Federated Prompt-Tuning with Heterogeneous and Incomplete Multimodal Client Data
作者: Thu Hang Phung, Duong M. Nguyen, Thanh Trung Huynh, Quoc Viet Hung Nguyen, Trong Nghia Hoang, Phi Le Nguyen
分类: cs.MM, cs.AI, cs.CV
发布日期: 2026-02-06
💡 一句话要点
提出异构不完全多模态联邦Prompt Tuning框架,解决跨客户端数据缺失和语义对齐问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 多模态学习 Prompt Tuning 异构数据 数据缺失 客户端调优 服务器聚合
📋 核心要点
- 现有联邦学习和多模态Prompt Tuning方法难以处理客户端数据异构和特征缺失问题。
- 提出一种新的联邦Prompt Tuning框架,通过客户端调优和服务器聚合实现跨客户端和模态的Prompt对齐。
- 在多个多模态数据集上验证,该方法显著优于现有技术,提升了模型性能。
📝 摘要(中文)
本文提出了一种通用的联邦Prompt Tuning框架,用于解决实际场景中本地数据集为多模态且在输入层面存在不同缺失特征分布模式的问题。该框架弥合了联邦学习和多模态Prompt Tuning之间的差距,而传统方法主要集中于单模态或中心化数据。此场景中的一个关键挑战是,缺乏Prompt指令之间的语义对齐,这些指令编码了不同客户端之间相似的缺失数据分布模式。为了解决这个问题,我们的框架引入了专门的客户端调优和服务器聚合设计,可以同时优化、对齐和聚合跨客户端和数据模态的Prompt Tuning指令。这使得Prompt指令能够相互补充并有效地组合。在各种多模态基准数据集上的大量评估表明,我们的工作始终优于最先进(SOTA)的基线。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,各个客户端拥有的数据是多模态的,并且不同客户端的数据可能缺失不同的模态特征的问题。现有方法通常假设数据是单模态的或者数据是完整的,无法直接应用于这种异构且不完整的数据场景。此外,直接应用Prompt Tuning到联邦学习中,由于各个客户端数据分布的差异,会导致Prompt指令之间语义不对齐,影响模型性能。
核心思路:论文的核心思路是通过专门设计的客户端调优和服务器聚合策略,来优化、对齐和聚合各个客户端的Prompt Tuning指令。通过这种方式,使得各个客户端的Prompt指令能够相互补充,从而提升整体模型的性能。核心在于解决不同客户端之间Prompt指令的语义对齐问题,使其能够有效融合。
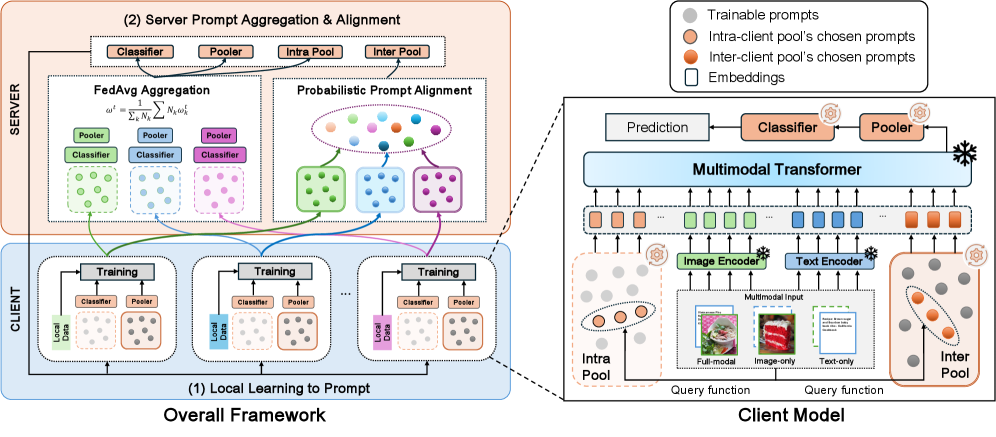
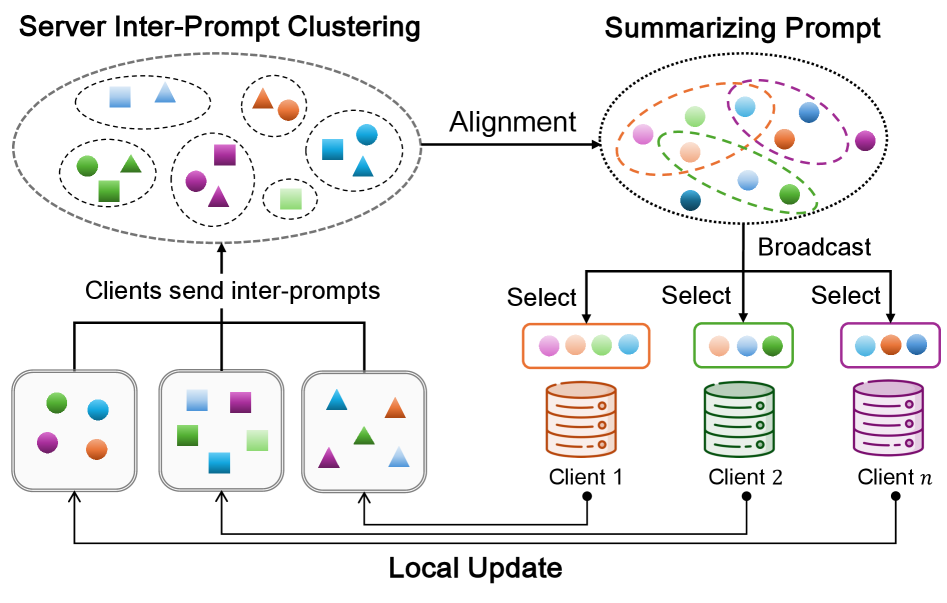
技术框架:整体框架包含客户端训练和服务器聚合两个主要阶段。在客户端训练阶段,每个客户端使用本地数据进行Prompt Tuning,并更新本地的Prompt指令。在服务器聚合阶段,服务器收集各个客户端的Prompt指令,并使用特定的聚合策略进行聚合,得到全局的Prompt指令。然后,服务器将全局Prompt指令发送给各个客户端,用于下一轮的训练。
关键创新:论文的关键创新在于提出了专门针对异构不完全多模态数据的联邦Prompt Tuning方法。该方法通过客户端调优和服务器聚合策略,实现了跨客户端和模态的Prompt指令对齐,解决了传统方法无法有效处理数据异构和缺失的问题。
关键设计:论文设计了特定的客户端调优策略,用于优化本地的Prompt指令。同时,论文还设计了服务器聚合策略,用于聚合各个客户端的Prompt指令。具体的参数设置、损失函数和网络结构等技术细节在论文中有详细描述,但此处未提供具体数值。
🖼️ 关键图片
📊 实验亮点
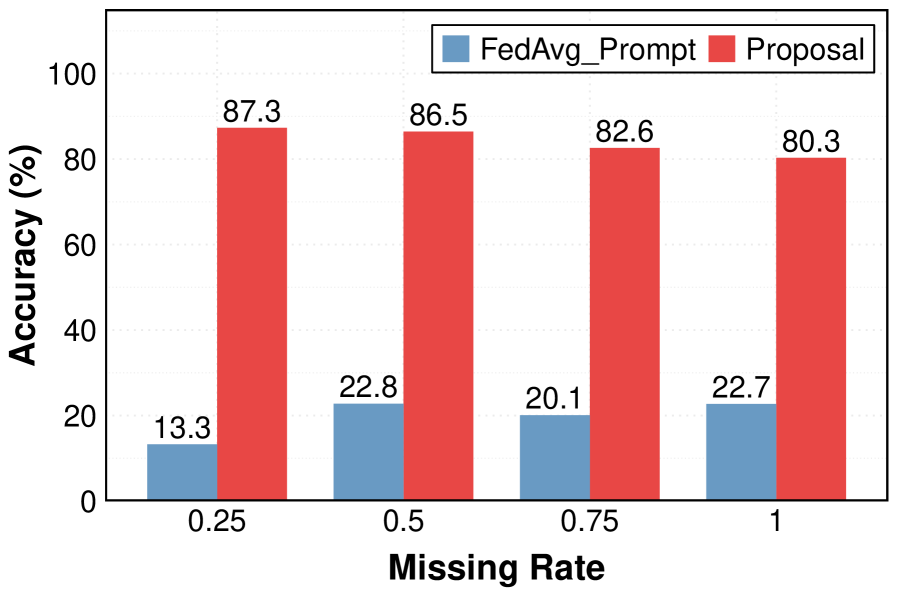
论文在多个多模态基准数据集上进行了实验,结果表明,所提出的方法始终优于最先进的基线方法。具体的性能提升幅度在论文中有详细的数值展示,但此处未提供具体数值。实验结果验证了该方法在处理异构不完全多模态数据联邦学习问题上的有效性。
🎯 应用场景
该研究成果可应用于医疗健康、自动驾驶、金融风控等领域。例如,在医疗健康领域,不同医院可能拥有不同模态的患者数据(如影像、文本、基因数据),且数据存在缺失。该方法可以有效利用这些异构不完整的数据,训练出更准确的疾病诊断模型。在自动驾驶领域,不同车辆可能配备不同的传感器,收集到的数据模态也不同。该方法可以用于融合这些异构数据,提升自动驾驶系统的感知能力。
📄 摘要(原文)
This paper introduces a generalized federated prompt-tuning framework for practical scenarios where local datasets are multi-modal and exhibit different distributional patterns of missing features at the input level. The proposed framework bridges the gap between federated learning and multi-modal prompt-tuning which have traditionally focused on either uni-modal or centralized data. A key challenge in this setting arises from the lack of semantic alignment between prompt instructions that encode similar distributional patterns of missing data across different clients. To address this, our framework introduces specialized client-tuning and server-aggregation designs that simultaneously optimize, align, and aggregate prompt-tuning instructions across clients and data modalities. This allows prompt instructions to complement one another and be combined effectively. Extensive evaluations on diverse multimodal benchmark datasets demonstrate that our work consistently outperforms state-of-the-art (SOTA) baselines.