How Well Can LLM Agents Simulate End-User Security and Privacy Attitudes and Behaviors?
作者: Yuxuan Li, Leyang Li, Hao-Ping, Lee, Sauvik Das
分类: cs.CY, cs.AI, cs.CL, cs.CR
发布日期: 2026-02-06
💡 一句话要点
SP-ABCBench评估LLM智能体模拟用户安全隐私态度的能力,发现仍有提升空间
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全隐私 用户行为模拟 基准测试 智能体 有限理性 SP-ABCBench
📋 核心要点
- 现有研究依赖LLM智能体模拟用户安全隐私行为,但其有效性未经充分验证,存在潜在风险。
- 论文提出SP-ABCBench基准,包含30个安全隐私相关任务,用于评估LLM智能体的模拟能力。
- 实验表明,现有LLM智能体在模拟用户安全隐私行为方面仍有提升空间,但特定配置下表现良好。
📝 摘要(中文)
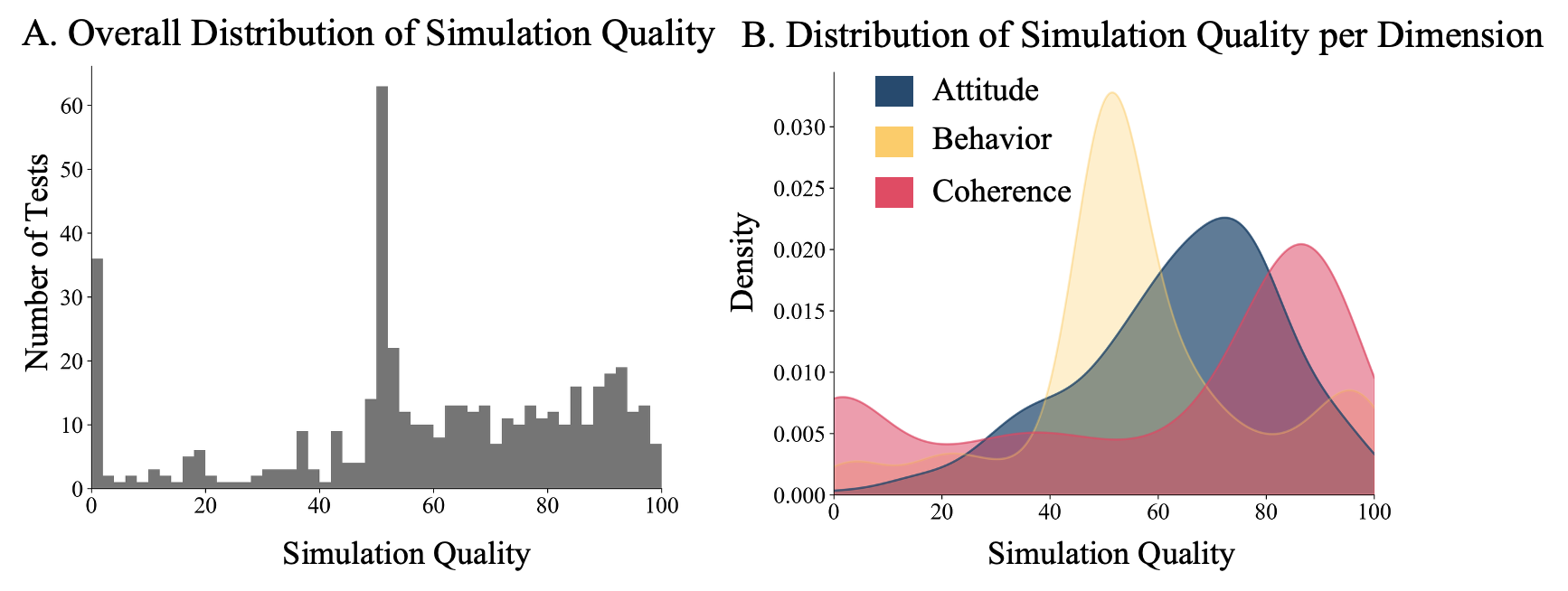
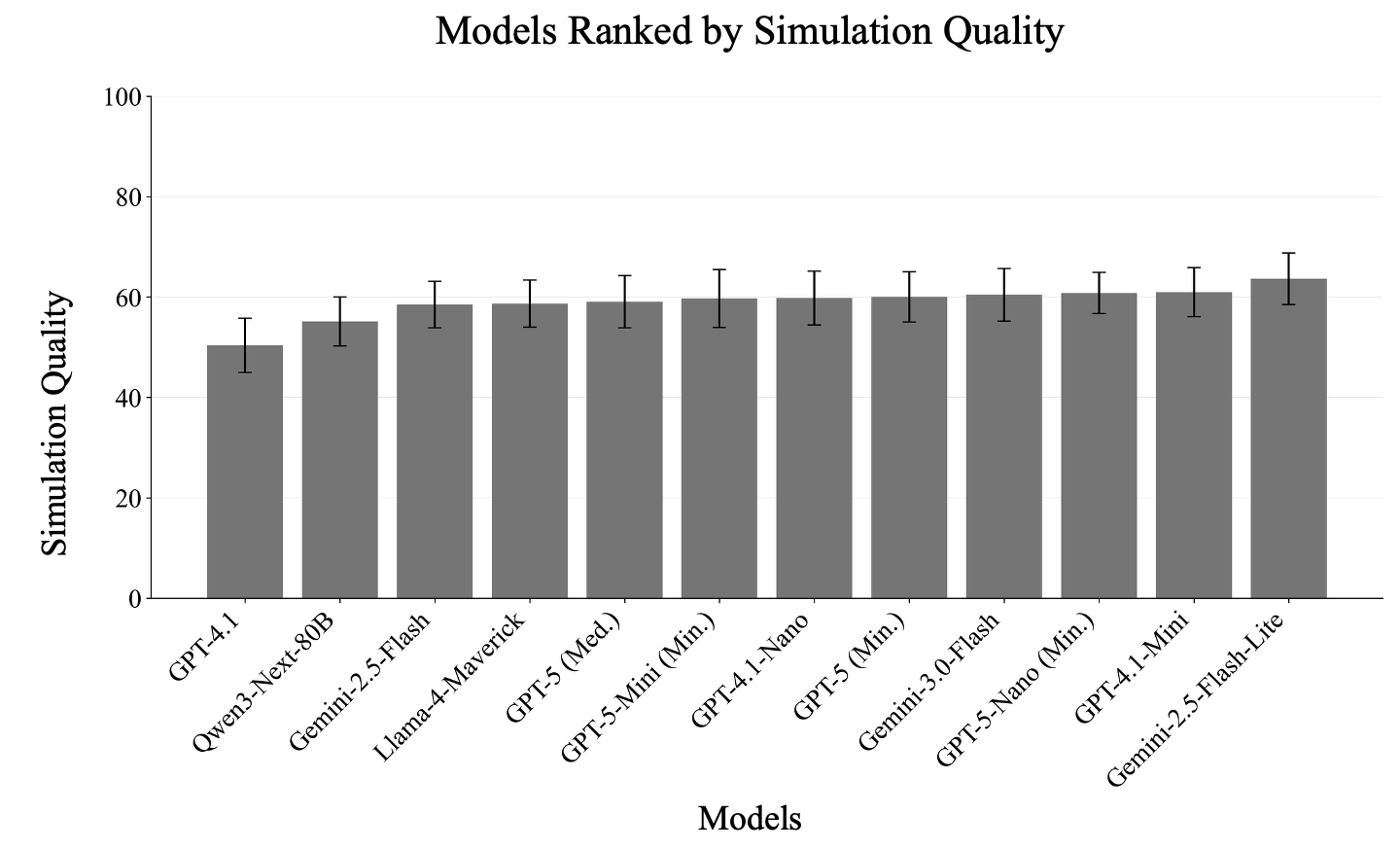
越来越多的研究假设,大型语言模型(LLM)智能体可以作为代理,模拟人们对安全和隐私(S&P)威胁的态度和行为。如果正确,这些模拟可以提供一种可扩展的方法,在产品部署之前预测S&P风险。本文使用SP-ABCBench来研究这个假设,这是一个新的基准,包含30个来自经过验证的S&P人类受试者研究的测试,它以0-100的递增尺度衡量模拟和人类受试者研究之间的一致性,其中更高的分数表示在三个维度上更好的一致性:态度、行为和连贯性。通过评估十二个LLM、四种角色构建策略和两种提示方法,发现仍有很大的改进空间:所有模型的平均得分都在50到64之间。更新、更大、更智能的模型并没有更可靠地做得更好,有时甚至更糟。然而,一些模拟配置确实产生了高度一致性:例如,当提示智能体应用有限理性并将隐私成本与感知到的收益进行权衡时,某些行为测试的得分高于95。本文发布SP-ABCBench,以支持随着方法的改进进行可重复的评估。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)智能体在多大程度上能够准确模拟终端用户在安全和隐私(S&P)方面的态度和行为。现有方法假设LLM可以作为人类行为的有效代理,但缺乏系统性的评估和验证。这种假设的风险在于,如果LLM的模拟不准确,可能会导致对S&P风险的错误预测,从而影响产品设计和安全策略。
核心思路:论文的核心思路是构建一个基准测试集SP-ABCBench,该基准包含来自已验证的人类受试者研究的S&P相关任务,通过比较LLM智能体的模拟结果与人类受试者的实际行为,量化LLM智能体模拟的准确性。通过系统性的评估,揭示LLM智能体在模拟S&P行为方面的优势和局限性,为未来的研究提供指导。
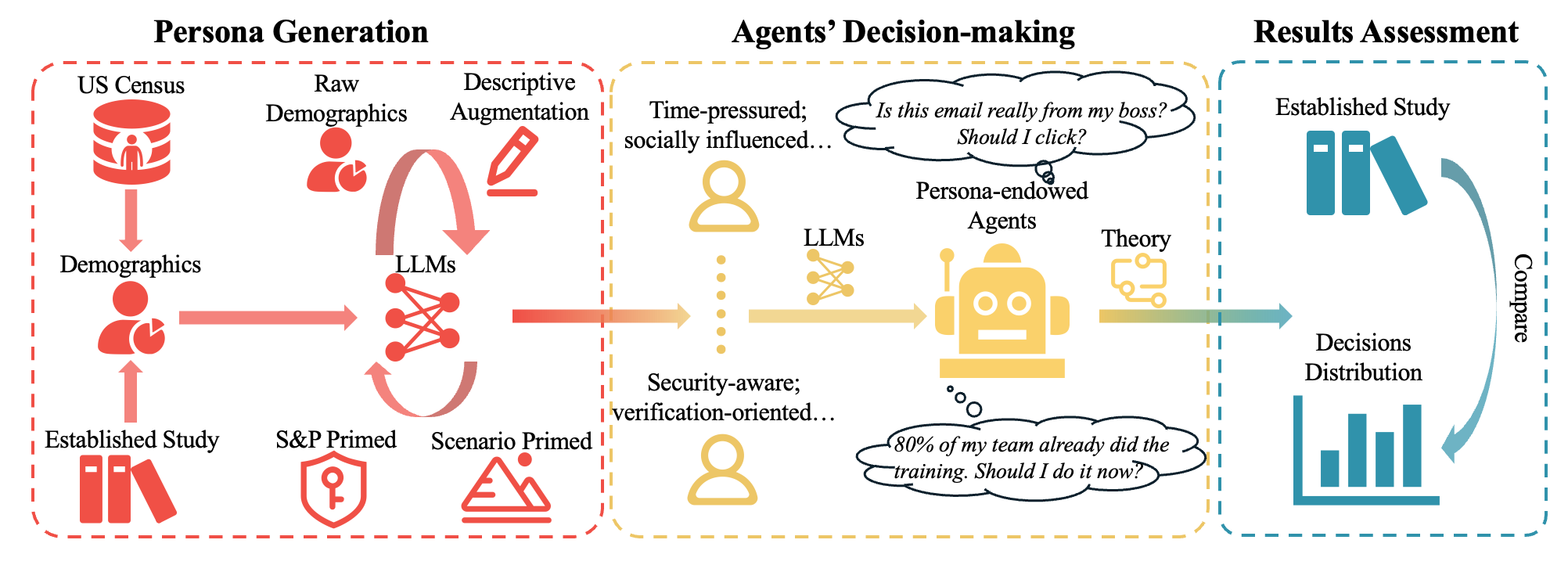
技术框架:论文的技术框架主要包括以下几个部分:1) SP-ABCBench基准构建:从已验证的S&P人类受试者研究中提取30个测试用例,涵盖态度、行为和连贯性三个维度。2) LLM智能体配置:选择12个LLM模型,并采用四种角色构建策略和两种提示方法来配置LLM智能体。3) 模拟实验:使用配置好的LLM智能体在SP-ABCBench上进行模拟实验,记录智能体的行为和决策。4) 一致性评估:将LLM智能体的模拟结果与人类受试者研究的结果进行比较,计算一致性得分,评估LLM智能体模拟的准确性。
关键创新:论文的关键创新在于提出了SP-ABCBench基准,这是一个专门用于评估LLM智能体模拟用户安全隐私行为能力的基准。与现有的通用基准不同,SP-ABCBench专注于S&P领域,能够更准确地评估LLM智能体在特定领域的模拟能力。此外,论文还系统地研究了不同LLM模型、角色构建策略和提示方法对模拟结果的影响,为如何提高LLM智能体模拟的准确性提供了有价值的见解。
关键设计:SP-ABCBench基准中的每个测试用例都包含一个S&P相关的场景描述和一系列问题,用于评估智能体的态度、行为和连贯性。一致性得分的计算方法是基于LLM智能体的模拟结果与人类受试者研究结果之间的相似度,采用0-100的递增尺度,其中更高的分数表示更好的一致性。在提示方法方面,论文采用了标准提示和有限理性提示两种方法,有限理性提示旨在引导智能体在决策时考虑隐私成本和收益。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有LLM智能体在SP-ABCBench上的平均得分在50到64之间,表明仍有较大的提升空间。值得注意的是,更新、更大、更智能的模型并没有始终表现更好,有时甚至更差。然而,在某些配置下,例如使用有限理性提示时,LLM智能体在某些行为测试中获得了高于95分的高分,表明通过合理的配置,LLM智能体可以有效地模拟用户行为。
🎯 应用场景
该研究成果可应用于安全隐私风险预测、用户行为建模、安全意识培训等领域。通过使用LLM智能体模拟用户行为,可以提前识别产品或系统中的潜在安全隐私风险,并制定相应的应对措施。此外,该研究还可以用于个性化安全意识培训,根据不同用户的特点和行为习惯,提供更有针对性的培训内容。
📄 摘要(原文)
A growing body of research assumes that large language model (LLM) agents can serve as proxies for how people form attitudes toward and behave in response to security and privacy (S&P) threats. If correct, these simulations could offer a scalable way to forecast S&P risks in products prior to deployment. We interrogate this assumption using SP-ABCBench, a new benchmark of 30 tests derived from validated S&P human-subject studies, which measures alignment between simulations and human-subjects studies on a 0-100 ascending scale, where higher scores indicate better alignment across three dimensions: Attitude, Behavior, and Coherence. Evaluating twelve LLMs, four persona construction strategies, and two prompting methods, we found that there remains substantial room for improvement: all models score between 50 and 64 on average. Newer, bigger, and smarter models do not reliably do better and sometimes do worse. Some simulation configurations, however, do yield high alignment: e.g., with scores above 95 for some behavior tests when agents are prompted to apply bounded rationality and weigh privacy costs against perceived benefits. We release SP-ABCBench to enable reproducible evaluation as methods improve.