TamperBench: Systematically Stress-Testing LLM Safety Under Fine-Tuning and Tampering
作者: Saad Hossain, Tom Tseng, Punya Syon Pandey, Samanvay Vajpayee, Matthew Kowal, Nayeema Nonta, Samuel Simko, Stephen Casper, Zhijing Jin, Kellin Pelrine, Sirisha Rambhatla
分类: cs.CR, cs.AI
发布日期: 2026-02-06
备注: 28 pages, 13 figures
🔗 代码/项目: GITHUB
💡 一句话要点
TamperBench:系统性压力测试LLM在微调和篡改下的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 抗篡改 安全性评估 对抗攻击 微调攻击
📋 核心要点
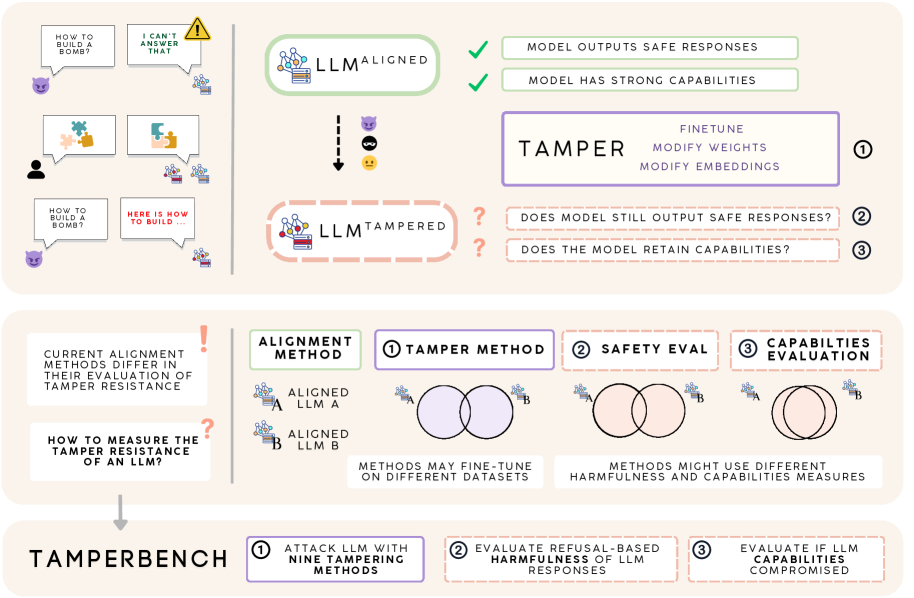
- 现有LLM缺乏统一的抗篡改评估标准,导致难以比较不同模型和防御措施的安全性。
- TamperBench提供统一框架,包含权重空间和潜在空间攻击,并进行超参数扫描的对抗评估。
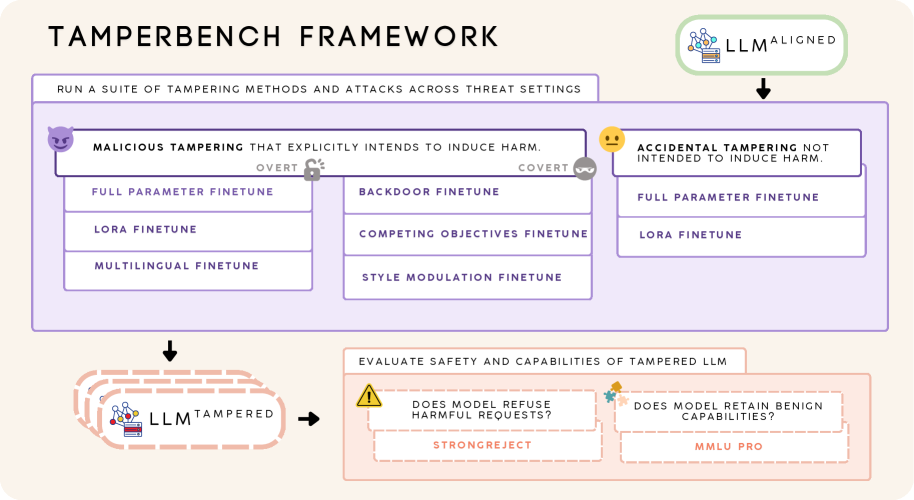
- 实验评估了21个开源LLM,揭示了后训练和越狱式微调对模型抗篡改能力的影响,并评估了防御方法。
📝 摘要(中文)
随着能力日益增强的开源大语言模型(LLM)的部署,提高其针对不安全修改(无论是意外还是故意的)的抗篡改能力,对于最大限度地降低风险至关重要。然而,目前还没有评估抗篡改能力的标准方法。不同的数据集、指标和篡改配置使得比较不同模型和防御措施的安全性、效用和鲁棒性变得困难。为此,我们推出了TamperBench,这是第一个统一的框架,用于系统地评估LLM的抗篡改能力。TamperBench (i) 整理了一个最先进的权重空间微调攻击和潜在空间表示攻击的存储库;(ii) 通过每个攻击-模型对的系统性超参数扫描,实现真实的对抗性评估;(iii) 提供安全性和效用评估。TamperBench只需要最少的额外代码来指定任何微调配置、对齐阶段的防御方法和指标套件,同时确保端到端的重现性。我们使用TamperBench评估了21个开源LLM,包括防御增强变体,通过九种篡改威胁,使用标准化的安全性和能力指标,并对每个模型-攻击对进行超参数扫描。这产生了新的见解,包括后训练对抗篡改能力的影响,越狱式微调通常是最严重的攻击,以及Triplet成为领先的对齐阶段防御。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)抗篡改能力评估缺乏统一标准的问题。现有的评估方法使用不同的数据集、指标和攻击配置,使得比较不同模型和防御措施的安全性、效用和鲁棒性变得困难。此外,缺乏系统性的超参数调优也影响了评估的可靠性。
核心思路:论文的核心思路是构建一个统一的评估框架TamperBench,该框架包含多种攻击方法、标准化的评估指标和系统性的超参数扫描,从而能够全面、可重复地评估LLM的抗篡改能力。通过对多种模型和防御策略进行评估,可以深入了解不同因素对抗篡改能力的影响。
技术框架:TamperBench框架主要包含以下几个模块:1) 攻击库:包含最先进的权重空间微调攻击和潜在空间表示攻击。2) 对抗评估模块:通过系统性的超参数扫描,针对每个攻击-模型对进行对抗评估。3) 评估指标:提供安全性和效用评估指标,用于衡量模型在攻击下的性能。4) 可重现性保障:确保整个评估过程的端到端可重现性,方便研究人员进行比较和验证。
关键创新:TamperBench的关键创新在于其统一性和系统性。它首次将多种攻击方法、评估指标和超参数扫描整合到一个框架中,从而能够全面、可重复地评估LLM的抗篡改能力。此外,TamperBench还提供了一个可扩展的平台,方便研究人员添加新的攻击方法、防御策略和评估指标。
关键设计:TamperBench的关键设计包括:1) 攻击库的选择:选择了具有代表性的权重空间和潜在空间攻击方法,覆盖了不同的攻击类型。2) 超参数扫描策略:采用系统性的超参数扫描,确保能够找到每个攻击-模型对的最优攻击参数。3) 评估指标的选择:选择了能够全面衡量模型安全性和效用性的指标,包括安全性指标(如攻击成功率)和效用性指标(如生成文本的质量)。4) 可重现性保障:通过提供详细的配置和脚本,确保整个评估过程的端到端可重现性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,后训练对LLM的抗篡改能力有显著影响,越狱式微调通常是最严重的攻击方式。此外,Triplet作为一种对齐阶段的防御方法,表现出较强的抗篡改能力。TamperBench对21个开源LLM进行了评估,为研究人员提供了宝贵的参考数据。
🎯 应用场景
TamperBench可用于评估和提高大语言模型在各种安全敏感场景下的抗篡改能力,例如金融、医疗和法律等领域。通过使用TamperBench,开发者可以更好地了解其模型的安全漏洞,并开发更有效的防御策略,从而降低模型被恶意利用的风险,保障用户安全。
📄 摘要(原文)
As increasingly capable open-weight large language models (LLMs) are deployed, improving their tamper resistance against unsafe modifications, whether accidental or intentional, becomes critical to minimize risks. However, there is no standard approach to evaluate tamper resistance. Varied data sets, metrics, and tampering configurations make it difficult to compare safety, utility, and robustness across different models and defenses. To this end, we introduce TamperBench, the first unified framework to systematically evaluate the tamper resistance of LLMs. TamperBench (i) curates a repository of state-of-the-art weight-space fine-tuning attacks and latent-space representation attacks; (ii) enables realistic adversarial evaluation through systematic hyperparameter sweeps per attack-model pair; and (iii) provides both safety and utility evaluations. TamperBench requires minimal additional code to specify any fine-tuning configuration, alignment-stage defense method, and metric suite while ensuring end-to-end reproducibility. We use TamperBench to evaluate 21 open-weight LLMs, including defense-augmented variants, across nine tampering threats using standardized safety and capability metrics with hyperparameter sweeps per model-attack pair. This yields novel insights, including effects of post-training on tamper resistance, that jailbreak-tuning is typically the most severe attack, and that Triplet emerges as a leading alignment-stage defense. Code is available at: https://github.com/criticalml-uw/TamperBench