Is there "Secret Sauce'' in Large Language Model Development?
作者: Matthias Mertens, Natalia Fischl-Lanzoni, Neil Thompson
分类: cs.AI, cs.LG, econ.GN
发布日期: 2026-02-06
💡 一句话要点
大规模语言模型性能主要由算力驱动,但开发者效率差异显著影响非前沿模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 缩放定律 开发者效率 固定效应模型 算力 模型性能 人工智能领导力
📋 核心要点
- 现有研究未能充分区分算力投入和开发者自身技术对LLM性能的影响。
- 该研究通过分析大量LLM的训练数据,结合缩放定律回归和固定效应模型,量化了开发者效率的贡献。
- 结果表明,前沿LLM主要由算力驱动,但非前沿模型性能受开发者效率影响显著,且公司内部效率差异巨大。
📝 摘要(中文)
领先的大语言模型(LLM)开发者是否拥有专有的“秘密武器”,还是LLM的性能主要由算力扩展驱动?本文利用2022年至2025年发布的809个模型的训练和基准数据,通过发布日期和开发者固定效应估计了缩放定律回归。研究发现,存在明显的开发者特定的效率优势,但其重要性取决于模型在性能分布中的位置。在前沿,80-90%的性能差异可以通过更高的训练算力来解释,这意味着规模而非专有技术驱动了前沿进展。然而,在非前沿,专有技术和共享算法进步显著降低了达到固定能力阈值所需的算力。一些公司可以系统地更有效地生产更小的模型。引人注目的是,我们还发现公司内部模型效率存在显著差异;一家公司可以训练两个算力效率相差40倍以上的模型。我们还讨论了对人工智能领导地位和能力扩散的影响。
🔬 方法详解
问题定义:论文旨在探究大规模语言模型(LLM)的性能提升,究竟是主要由算力规模驱动,还是由不同开发者的专有技术(“秘密武器”)所驱动。现有研究未能有效区分算力投入和开发者自身技术水平对模型性能的独立影响,导致对LLM发展趋势的理解不够深入。
核心思路:论文的核心思路是利用已发布的LLM的训练数据和基准测试结果,通过统计建模的方法,将算力投入和开发者效应进行解耦。具体而言,通过构建包含发布日期和开发者固定效应的缩放定律回归模型,来量化不同开发者在相同算力投入下所能达到的性能差异。
技术框架:论文的技术框架主要包括以下几个步骤:1) 数据收集:收集2022年至2025年发布的809个LLM的训练数据(包括算力投入)和基准测试结果。2) 模型构建:构建缩放定律回归模型,将模型性能作为因变量,算力投入作为自变量,并加入发布日期和开发者固定效应。3) 参数估计:使用回归方法估计模型参数,包括算力对性能的影响、发布日期对性能的影响(反映算法进步)以及开发者固定效应(反映开发者效率)。4) 结果分析:分析不同开发者固定效应的显著性和大小,以及算力投入对性能的解释程度,从而判断“秘密武器”是否存在以及其重要性。
关键创新:论文的关键创新在于:1) 提出了一个量化开发者效率的方法,通过固定效应模型将开发者效应从算力效应中分离出来。2) 揭示了LLM性能提升的不同阶段,在前沿主要由算力驱动,而在非前沿则受开发者效率影响更大。3) 发现了同一公司内部不同模型之间存在巨大的效率差异,这表明即使在同一组织内部,也存在技术水平的显著差异。
关键设计:论文的关键设计包括:1) 使用缩放定律回归模型来捕捉算力与性能之间的关系。2) 引入发布日期固定效应来控制算法进步的影响。3) 引入开发者固定效应来量化开发者效率。4) 使用大量的LLM数据来保证统计结果的可靠性。
🖼️ 关键图片
📊 实验亮点
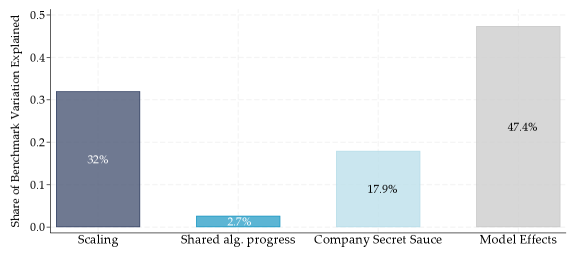
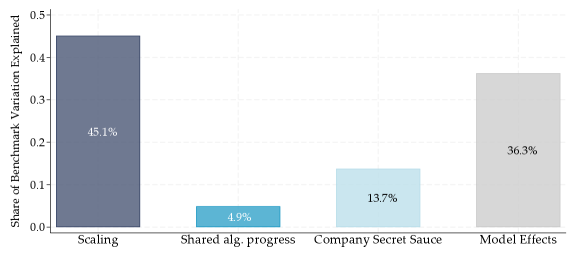
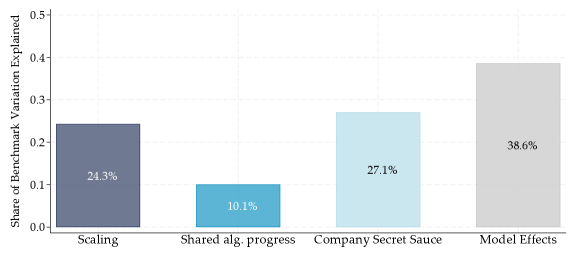
研究发现,在前沿LLM中,80-90%的性能差异可以通过更高的训练算力来解释。然而,在非前沿LLM中,专有技术和共享算法进步显著降低了达到固定能力阈值所需的算力。此外,研究还发现同一公司内部不同模型之间存在高达40倍的算力效率差异。
🎯 应用场景
该研究结果对人工智能领域的领导地位和能力扩散具有重要意义。它可以帮助企业和研究机构更好地评估自身的技术水平,制定合理的研发策略,并更有效地利用算力资源。此外,该研究还可以为政策制定者提供参考,帮助他们更好地理解LLM的发展趋势,并制定相应的政策来促进人工智能技术的健康发展。
📄 摘要(原文)
Do leading LLM developers possess a proprietary ``secret sauce'', or is LLM performance driven by scaling up compute? Using training and benchmark data for 809 models released between 2022 and 2025, we estimate scaling-law regressions with release-date and developer fixed effects. We find clear evidence of developer-specific efficiency advantages, but their importance depends on where models lie in the performance distribution. At the frontier, 80-90% of performance differences are explained by higher training compute, implying that scale--not proprietary technology--drives frontier advances. Away from the frontier, however, proprietary techniques and shared algorithmic progress substantially reduce the compute required to reach fixed capability thresholds. Some companies can systematically produce smaller models more efficiently. Strikingly, we also find substantial variation of model efficiency within companies; a firm can train two models with more than 40x compute efficiency difference. We also discuss the implications for AI leadership and capability diffusion.