验 数据高效 推理安全
📋 核心要点
- 现有steering方法依赖于单一静态方向,无法灵活应对任务变化和复杂任务。
- STEER2ADAPT通过组合steering vectors来调整LLM,而非从头学习,提升适应性。
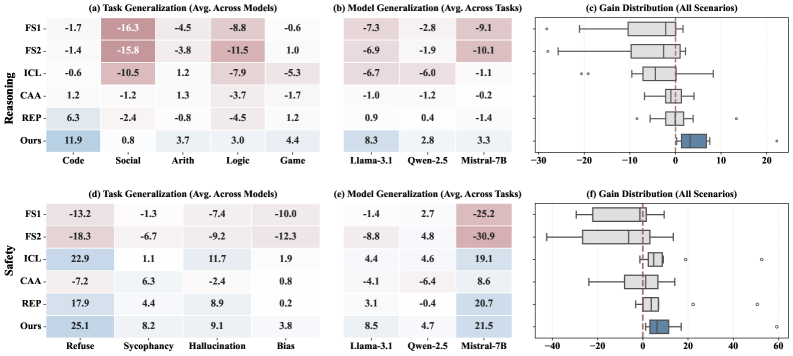
- 实验表明,STEER2ADAPT在推理和安全任务上平均提升8.2%,且数据效率高。
📝 摘要(中文)
激活steering是一种有效调整大型语言模型(LLM)以适应下游行为的方法。然而,现有steering方法大多依赖于每个任务或概念的单一静态方向,这使得它们在任务变化下缺乏灵活性,并且不足以应对需要多个协调能力的复杂任务。为了解决这个局限性,我们提出了STEER2ADAPT,一个轻量级框架,通过组合steering vectors来调整LLM,而不是从头开始学习新的steering vectors。在许多领域(例如,推理或安全性),任务共享一小组潜在的概念维度。STEER2ADAPT将这些维度捕获为可重用的、低维的语义先验子空间,并通过仅从少量示例中动态发现基向量的线性组合来适应新任务。在推理和安全领域的9个任务和3个模型上的实验证明了STEER2ADAPT的有效性,平均提高了8.2%。广泛的分析进一步表明,STEER2ADAPT是一种数据高效、稳定和透明的LLM推理时适应方法。
🔬 方法详解
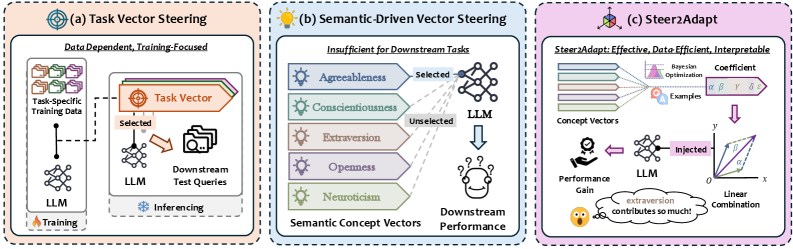
问题定义:现有的大型语言模型(LLM)的steering方法通常使用单一的、静态的steering vector来调整模型的行为,这在面对任务变化或需要多种能力协同的复杂任务时表现出明显的局限性。这些方法缺乏灵活性,难以适应新的任务需求,并且需要为每个任务单独学习steering vector,效率较低。
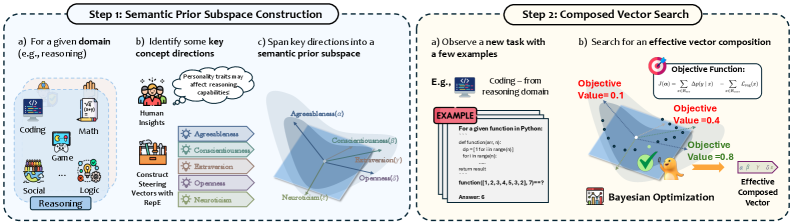
核心思路:STEER2ADAPT的核心思路是利用任务之间共享的底层概念维度,构建一个可重用的、低维的语义先验子空间。通过在这个子空间中动态地组合基向量,生成适应特定任务的steering vector,从而实现对LLM的高效调整。这种方法避免了为每个新任务从头开始学习steering vector的需要,提高了数据效率和泛化能力。
技术框架:STEER2ADAPT框架主要包含以下几个阶段:1) 语义先验子空间构建:通过分析多个相关任务,提取共享的概念维度,并将其表示为一组基向量,构成语义先验子空间。2) 动态组合:对于新的任务,利用少量示例数据,学习基向量的线性组合系数,生成适应当前任务的steering vector。3) 模型调整:将生成的steering vector注入到LLM的激活层中,从而调整模型的行为。
关键创新:STEER2ADAPT的关键创新在于其动态组合steering vectors的能力。与传统的静态steering方法不同,STEER2ADAPT能够根据任务的特定需求,灵活地调整steering vector的方向和强度,从而更好地适应任务变化。此外,通过利用语义先验子空间,STEER2ADAPT能够实现数据高效的调整,仅需少量示例即可达到良好的性能。
关键设计:STEER2ADAPT的关键设计包括:1) 基向量的选择:基向量的选择直接影响语义先验子空间的表达能力。论文可能采用了某种方法来选择最具代表性的基向量。2) 线性组合系数的学习:线性组合系数的学习是动态组合的关键。论文可能使用了某种优化算法(如梯度下降)来学习这些系数,并可能引入了正则化项以防止过拟合。3) steering vector注入的位置和方式:steering vector注入到LLM的具体激活层的位置和方式也会影响调整效果。论文可能探索了不同的注入策略。
🖼️ 关键图片
📊 实验亮点
STEER2ADAPT在9个任务和3个模型上进行了实验,涵盖推理和安全领域,平均性能提升8.2%。实验结果表明,STEER2ADAPT具有数据高效性,仅需少量样本即可实现显著的性能提升。此外,该方法还表现出良好的稳定性和透明性,易于理解和调试。
🎯 应用场景
STEER2ADAPT具有广泛的应用前景,例如可以应用于安全相关的LLM调整,使其更好地避免生成有害内容;也可以用于个性化LLM,使其更好地满足用户的特定需求。此外,该方法还可以应用于机器人控制、对话系统等领域,提高系统的适应性和鲁棒性。未来,该方法有望成为LLM高效适应的重要工具。
📄 摘要(原文)
Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.