The Quantum Sieve Tracer: A Hybrid Framework for Layer-Wise Activation Tracing in Large Language Models
作者: Jonathan Pan
分类: quant-ph, cs.AI
发布日期: 2026-02-06
备注: 4 pages, 4 figures
💡 一句话要点
提出量子筛追踪器,用于分析大语言模型中的逐层激活追踪,揭示模型架构差异。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 因果追踪 量子计算 注意力机制 事实回忆 量子核
📋 核心要点
- 机械可解释性的目标是逆向工程大语言模型的内部计算,但从高维多义噪声中分离出稀疏的语义信号仍然是一个重大挑战。
- 论文提出量子筛追踪器,这是一个混合量子-经典框架,通过将注意力头激活映射到量子希尔伯特空间,来分析事实回忆回路。
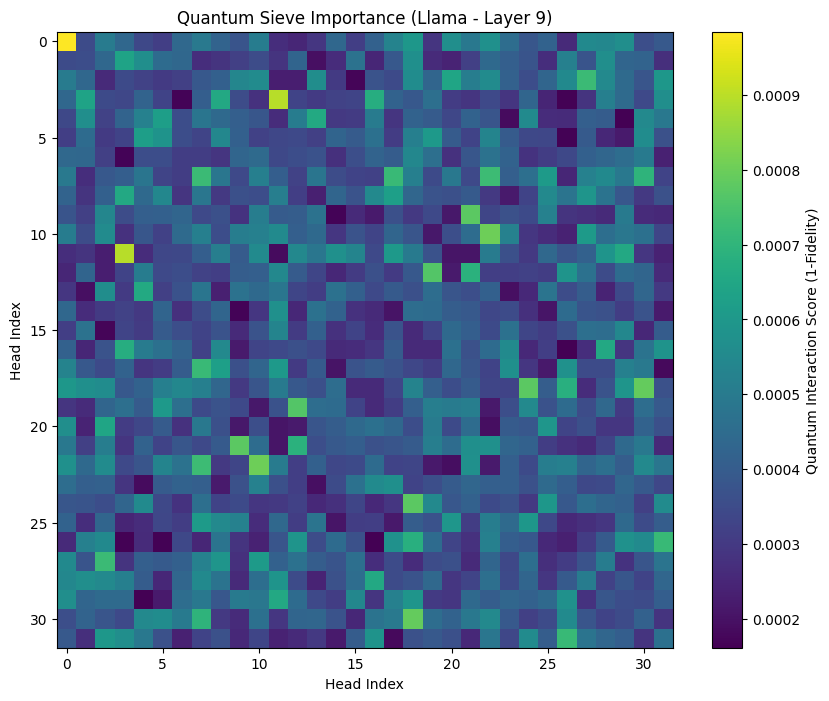
- 实验结果表明,该方法能够区分不同模型架构中构建性(回忆)和还原性(抑制)机制,并发现Llama模型中存在干扰抑制回路。
📝 摘要(中文)
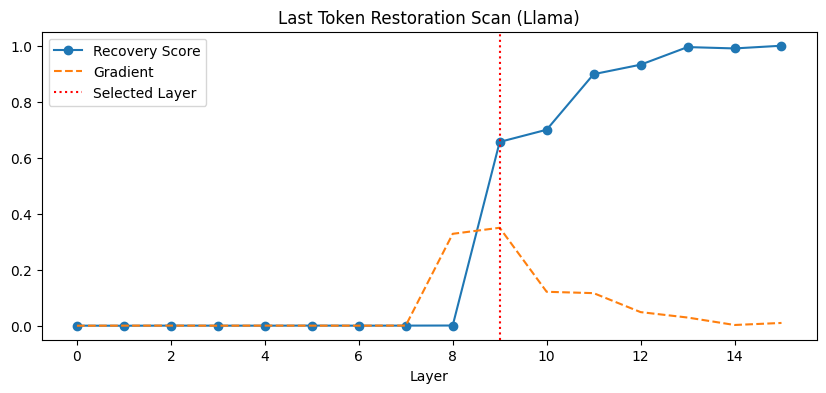
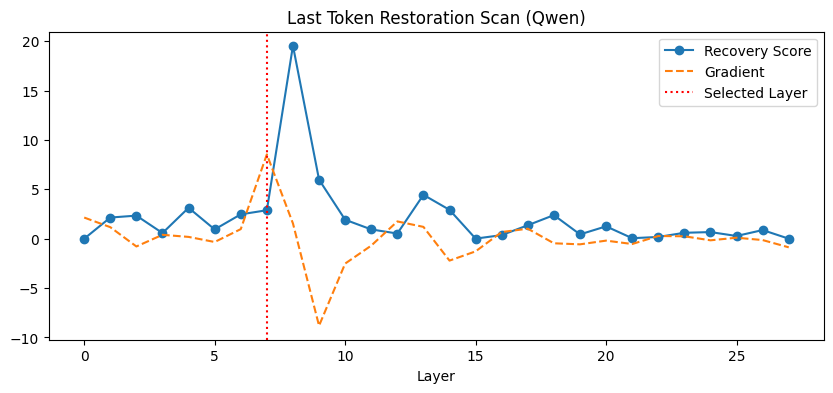
本文提出了一种混合量子-经典框架——量子筛追踪器,旨在表征大语言模型(LLM)中的事实回忆回路。该框架首先使用经典因果追踪定位关键层,然后将特定的注意力头激活映射到指数级的量子希尔伯特空间中。通过对开源模型(Meta Llama-3.2-1B和阿里巴巴Qwen2.5-1.5B-Instruct)进行两阶段分析,揭示了两种模型架构的根本差异。研究发现,Qwen的第7层回路类似于经典的回忆中心,而Llama的第9层则充当干扰抑制回路,消融识别出的注意力头反而能提高事实回忆效果。实验结果表明,量子核能够区分构建性(回忆)和还原性(抑制)机制,为分析注意力机制的细粒度拓扑结构提供了一种高分辨率工具。
🔬 方法详解
问题定义:大语言模型的可解释性研究面临着从高维、多义的噪声中提取稀疏语义信号的挑战。现有的因果追踪方法虽然可以定位关键层,但难以区分不同类型的注意力机制,例如回忆机制和抑制机制。因此,需要一种更精细的分析工具来理解模型内部的计算过程。
核心思路:论文的核心思路是将注意力头的激活映射到量子希尔伯特空间,利用量子核来区分不同类型的注意力机制。量子希尔伯特空间具有指数级的维度,可以捕捉到更细微的激活模式。通过分析量子核的性质,可以区分构建性(回忆)和还原性(抑制)机制。
技术框架:量子筛追踪器包含两个主要阶段:1) 经典因果追踪:使用经典的因果追踪方法定位对事实回忆至关重要的层。2) 量子核分析:将关键层的注意力头激活映射到量子希尔伯特空间,并计算量子核。通过分析量子核的特征值和特征向量,可以区分不同类型的注意力机制。
关键创新:该方法最重要的创新点在于将量子计算的思想引入到大语言模型的可解释性研究中。通过使用量子核,可以捕捉到传统方法难以发现的细微激活模式,从而更深入地理解模型的内部计算过程。此外,该方法能够区分构建性(回忆)和还原性(抑制)机制,为理解模型的行为提供了新的视角。
关键设计:论文使用了特定的量子核函数,例如高斯核或线性核,来计算注意力头激活之间的相似度。此外,论文还设计了一种两阶段分析流程,首先使用经典方法定位关键层,然后使用量子方法进行精细分析。这种混合方法可以充分利用经典方法和量子方法的优势。
🖼️ 关键图片
📊 实验亮点
实验结果表明,量子筛追踪器能够成功区分Llama和Qwen两种模型架构中不同的注意力机制。具体来说,Qwen的第7层回路类似于经典的回忆中心,而Llama的第9层则充当干扰抑制回路,消融识别出的注意力头反而能提高事实回忆效果。这些发现表明,量子核能够捕捉到传统方法难以发现的细微激活模式。
🎯 应用场景
该研究成果可应用于大语言模型的安全性和可靠性评估,例如识别模型中存在的潜在偏见或漏洞。此外,该方法还可以用于指导模型的设计和优化,例如通过调整注意力机制来提高模型的性能。未来,该方法有望推广到其他类型的神经网络,并为人工智能的可解释性研究提供新的思路。
📄 摘要(原文)
Mechanistic interpretability aims to reverse-engineer the internal computations of Large Language Models (LLMs), yet separating sparse semantic signals from high-dimensional polysemantic noise remains a significant challenge. This paper introduces the Quantum Sieve Tracer, a hybrid quantum-classical framework designed to characterize factual recall circuits. We implement a modular pipeline that first localizes critical layers using classical causal tracing, then maps specific attention head activations into an exponentially large quantum Hilbert space. Using open-weight models (Meta Llama-3.2-1B and Alibaba Qwen2.5-1.5B-Instruct), we perform a two-stage analysis that reveals a fundamental architectural divergence. While Qwen's layer 7 circuit functions as a classic Recall Hub, we discover that Llama's layer 9 acts as an Interference Suppression circuit, where ablating the identified heads paradoxically improves factual recall. Our results demonstrate that quantum kernels can distinguish between these constructive (recall) and reductive (suppression) mechanisms, offering a high-resolution tool for analyzing the fine-grained topology of attention.