Evidence for Daily and Weekly Periodic Variability in GPT-4o Performance
作者: Paul Tschisgale, Peter Wulff
分类: stat.AP, cs.AI, cs.CL, physics.ed-ph
发布日期: 2026-02-06
💡 一句话要点
揭示GPT-4o性能的每日和每周周期性波动,挑战时间不变性假设
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时间变异性 周期性波动 GPT-4o 纵向研究
📋 核心要点
- 现有研究通常假设LLM在固定条件下的性能是时间不变的,但这一假设可能并不成立,影响研究的可靠性。
- 该研究通过纵向实验,分析GPT-4o在解决同一物理任务时的性能随时间的变化,揭示其周期性模式。
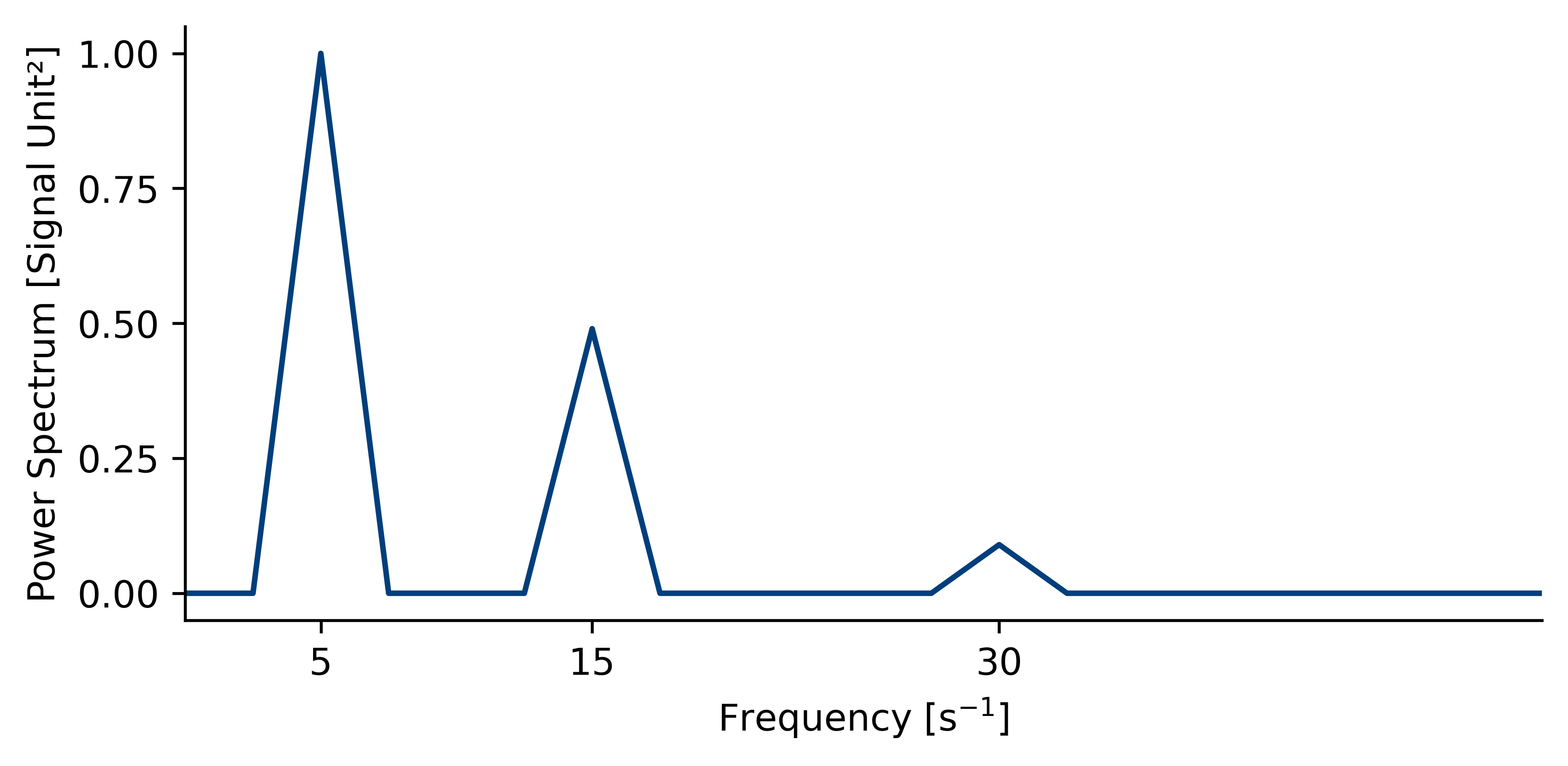
- 实验发现GPT-4o的性能存在显著的每日和每周周期性波动,约占总方差的20%,挑战了时间不变性的假设。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用作研究工具和研究对象。许多研究隐含地假设LLM在固定条件(相同的模型快照、超参数和提示)下的性能是时间不变的。如果平均输出质量随时间发生系统性变化,这个假设就会被打破,从而威胁到研究结果的可靠性、有效性和可重复性。为了实证检验这个假设,我们对GPT-4o平均性能的时间变异性进行了纵向研究。使用固定的模型快照、固定的超参数和相同的提示,通过API每三个小时查询一次GPT-4o,以解决相同的多项选择物理任务,持续约三个月。在每个时间点生成十个独立的响应并对其分数进行平均。对结果时间序列进行频谱(傅里叶)分析,揭示了平均模型性能中显著的周期性变异性,约占总方差的20%。特别是,观察到的周期性模式可以通过每日和每周节奏的相互作用很好地解释。这些发现表明,即使在受控条件下,LLM的性能也可能随时间周期性地变化,从而质疑了时间不变性的假设。讨论了确保使用或研究LLM的研究的有效性和可重复性的意义。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)性能随时间变化的问题。现有研究通常假设LLM在固定条件下的性能是时间不变的,但实际情况可能并非如此。这种时间变异性会影响使用LLM进行研究的可靠性、有效性和可重复性。因此,论文要解决的问题是验证LLM性能的时间不变性假设,并量化其时间变异性。
核心思路:论文的核心思路是通过纵向实验,长时间监测LLM在固定条件下的性能变化。具体来说,选择GPT-4o作为研究对象,使用固定的模型快照、超参数和提示,重复执行相同的任务,并记录其性能。然后,通过时间序列分析,检测性能中是否存在周期性模式,从而揭示LLM性能的时间变异性。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 任务选择:选择多项选择物理任务作为评估LLM性能的任务。 2. 数据采集:每三个小时通过API查询GPT-4o,生成十个独立的响应,并计算平均分数。 3. 时间序列分析:对采集到的时间序列数据进行频谱(傅里叶)分析,检测是否存在周期性模式。 4. 结果分析:分析频谱分析的结果,确定周期性模式的频率和幅度,并解释其可能的成因。
关键创新:该研究的关键创新在于首次对LLM的性能时间变异性进行了系统的纵向研究。通过长时间的监测和时间序列分析,揭示了GPT-4o性能中存在的每日和每周周期性波动。这一发现挑战了LLM性能时间不变性的假设,为后续研究提供了重要的参考。
关键设计: * 模型选择:选择GPT-4o作为研究对象,因为它是一个广泛使用的LLM。 * 任务设计:选择多项选择物理任务,因为它易于评估和重复执行。 * 数据采集频率:每三个小时采集一次数据,以捕捉可能的每日和每周周期性模式。 * 时间序列分析方法:使用傅里叶分析,因为它是一种常用的检测周期性模式的方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o的性能存在显著的每日和每周周期性波动,约占总方差的20%。通过傅里叶分析,确定了每日和每周周期性模式的频率和幅度。这些发现表明,即使在受控条件下,LLM的性能也可能随时间周期性地变化,从而质疑了时间不变性的假设。
🎯 应用场景
该研究结果对LLM的应用具有重要意义。在研究中使用LLM时,需要考虑其性能的时间变异性,以确保研究结果的可靠性和可重复性。例如,在比较不同LLM的性能时,应该在同一时间段内进行评估,以避免时间变异性带来的偏差。此外,该研究也为LLM的优化提供了新的思路,例如,可以通过调整LLM的内部机制,减少其性能的时间变异性。
📄 摘要(原文)
Large language models (LLMs) are increasingly used in research both as tools and as objects of investigation. Much of this work implicitly assumes that LLM performance under fixed conditions (identical model snapshot, hyperparameters, and prompt) is time-invariant. If average output quality changes systematically over time, this assumption is violated, threatening the reliability, validity, and reproducibility of findings. To empirically examine this assumption, we conducted a longitudinal study on the temporal variability of GPT-4o's average performance. Using a fixed model snapshot, fixed hyperparameters, and identical prompting, GPT-4o was queried via the API to solve the same multiple-choice physics task every three hours for approximately three months. Ten independent responses were generated at each time point and their scores were averaged. Spectral (Fourier) analysis of the resulting time series revealed notable periodic variability in average model performance, accounting for approximately 20% of the total variance. In particular, the observed periodic patterns are well explained by the interaction of a daily and a weekly rhythm. These findings indicate that, even under controlled conditions, LLM performance may vary periodically over time, calling into question the assumption of time invariance. Implications for ensuring validity and replicability of research that uses or investigates LLMs are discussed.