POP: Online Structural Pruning Enables Efficient Inference of Large Foundation Models
作者: Yi Chen, Wonjin Shin, Shuhong Liu, Tho Mai, Jeongmo Lee, Chuanbo Hua, Kun Wang, Jun Liu, Joo-Young Kim
分类: cs.AI
发布日期: 2026-02-06
💡 一句话要点
POP:在线结构剪枝实现大模型高效推理,兼顾精度与速度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线剪枝 结构剪枝 大型模型 动态剪枝 模型压缩
📋 核心要点
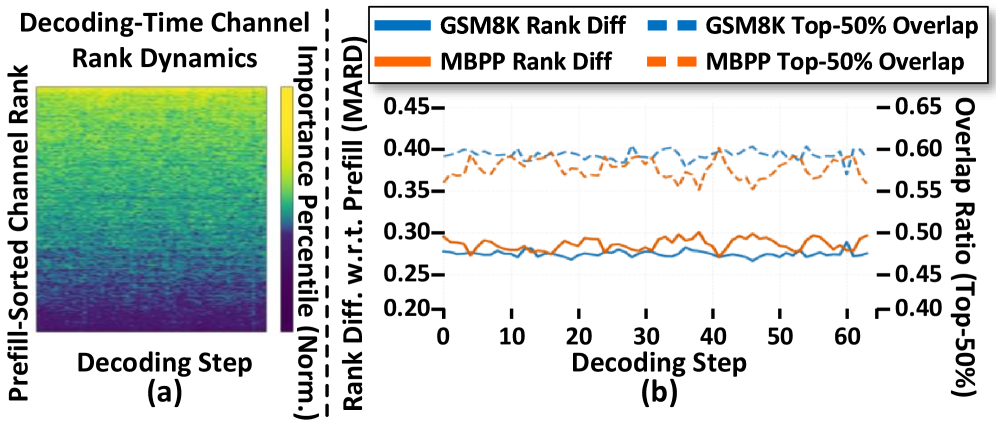
- 现有结构剪枝方法在推理时采用固定剪枝策略,忽略了自回归生成过程中动态变化的稀疏性。
- POP框架通过分区引导的在线剪枝,在预填充阶段进行粗略剪枝,解码阶段进行细粒度掩码,实现上下文相关的动态剪枝。
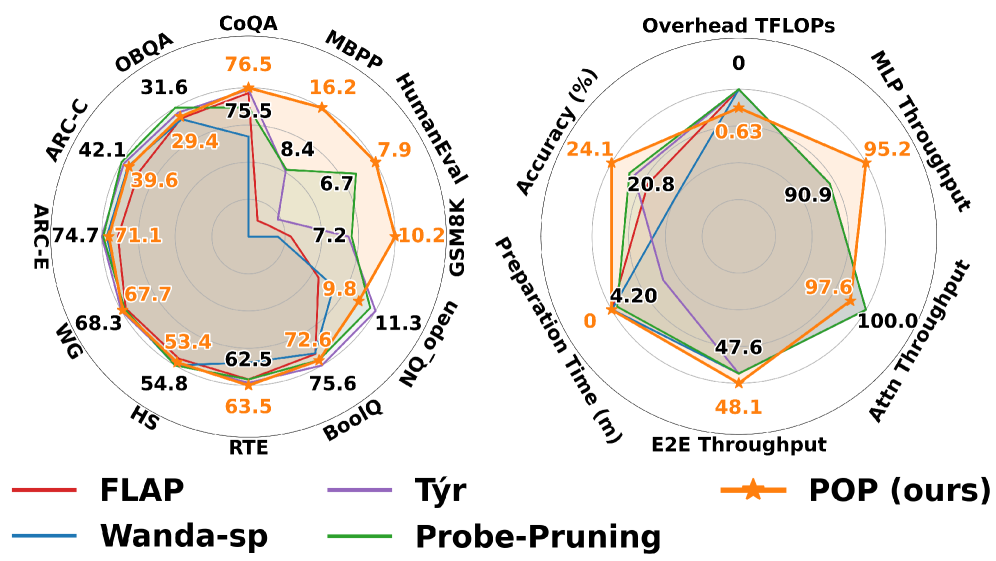
- 实验表明,POP在多种大型模型上优于现有剪枝方法,实现了更高的精度、更低的计算开销和更小的推理延迟。
📝 摘要(中文)
大型基础模型(LFMs)通过扩展规模实现了强大的性能,但现有的结构剪枝方法在推理过程中采用固定的剪枝决策,忽略了自回归token生成中涌现的稀疏模式。本文提出了一种高效的在线结构剪枝框架POP(Partition-guided Online Pruning),它能够以最小的计算开销实现上下文相关的动态剪枝。POP将模型通道划分为保留区域、候选区域和剪枝区域,其中预填充阶段定义了一个粗略的剪枝分区,解码阶段在候选区域内生成细粒度的掩码,避免了全通道的重新评估。粗略的剪枝分区保留了始终重要的权重,而细粒度的掩码提供了解码过程中上下文相关的变化。此外,POP是一种轻量级的、即插即用的方法,不需要预处理,包括离线校准、重新训练或学习预测器。在包括大型语言模型(LLMs)、混合专家模型(MoEs)和视觉语言模型(VLMs)在内的各种LFMs上的广泛评估表明,POP始终比现有的剪枝方法提供更高的准确性,同时产生更小的计算开销并最大限度地减少推理延迟。
🔬 方法详解
问题定义:现有的大型模型剪枝方法通常采用静态剪枝策略,即在推理过程中,模型的结构和参数是固定的。这种方法忽略了在自回归生成任务中,不同上下文对模型参数的重要性是不同的,导致了次优的剪枝效果。静态剪枝无法适应模型在不同输入下的动态变化,限制了模型压缩的潜力。
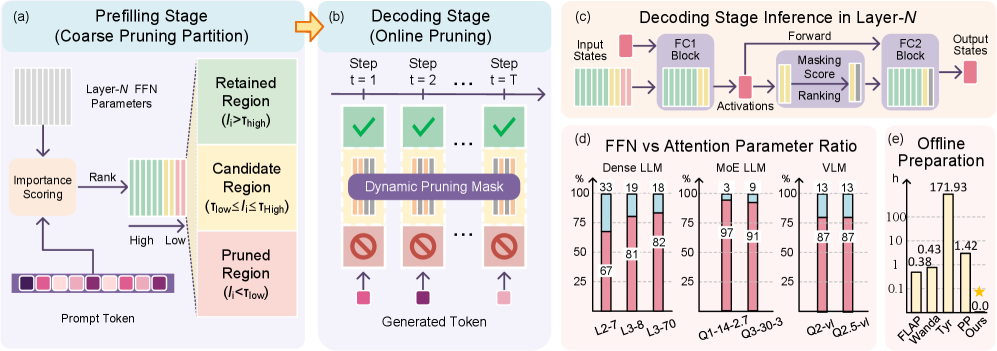
核心思路:POP的核心思路是利用在线剪枝,根据当前的上下文动态地调整模型的结构。具体来说,POP将模型的通道划分为三个区域:保留区域、候选区域和剪枝区域。保留区域包含始终重要的权重,候选区域包含可能重要的权重,剪枝区域包含不重要的权重。通过在候选区域进行细粒度的掩码操作,POP可以根据上下文动态地选择哪些通道参与计算,从而实现高效的推理。
技术框架:POP框架主要包含两个阶段:预填充(prefilling)阶段和解码(decoding)阶段。在预填充阶段,POP通过分析输入数据,确定一个粗略的剪枝分区,将模型通道划分为保留区域、候选区域和剪枝区域。在解码阶段,POP在候选区域内生成细粒度的掩码,根据上下文动态地选择哪些通道参与计算。整个过程无需离线校准、重新训练或学习预测器,即插即用。
关键创新:POP的关键创新在于其在线剪枝策略和分区引导机制。与传统的静态剪枝方法不同,POP能够根据上下文动态地调整模型的结构,从而更好地适应不同的输入。分区引导机制通过将模型通道划分为不同的区域,有效地减少了需要重新评估的通道数量,降低了计算开销。
关键设计:POP的关键设计包括:1) 通道分区策略:如何有效地将模型通道划分为保留区域、候选区域和剪枝区域。2) 掩码生成策略:如何在候选区域内生成细粒度的掩码,以实现上下文相关的动态剪枝。3) 计算开销控制:如何在保证精度的前提下,最大限度地减少在线剪枝带来的计算开销。论文中具体的分区和掩码生成策略细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,POP在多种大型模型(包括LLMs、MoEs和VLMs)上都取得了显著的性能提升。与现有的剪枝方法相比,POP在保持或提高精度的同时,显著降低了计算开销和推理延迟。具体的性能数据和提升幅度在论文中进行了详细的展示,但这里无法给出具体数值。
🎯 应用场景
POP框架可广泛应用于各种大型基础模型的部署和推理加速,尤其是在资源受限的边缘设备上。通过动态调整模型结构,POP能够在保证精度的前提下,显著降低计算开销和推理延迟,从而使得大型模型能够在更多场景下得到应用。例如,在移动设备上运行大型语言模型,或者在自动驾驶系统中部署视觉语言模型。
📄 摘要(原文)
Large foundation models (LFMs) achieve strong performance through scaling, yet current structural pruning methods derive fixed pruning decisions during inference, overlooking sparsity patterns that emerge in the autoregressive token generation. In this paper, we propose POP (Partition-guided Online Pruning), an efficient online structural pruning framework that enables context-conditioned dynamic pruning with minimal computational overhead. POP partitions model channels into retained, candidate, and pruned regions, where prefilling defines a coarse pruning partition, and the decoding stage generates a fine-grained mask within the candidate region, avoiding full-channel re-evaluation. The coarse pruning partition preserves consistently important weights, while the fine-grained masking provides context-conditioned variation during decoding. Moreover, POP is a lightweight, plug-and-play method that requires no preprocessing, including offline calibration, retraining, or learning predictors. Extensive evaluations across diverse LFMs, including large language models (LLMs), mixture-of-experts models (MoEs), and vision-language models (VLMs), demonstrate that POP consistently delivers higher accuracy than existing pruning approaches while incurring smaller computational overhead and minimizing inference latency.