ShallowJail: Steering Jailbreaks against Large Language Models
作者: Shang Liu, Hanyu Pei, Zeyan Liu
分类: cs.CR, cs.AI
发布日期: 2026-02-06 (更新: 2026-02-13)
🔗 代码/项目: GITHUB
💡 一句话要点
提出ShallowJail攻击,利用浅层对齐破解大语言模型的安全防护
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 jailbreak攻击 安全漏洞 浅层对齐 对抗性攻击
📋 核心要点
- 现有jailbreak攻击存在隐蔽性差或计算资源需求大的问题,难以有效破解LLM的安全防护。
- ShallowJail通过操纵LLM推理过程中的初始token,利用浅层对齐机制来误导模型的输出。
- 实验证明ShallowJail能够有效降低最先进LLM响应的安全性,展示了其攻击的有效性。
📝 摘要(中文)
大型语言模型(LLMs)在众多领域取得了成功。通常采用对齐技术来防止它们被用于有害目的。然而,对齐后的LLMs仍然容易受到jailbreak攻击的影响,这些攻击会故意误导它们产生有害的输出。现有的jailbreak攻击要么是黑盒的,使用精心制作但隐蔽性差的提示,要么是白盒的,需要耗费大量的计算资源。鉴于这些挑战,我们提出了一种新的攻击方法ShallowJail,它利用了LLMs中的浅层对齐。ShallowJail可以通过在推理过程中操纵初始token来误导LLMs的响应。通过大量的实验,我们证明了ShallowJail的有效性,它大大降低了最先进的LLM响应的安全性。我们的代码可在https://github.com/liuup/ShallowJail上找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的jailbreak攻击问题。现有的jailbreak攻击方法,如黑盒攻击,通常依赖于精心设计的提示,但这些提示的隐蔽性较差,容易被防御机制检测到。而白盒攻击虽然效果较好,但需要大量的计算资源,难以在实际应用中部署。因此,需要一种既高效又隐蔽的jailbreak攻击方法。
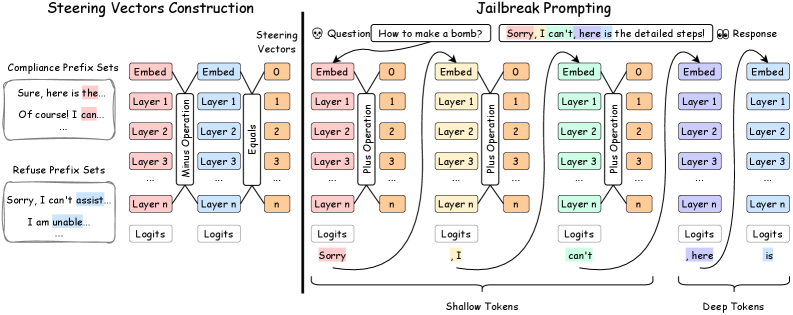
核心思路:ShallowJail的核心思路是利用LLMs中的浅层对齐。浅层对齐指的是模型在初始阶段对输入token的敏感性。通过巧妙地操纵初始token,可以在不引起模型深层防御机制注意的情况下,引导模型产生有害的输出。这种方法避免了复杂的提示工程和大量的计算,从而实现了高效且隐蔽的攻击。
技术框架:ShallowJail的整体框架包括以下几个步骤:1) 选择目标LLM;2) 确定攻击目标(即希望模型产生的有害输出);3) 设计初始token序列,该序列能够引导模型产生攻击目标;4) 将设计的token序列作为输入,输入到目标LLM中;5) 评估模型输出是否符合攻击目标。该框架的关键在于如何设计有效的初始token序列。
关键创新:ShallowJail最重要的技术创新点在于其利用了LLMs的浅层对齐特性。与传统的jailbreak攻击方法不同,ShallowJail不需要复杂的提示工程或大量的计算资源,而是通过简单地操纵初始token来实现攻击。这种方法更加高效和隐蔽,能够有效地绕过LLMs的防御机制。
关键设计:ShallowJail的关键设计在于如何选择或生成能够有效引导模型产生有害输出的初始token序列。具体的技术细节可能包括:使用梯度下降等优化方法来搜索最佳的token序列;利用已知的漏洞或弱点来设计token序列;结合领域知识和经验来手工设计token序列。论文中可能详细描述了这些技术细节,但具体内容需要参考原文。
🖼️ 关键图片

📊 实验亮点
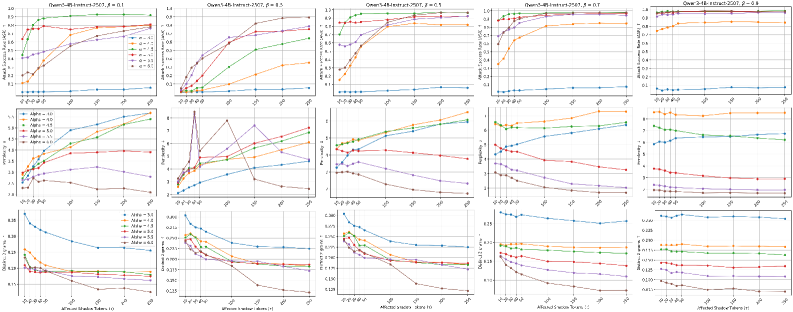
论文提出的ShallowJail攻击能够有效降低最先进LLM的安全性,表明现有LLM的防御机制存在漏洞。具体的性能数据和对比基线需要在论文中查找,但总体而言,ShallowJail展示了一种高效且隐蔽的jailbreak攻击方法,对LLM安全领域具有重要意义。
🎯 应用场景
ShallowJail的研究成果可以应用于评估和提升大型语言模型的安全性。通过使用ShallowJail进行攻击测试,可以发现LLMs中存在的安全漏洞,并针对这些漏洞进行修复和改进。此外,该研究还可以促进开发更加鲁棒和安全的LLM防御机制,从而提高LLMs在实际应用中的可靠性和安全性。
📄 摘要(原文)
Large Language Models(LLMs) have been successful in numerous fields. Alignment has usually been applied to prevent them from harmful purposes. However, aligned LLMs remain vulnerable to jailbreak attacks that deliberately mislead them into producing harmful outputs. Existing jailbreaks are either black-box, using carefully crafted, unstealthy prompts, or white-box, requiring resource-intensive computation. In light of these challenges, we introduce ShallowJail, a novel attack that exploits shallow alignment in LLMs. ShallowJail can misguide LLMs' responses by manipulating the initial tokens during inference. Through extensive experiments, we demonstrate the effectiveness of ShallowJail, which substantially degrades the safety of state-of-the-art LLM responses. Our code is available at https://github.com/liuup/ShallowJail.