Multimodal Enhancement of Sequential Recommendation
作者: Bucher Sahyouni, Matthew Vowels, Liqun Chen, Simon Hadfield
分类: cs.IR, cs.AI
发布日期: 2026-02-06
💡 一句话要点
提出MuSTRec,融合多模态信息与序列推荐,提升推荐性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列推荐 多模态融合 图神经网络 自注意力机制 推荐系统 用户行为建模 物品表示学习
📋 核心要点
- 现有推荐方法难以同时有效利用多模态信息和用户行为序列,限制了推荐的准确性。
- MuSTRec通过构建物品-物品图来融合文本和视觉特征,并利用频率自注意力捕获用户偏好。
- 实验表明,MuSTRec在多个亚马逊数据集上显著优于现有方法,最高提升达33.5%。
📝 摘要(中文)
我们提出了一种新颖的推荐框架MuSTRec(基于多模态和序列Transformer的推荐),它统一了多模态和序列推荐范式。MuSTRec通过从提取的文本和视觉特征构建物品-物品图,来捕获跨物品相似性和协同过滤信号。一个基于频率的自注意力模块额外捕获了用户的短期和长期偏好。在多个亚马逊数据集上,MuSTRec展示了优于多模态和序列最先进基线的卓越性能(高达33.5%的提升)。最后,我们详细介绍了这种新推荐范式的一些有趣方面。这些方面包括对新的数据划分机制的需求,以及展示了将用户嵌入集成到序列推荐中如何在较小的数据集上大幅提高短期指标(高达200%的提升)。我们的代码可在https://anonymous.4open.science/r/MuSTRec-D32B/ 获取,并将公开发布。
🔬 方法详解
问题定义:现有序列推荐方法通常只考虑用户历史行为序列,忽略了物品本身的多模态信息(如文本描述和图像)。而多模态推荐方法则缺乏对用户行为序列的建模能力。因此,如何有效地融合多模态信息和序列信息,以提升推荐系统的性能,是一个重要的挑战。
核心思路:MuSTRec的核心思路是将物品的多模态特征(文本和视觉)融入到序列推荐模型中。通过构建物品-物品图,利用图神经网络学习物品之间的关系,从而增强序列推荐模型对物品相似性的理解。同时,利用频率自注意力机制,捕捉用户在不同时间尺度上的偏好。
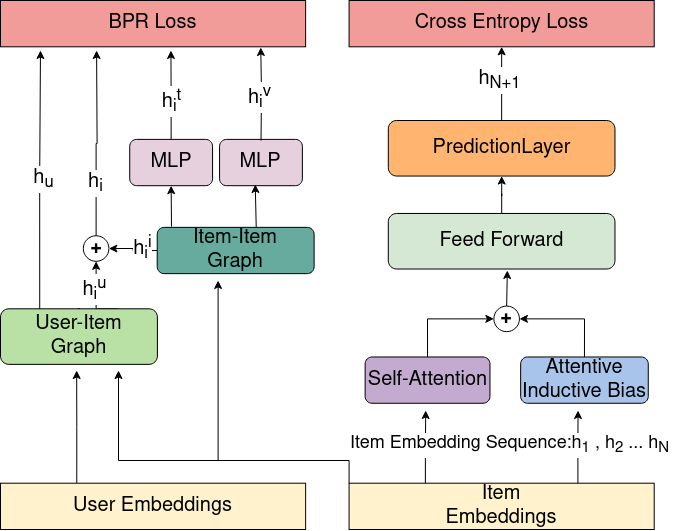
技术框架:MuSTRec的整体框架包括以下几个主要模块:1) 多模态特征提取模块:提取物品的文本和视觉特征。2) 物品-物品图构建模块:基于提取的特征构建物品-物品图。3) 图神经网络模块:利用图神经网络学习物品的表示。4) 序列建模模块:使用Transformer结构对用户行为序列进行建模,并融入物品的表示。5) 频率自注意力模块:根据用户行为的频率调整注意力权重。
关键创新:MuSTRec的关键创新在于:1) 提出了一个统一的多模态和序列推荐框架。2) 利用物品-物品图来增强序列推荐模型对物品相似性的理解。3) 引入频率自注意力机制,捕捉用户在不同时间尺度上的偏好。
关键设计:在多模态特征提取方面,可以使用预训练的文本和图像模型。物品-物品图的构建可以基于物品特征的相似度。频率自注意力模块的设计需要考虑不同频率的用户行为对推荐结果的影响。损失函数可以采用BPR损失或交叉熵损失。
🖼️ 关键图片

📊 实验亮点
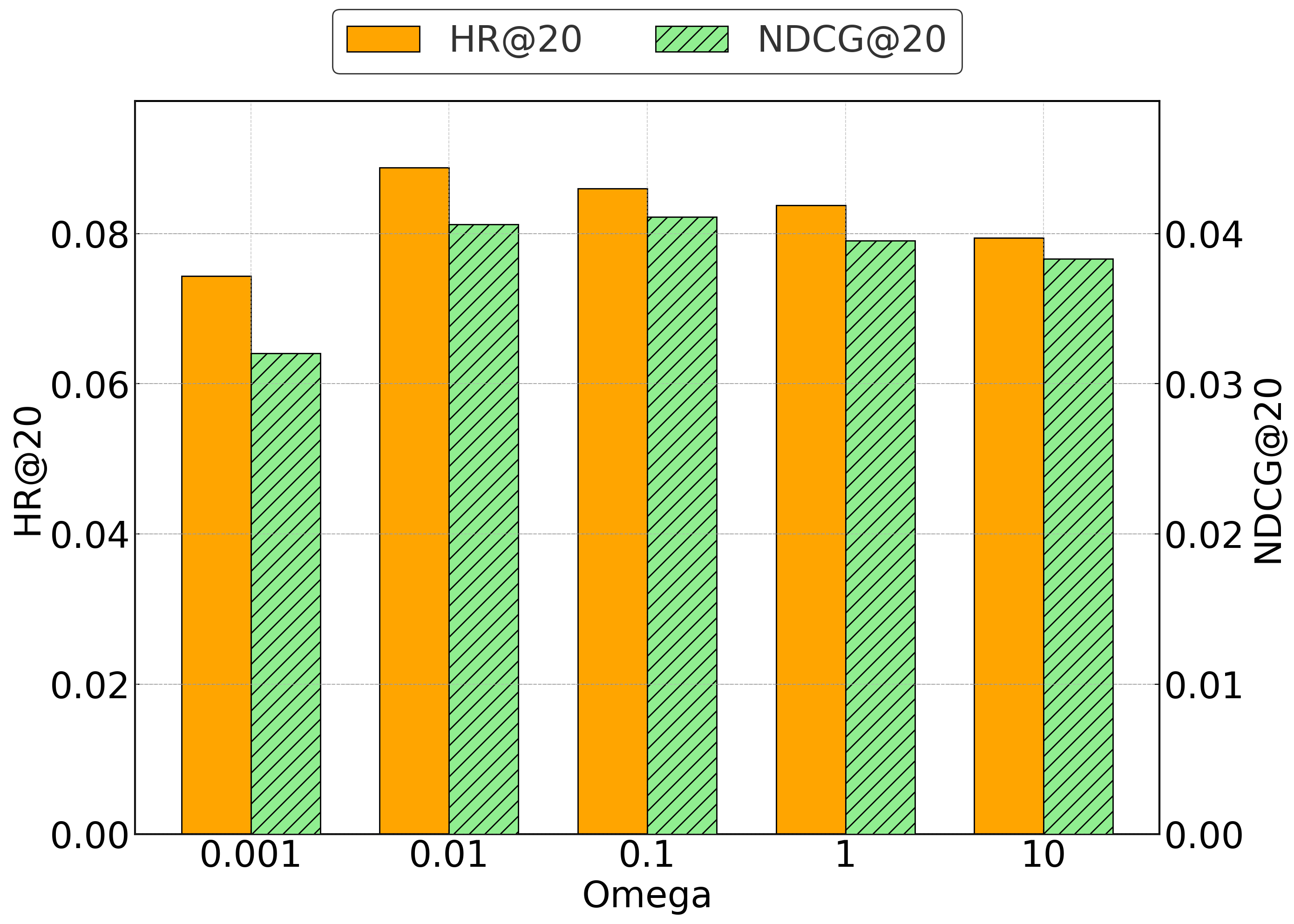
MuSTRec在多个亚马逊数据集上进行了评估,实验结果表明,MuSTRec显著优于现有的多模态和序列推荐方法,取得了高达33.5%的性能提升。此外,研究还发现,将用户嵌入集成到序列推荐中,可以在较小的数据集上大幅提高短期指标(高达200%的提升)。
🎯 应用场景
MuSTRec可应用于电商、视频推荐、新闻推荐等领域,通过融合物品的多模态信息和用户的行为序列,更准确地预测用户偏好,提升推荐系统的点击率、转化率等指标。该方法尤其适用于物品具有丰富多模态信息且用户行为序列较长的场景。
📄 摘要(原文)
We propose a novel recommender framework, MuSTRec (Multimodal and Sequential Transformer-based Recommendation), that unifies multimodal and sequential recommendation paradigms. MuSTRec captures cross-item similarities and collaborative filtering signals, by building item-item graphs from extracted text and visual features. A frequency-based self-attention module additionally captures the short- and long-term user preferences. Across multiple Amazon datasets, MuSTRec demonstrates superior performance (up to 33.5% improvement) over multimodal and sequential state-of-the-art baselines. Finally, we detail some interesting facets of this new recommendation paradigm. These include the need for a new data partitioning regime, and a demonstration of how integrating user embeddings into sequential recommendation leads to drastically increased short-term metrics (up to 200% improvement) on smaller datasets. Our code is availabe at https://anonymous.4open.science/r/MuSTRec-D32B/ and will be made publicly available.