TraceCoder: A Trace-Driven Multi-Agent Framework for Automated Debugging of LLM-Generated Code
作者: Jiangping Huang, Wenguang Ye, Weisong Sun, Jian Zhang, Mingyue Zhang, Yang Liu
分类: cs.SE, cs.AI
发布日期: 2026-02-06
💡 一句话要点
TraceCoder:基于运行时追踪的多智能体框架,用于自动调试LLM生成的代码
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码调试 大型语言模型 运行时追踪 因果分析 多智能体系统 历史经验学习 自动修复
📋 核心要点
- 现有LLM代码调试方法依赖于简单的pass/fail信号,缺乏对程序内部行为的深入理解,难以精确定位错误。
- TraceCoder通过运行时追踪捕获细粒度程序行为,结合因果分析和历史经验学习,实现更精确和高效的自动调试。
- 实验表明,TraceCoder在Pass@1准确率上显著优于现有方法,迭代修复过程本身贡献了高达65.61%的相对增益。
📝 摘要(中文)
大型语言模型(LLMs)生成的代码通常包含细微但关键的错误,尤其是在处理复杂任务时。现有的自动修复方法通常依赖于表面的通过/失败信号,对程序行为的可见性有限,阻碍了精确的错误定位。此外,由于缺乏从先前失败中学习的机制,修复过程常常陷入重复且低效的循环。为了克服这些挑战,我们提出了TraceCoder,一个协作式多智能体框架,它模拟了人类专家的观察-分析-修复过程。该框架首先使用诊断探针来检测代码,以捕获细粒度的运行时追踪,从而深入了解其内部执行情况。然后,它对这些追踪进行因果分析,以准确识别失败的根本原因。通过一种新颖的历史经验学习机制(HLLM)进一步增强了这一过程,该机制从先前失败的修复尝试中提取见解,为后续的纠正策略提供信息,并防止类似错误的再次发生。为了确保稳定的收敛,回滚机制强制每次修复迭代都构成朝着正确解决方案的严格改进。在多个基准测试中进行的全面实验表明,TraceCoder在Pass@1准确率方面比现有的先进基线提高了高达34.43%。消融研究验证了每个系统组件的重要性,仅迭代修复过程就贡献了65.61%的相对准确率增益。此外,TraceCoder在准确性和成本效率方面均显着优于领先的迭代方法。
🔬 方法详解
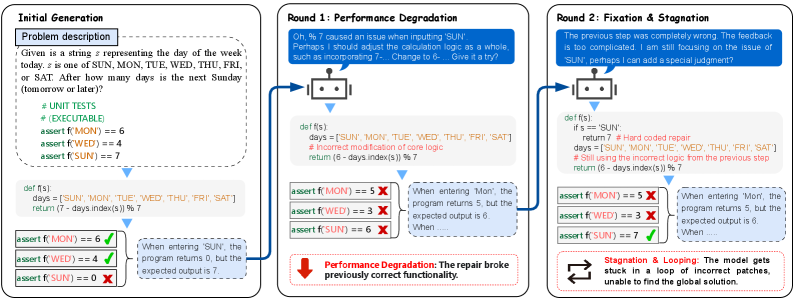
问题定义:论文旨在解决LLM生成代码中存在的难以调试的bug问题。现有方法主要依赖于简单的测试用例结果(pass/fail)作为反馈信号,缺乏对程序运行时状态的深入理解,导致错误定位困难,修复效率低下。此外,现有方法通常缺乏从历史调试经验中学习的能力,容易陷入重复的错误修复循环。
核心思路:TraceCoder的核心思路是模拟人类专家调试代码的过程,即“观察-分析-修复”。通过在代码中插入探针来观察程序的运行时状态(trace),然后对trace进行因果分析以定位错误根源,最后基于分析结果进行代码修复。同时,引入历史经验学习机制,从之前的失败修复尝试中学习,避免重复犯错。
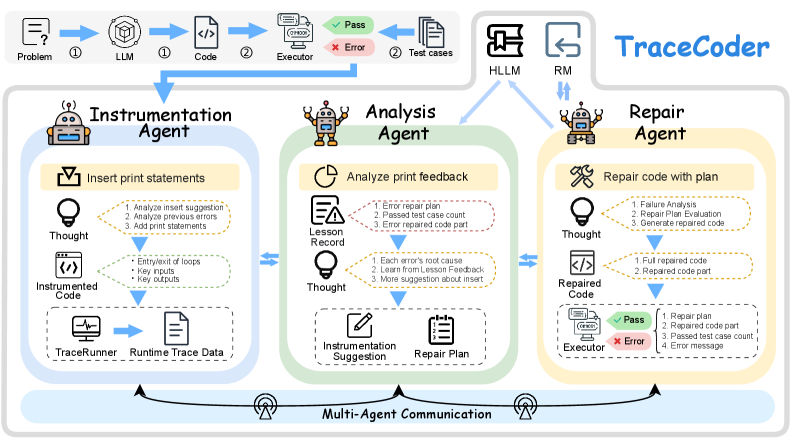
技术框架:TraceCoder是一个多智能体协作框架,包含以下主要模块:1) 代码插桩模块:在LLM生成的代码中插入诊断探针,用于收集运行时trace。2) 运行时追踪模块:执行插桩后的代码,收集细粒度的运行时trace信息。3) 因果分析模块:分析运行时trace,定位导致程序错误的根本原因。4) 代码修复模块:基于因果分析结果,对代码进行修复。5) 历史经验学习模块(HLLM):从之前的失败修复尝试中学习,为后续的修复策略提供指导。6) 回滚机制:确保每次修复迭代都朝着正确的方向前进。
关键创新:TraceCoder的关键创新在于:1) 基于运行时trace的细粒度错误定位:通过收集和分析程序的运行时trace,可以更精确地定位错误根源,克服了传统方法仅依赖pass/fail信号的局限性。2) 历史经验学习机制(HLLM):通过从之前的失败修复尝试中学习,可以避免重复犯错,提高修复效率。3) 多智能体协作框架:将调试过程分解为多个模块,每个模块由一个智能体负责,通过协作完成整个调试任务。
关键设计:HLLM模块的设计是关键。它维护一个历史修复经验库,记录每次修复尝试的trace、因果分析结果和修复方案。当遇到新的错误时,HLLM会检索经验库,寻找相似的错误和对应的修复方案,为当前的修复提供指导。回滚机制的设计也至关重要,它确保每次修复迭代都必须带来性能提升,避免陷入局部最优解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TraceCoder在多个基准测试中均取得了显著的性能提升。在Pass@1准确率方面,TraceCoder比现有的先进基线提高了高达34.43%。消融实验验证了各个模块的有效性,其中迭代修复过程本身贡献了65.61%的相对准确率增益。此外,TraceCoder在准确性和成本效率方面均优于领先的迭代方法。
🎯 应用场景
TraceCoder可应用于各种需要自动调试代码的场景,例如自动化软件开发、AI辅助编程、在线编程教育等。它可以显著提高代码调试效率,降低开发成本,并帮助开发者更快地发现和修复代码中的错误。未来,该技术有望与LLM代码生成工具集成,实现更智能、更高效的软件开发流程。
📄 摘要(原文)
Large Language Models (LLMs) often generate code with subtle but critical bugs, especially for complex tasks. Existing automated repair methods typically rely on superficial pass/fail signals, offering limited visibility into program behavior and hindering precise error localization. In addition, without a way to learn from prior failures, repair processes often fall into repetitive and inefficient cycles. To overcome these challenges, we present TraceCoder, a collaborative multi-agent framework that emulates the observe-analyze-repair process of human experts. The framework first instruments the code with diagnostic probes to capture fine-grained runtime traces, enabling deep insight into its internal execution. It then conducts causal analysis on these traces to accurately identify the root cause of the failure. This process is further enhanced by a novel Historical Lesson Learning Mechanism (HLLM), which distills insights from prior failed repair attempts to inform subsequent correction strategies and prevent recurrence of similar mistakes. To ensure stable convergence, a Rollback Mechanism enforces that each repair iteration constitutes a strict improvement toward the correct solution. Comprehensive experiments across multiple benchmarks show that TraceCoder achieves up to a 34.43\% relative improvement in Pass@1 accuracy over existing advanced baselines. Ablation studies verify the significance of each system component, with the iterative repair process alone contributing a 65.61\% relative gain in accuracy. Furthermore, TraceCoder significantly outperforms leading iterative methods in terms of both accuracy and cost-efficiency.