Wild Guesses and Mild Guesses in Active Concept Learning
作者: Anirudh Chari, Neil Pattanaik
分类: cs.AI
发布日期: 2026-02-06
💡 一句话要点
研究主动概念学习中查询策略对神经符号贝叶斯学习器的影响,揭示了确认偏差的潜在合理性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动概念学习 神经符号学习 贝叶斯推理 大型语言模型 查询策略
📋 核心要点
- 主动概念学习需要在查询信息量和学习器稳定性之间进行权衡,现有方法难以兼顾。
- 本文提出一种神经符号贝叶斯学习器,结合大型语言模型生成假设和贝叶斯更新进行学习。
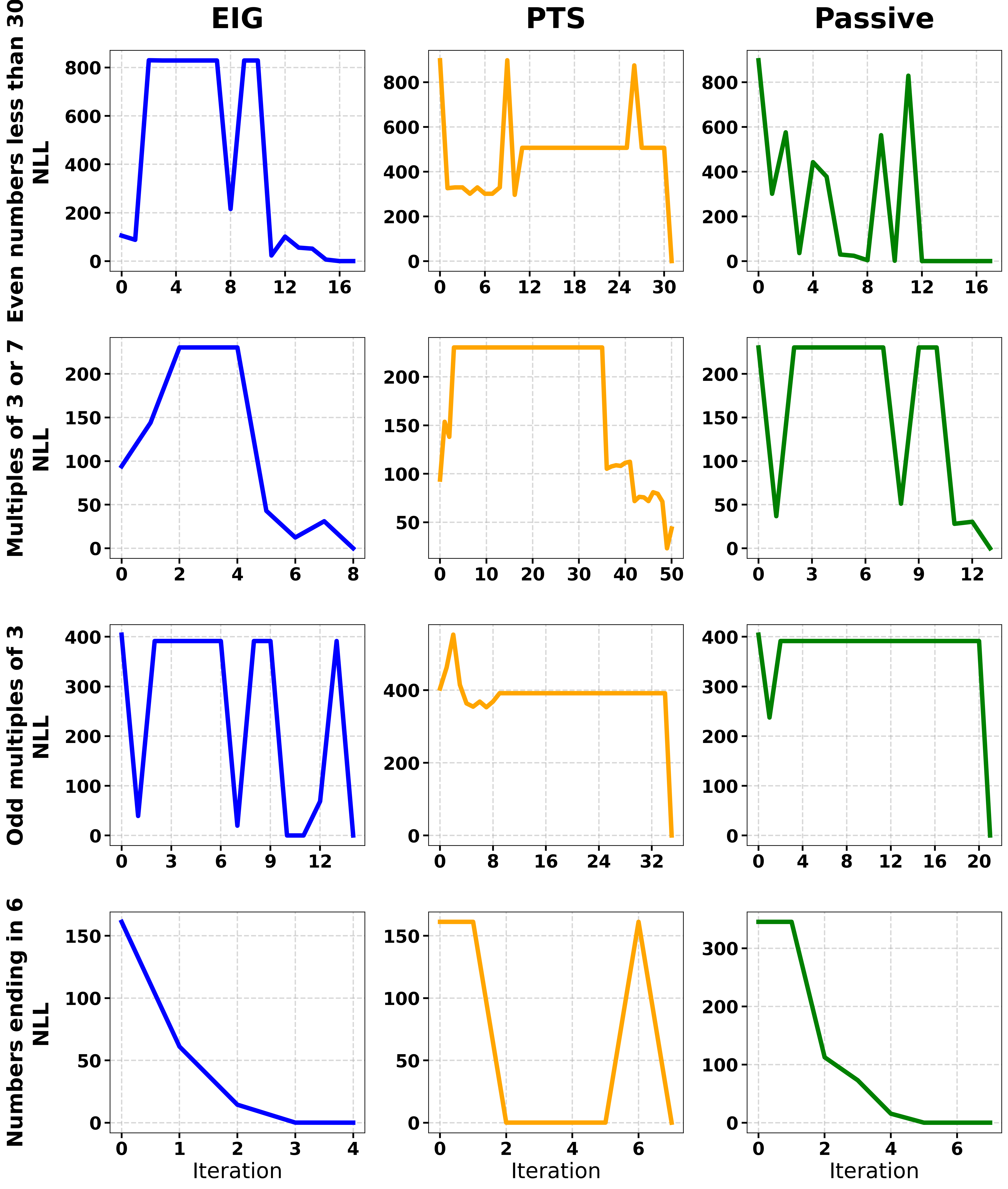
- 实验表明,最大化信息增益的策略在复杂概念上有效,但在简单概念上不如积极测试策略。
📝 摘要(中文)
人类的概念学习通常是主动的:学习者选择查询或测试哪些实例,以减少对潜在规则或类别的认知不确定性。主动概念学习必须平衡查询的信息量与生成和评估假设的学习器的稳定性。本文研究了神经符号贝叶斯学习器中的这种权衡,该学习器的假设是由大型语言模型(LLM)提出的可执行程序,并通过贝叶斯更新进行重新加权。我们比较了理性主动学习器(Rational Active Learner),它选择查询以最大化近似预期信息增益(EIG),以及类似人类的积极测试策略(Positive Test Strategy,PTS),它查询在当前最佳假设下预测为正的实例。在经典数字游戏中的概念学习任务中,当需要证伪时(例如,复合或带有异常的规则),EIG是有效的,但在简单概念上表现不佳。我们将这种失败归因于EIG策略和LLM提议分布之间的支持不匹配:高度诊断性的边界查询将后验推向生成器产生无效或过于具体的程序的区域,从而在粒子近似中产生支持不匹配陷阱。PTS的信息量虽然不是最优的,但倾向于通过选择“安全”查询来维持提议的有效性,从而更快地收敛于简单规则。我们的结果表明,“确认偏差”可能不是一种认知错误,而是一种合理的适应,用于在人类思维中稀疏、开放式的假设空间中维持易于处理的推理。
🔬 方法详解
问题定义:论文旨在解决主动概念学习中,如何选择合适的查询策略以提高学习效率和准确性的问题。现有方法,如最大化预期信息增益(EIG)的策略,在复杂概念学习中表现良好,但在简单概念学习中却不如人意。这主要是因为EIG策略倾向于选择边界查询,可能导致学习器陷入“支持不匹配陷阱”,即学习器生成的假设与实际情况不符。
核心思路:论文的核心思路是研究不同查询策略对神经符号贝叶斯学习器的影响,特别是EIG策略和积极测试策略(PTS)。PTS模拟人类的“确认偏差”,倾向于选择支持当前最佳假设的查询。论文认为,这种“确认偏差”可能是一种合理的适应,有助于在复杂的假设空间中维持有效的推理。
技术框架:论文构建了一个神经符号贝叶斯学习框架,该框架包含以下几个主要模块:1) 大型语言模型(LLM):用于生成候选假设,即可以执行的程序。2) 贝叶斯更新:用于根据观察到的数据重新加权这些假设。3) 查询策略:包括EIG和PTS,用于选择下一个要查询的实例。整体流程是:LLM生成假设 -> 贝叶斯更新假设权重 -> 查询策略选择实例 -> 获得反馈 -> 更新假设权重,循环迭代。
关键创新:论文最重要的技术创新点在于,它揭示了EIG策略在简单概念学习中的局限性,并提出了“支持不匹配陷阱”的概念来解释这种现象。同时,论文强调了PTS策略的潜在优势,认为“确认偏差”可能是一种合理的认知策略,有助于在复杂的假设空间中进行有效推理。
关键设计:论文使用了经典的数字游戏作为概念学习任务。EIG策略通过近似计算预期信息增益来选择查询,PTS策略则选择在当前最佳假设下预测为正的实例。LLM使用预训练的语言模型,并进行微调以生成可执行的程序。贝叶斯更新使用粒子滤波方法来近似计算后验分布。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EIG策略在复杂概念学习中表现良好,但在简单概念学习中不如PTS策略。论文通过分析发现,EIG策略倾向于选择边界查询,导致学习器陷入“支持不匹配陷阱”。PTS策略虽然信息量不是最优的,但能够维持提议的有效性,从而更快地收敛于简单规则。
🎯 应用场景
该研究成果可应用于机器人学习、智能教育等领域。例如,机器人可以通过主动查询来学习新的概念和规则,从而更好地适应复杂环境。智能教育系统可以根据学生的学习情况,选择合适的查询策略,帮助学生更有效地掌握知识。
📄 摘要(原文)
Human concept learning is typically active: learners choose which instances to query or test in order to reduce uncertainty about an underlying rule or category. Active concept learning must balance informativeness of queries against the stability of the learner that generates and scores hypotheses. We study this trade-off in a neuro-symbolic Bayesian learner whose hypotheses are executable programs proposed by a large language model (LLM) and reweighted by Bayesian updating. We compare a Rational Active Learner that selects queries to maximize approximate expected information gain (EIG) and the human-like Positive Test Strategy (PTS) that queries instances predicted to be positive under the current best hypothesis. Across concept-learning tasks in the classic Number Game, EIG is effective when falsification is necessary (e.g., compound or exception-laden rules), but underperforms on simple concepts. We trace this failure to a support mismatch between the EIG policy and the LLM proposal distribution: highly diagnostic boundary queries drive the posterior toward regions where the generator produces invalid or overly specific programs, yielding a support-mismatch trap in the particle approximation. PTS is information-suboptimal but tends to maintain proposal validity by selecting "safe" queries, leading to faster convergence on simple rules. Our results suggest that "confirmation bias" may not be a cognitive error, but rather a rational adaptation for maintaining tractable inference in the sparse, open-ended hypothesis spaces characteristic of human thought.