BEAGLE: Behavior-Enforced Agent for Grounded Learner Emulation
作者: Hanchen David Wang, Clayton Cohn, Zifan Xu, Siyuan Guo, Gautam Biswas, Meiyi Ma
分类: cs.AI
发布日期: 2026-02-06
备注: paper under submission at IJCAI
💡 一句话要点
BEAGLE:行为增强的智能体,用于模拟扎根学习者的学习过程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 学生行为模拟 自我调节学习 神经符号框架 贝叶斯知识追踪 半马尔可夫模型
📋 核心要点
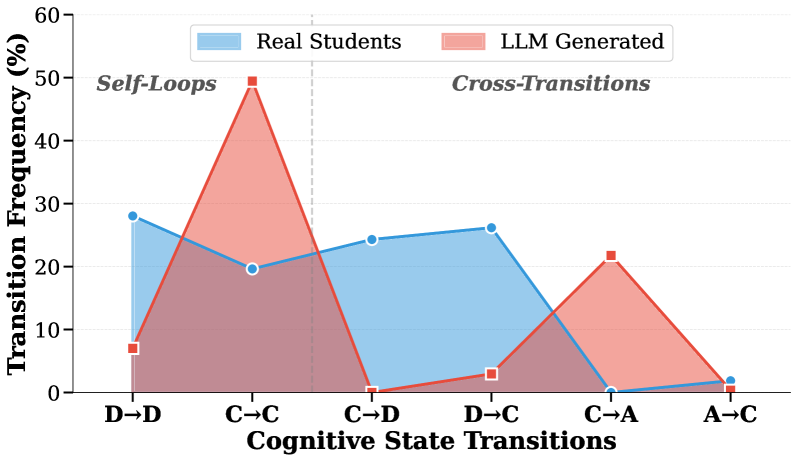
- 现有LLM在模拟学生学习行为时,倾向于追求高效正确性,缺乏真实学习者的探索和试错过程。
- BEAGLE通过融入自我调节学习理论,采用神经符号框架,模拟认知和元认知行为,以及知识缺陷。
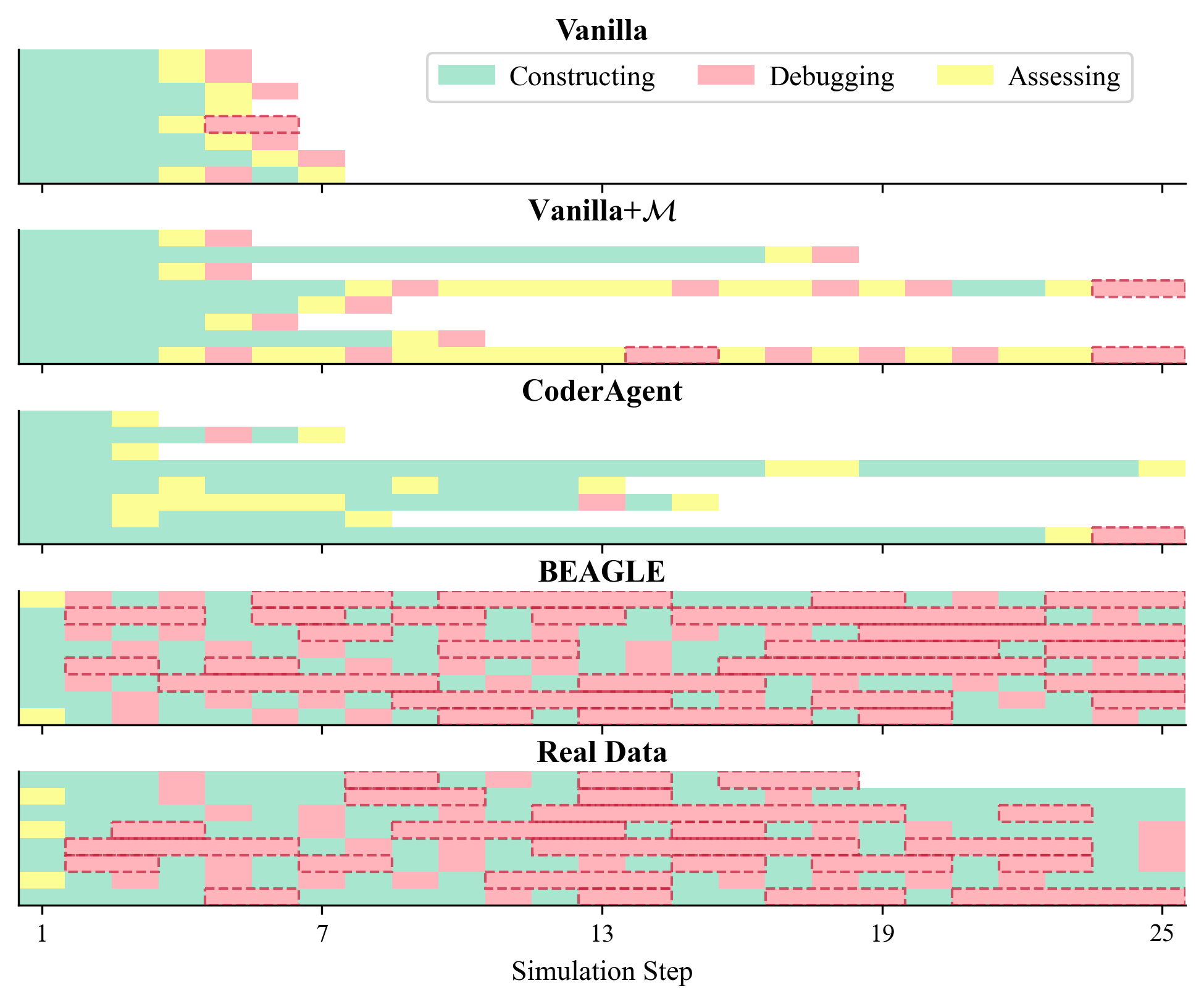
- 实验表明,BEAGLE能更真实地模拟学生学习轨迹,在图灵测试中难以与真实学生数据区分。
📝 摘要(中文)
在开放式问题解决环境中模拟学生学习行为,对于教育研究具有重要潜力,例如训练自适应辅导系统和压力测试教学干预。然而,由于隐私问题和长期研究的高成本,收集真实数据具有挑战性。大型语言模型(LLM)为学生模拟提供了一条有希望的途径,但它们存在能力偏差,优化的是高效的正确性,而不是新手学习者特有的不稳定、迭代的挣扎。我们提出了BEAGLE,一个神经符号框架,通过将自我调节学习(SRL)理论融入到一种新颖的架构中来解决这种偏差。BEAGLE集成了三个关键的技术创新:(1)一个半马尔可夫模型,用于控制认知行为和元认知行为的时间和转换;(2)具有显式缺陷注入的贝叶斯知识追踪,以强制执行真实的知识差距和“未知的未知”;(3)一个解耦的智能体设计,将高层策略使用与代码生成动作分离,以防止模型默默地纠正其自身的有意错误。在Python编程任务的评估中,BEAGLE在重现真实轨迹方面显著优于最先进的基线。在人工图灵测试中,用户无法区分合成轨迹与真实学生数据,准确率与随机猜测(52.8%)没有区别。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型(LLM)模拟学生学习行为时,LLM倾向于表现出过高的能力和效率,无法真实反映新手学习者在解决问题过程中遇到的困难、错误和迭代过程。现有方法难以模拟学生在学习过程中表现出的知识差距和“未知的未知”。
核心思路:论文的核心思路是将自我调节学习(SRL)理论融入到LLM中,通过模拟学生的认知和元认知行为,以及显式地注入知识缺陷,来增强LLM模拟学生学习过程的真实性。这种方法旨在使LLM能够生成更接近真实学生学习轨迹的行为序列。
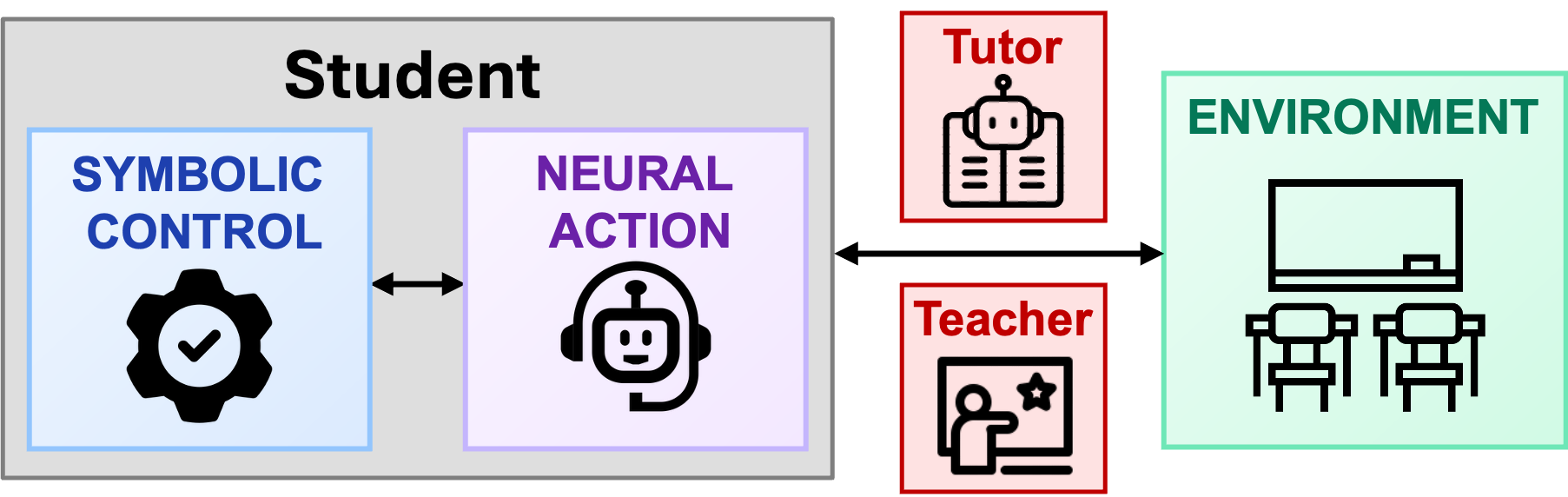
技术框架:BEAGLE框架包含三个主要模块:(1) 半马尔可夫模型:用于建模认知行为和元认知行为的时间和转换。(2) 贝叶斯知识追踪(BKT)与缺陷注入:用于模拟学生的知识状态,并显式地引入知识缺陷和“未知的未知”。(3) 解耦的智能体设计:将高层策略使用与代码生成动作分离,防止模型在生成代码时默默地纠正其有意犯下的错误。整体流程是,半马尔可夫模型决定下一步的行为类型,BKT模型提供知识状态信息,解耦的智能体根据策略和知识状态生成相应的代码或行为。
关键创新:BEAGLE的关键创新在于其神经符号架构,它将LLM的生成能力与SRL理论的结构化建模相结合。与直接使用LLM生成学习轨迹的方法不同,BEAGLE通过半马尔可夫模型显式地控制行为的转换,并通过BKT模型模拟知识状态的变化,从而更精确地模拟学生的学习过程。此外,解耦的智能体设计避免了模型在代码生成过程中自动纠正错误,保证了模拟轨迹的真实性。
关键设计:半马尔可夫模型使用可学习的转移概率矩阵来控制认知和元认知行为之间的转换。BKT模型使用标准的BKT公式来更新学生的知识状态,并通过显式地设置遗忘率和猜测率来模拟知识的遗忘和随机猜测。缺陷注入机制通过随机地将某些知识单元标记为“未知”,来模拟学生知识的不足。解耦的智能体设计使用两个独立的LLM,一个负责策略选择,另一个负责代码生成,并通过一个共享的上下文向量来传递信息。
🖼️ 关键图片
📊 实验亮点
BEAGLE在Python编程任务上显著优于现有基线方法,能够更真实地重现学生的学习轨迹。在人工图灵测试中,用户无法区分BEAGLE生成的合成轨迹与真实学生数据,准确率仅为52.8%,与随机猜测无显著差异。这表明BEAGLE在模拟学生学习行为方面达到了很高的逼真度。
🎯 应用场景
BEAGLE可应用于教育研究领域,例如训练自适应辅导系统,该系统可以根据学生的学习行为和知识状态提供个性化的指导。此外,BEAGLE还可以用于压力测试教学干预,评估不同教学策略对学生学习效果的影响。该研究有助于更深入地理解学生的学习过程,并为开发更有效的教育工具和方法提供依据。
📄 摘要(原文)
Simulating student learning behaviors in open-ended problem-solving environments holds potential for education research, from training adaptive tutoring systems to stress-testing pedagogical interventions. However, collecting authentic data is challenging due to privacy concerns and the high cost of longitudinal studies. While Large Language Models (LLMs) offer a promising path to student simulation, they suffer from competency bias, optimizing for efficient correctness rather than the erratic, iterative struggle characteristic of novice learners. We present BEAGLE, a neuro-symbolic framework that addresses this bias by incorporating Self-Regulated Learning (SRL) theory into a novel architecture. BEAGLE integrates three key technical innovations: (1) a semi-Markov model that governs the timing and transitions of cognitive behaviors and metacognitive behaviors; (2) Bayesian Knowledge Tracing with explicit flaw injection to enforce realistic knowledge gaps and "unknown unknowns"; and (3) a decoupled agent design that separates high-level strategy use from code generation actions to prevent the model from silently correcting its own intentional errors. In evaluations on Python programming tasks, BEAGLE significantly outperforms state-of-the-art baselines in reproducing authentic trajectories. In a human Turing test, users were unable to distinguish synthetic traces from real student data, achieving an accuracy indistinguishable from random guessing (52.8%).