Towards Understanding What State Space Models Learn About Code
作者: Jiali Wu, Abhinav Anand, Shweta Verma, Mira Mezini
分类: cs.AI
发布日期: 2026-02-06
💡 一句话要点
首个SSM代码理解分析:揭示其在代码建模中的优势与局限性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 代码理解 模型分析 频域分析 代码表示学习
📋 核心要点
- Transformer在代码理解任务中表现出色,但效率较低,SSM作为替代方案涌现,但其内部机制是黑盒。
- 论文通过系统分析和对比实验,揭示了SSM在代码建模中的优势和不足,尤其是在语法和语义关系的学习上。
- 论文提出了SSM-Interpret框架,诊断了微调过程中的频谱偏移问题,并据此改进了SSM架构,提升了性能。
📝 摘要(中文)
本文对基于状态空间模型(SSM)的代码模型进行了首次系统性分析,并首次对SSM和Transformer代码模型进行了比较分析。研究表明,SSM在预训练阶段能更好地捕捉代码的语法和语义,但在任务微调期间会遗忘某些语法和语义关系,尤其是在强调短程依赖的任务中。为了诊断这个问题,我们引入了SSM-Interpret,一个频域框架,揭示了微调期间向短程依赖的频谱偏移。基于这些发现,我们提出了架构修改,显著提高了基于SSM的代码模型的性能,验证了我们的分析可以直接改进模型。
🔬 方法详解
问题定义:现有基于Transformer的代码理解模型计算成本高昂。状态空间模型(SSM)作为一种更高效的替代方案,在代码理解任务中展现出潜力。然而,SSM在代码建模中的内部机制尚不明确,缺乏对其学习到的代码表示的深入理解。现有研究未能充分揭示SSM在代码语法和语义理解方面的优势与不足,以及与Transformer模型的差异。
核心思路:论文的核心思路是通过系统性的分析和比较,揭示SSM在代码理解任务中的学习行为。具体而言,通过对比SSM和Transformer在预训练和微调阶段对代码语法和语义的捕捉能力,发现SSM在微调过程中可能存在的“遗忘”现象。进一步,利用频域分析工具SSM-Interpret诊断微调过程中的频谱偏移,从而指导模型改进。
技术框架:论文提出的研究框架主要包含以下几个阶段:1) 对比SSM和Transformer在代码预训练阶段的学习能力,关注其对代码语法和语义的捕捉能力。2) 分析SSM和Transformer在代码微调阶段的表现,特别是针对强调短程依赖的任务。3) 引入SSM-Interpret框架,通过频域分析揭示微调过程中SSM的频谱变化。4) 基于分析结果,提出针对SSM架构的改进方案。
关键创新:论文的关键创新在于:1) 首次对SSM在代码理解任务中的学习行为进行了系统性分析,填补了该领域的空白。2) 提出了SSM-Interpret框架,利用频域分析诊断SSM在微调过程中的频谱偏移问题,为理解和改进SSM提供了新的视角。3) 通过实验验证了分析结果的有效性,并基于分析结果成功改进了SSM架构,提升了代码理解性能。
关键设计:SSM-Interpret框架是关键设计之一,它通过将SSM的内部状态表示转换到频域,分析不同频率成分的贡献,从而揭示模型对不同范围依赖关系的建模能力。论文还基于分析结果,对SSM的架构进行了修改,具体的技术细节(如参数设置、损失函数、网络结构等)在论文中应该有更详细的描述,此处未知。
🖼️ 关键图片
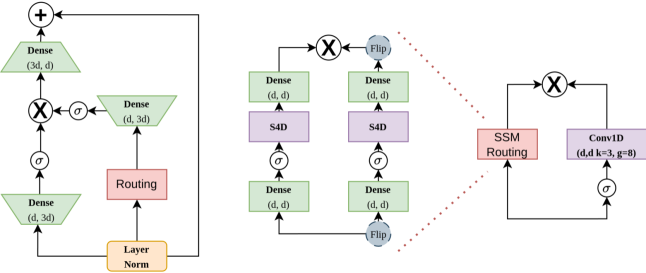
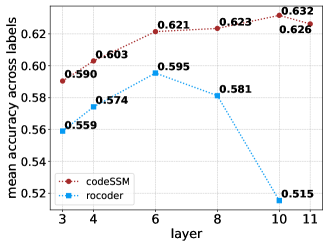
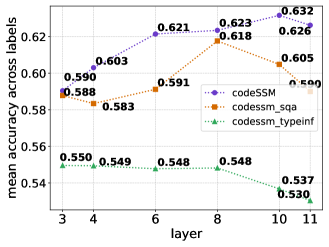
📊 实验亮点
研究表明,SSM在预训练阶段能更好地捕捉代码的语法和语义。通过SSM-Interpret框架,发现微调期间存在向短程依赖的频谱偏移。基于此,论文提出了架构修改,显著提高了基于SSM的代码模型的性能,具体提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于代码检索、代码补全、代码缺陷检测等软件工程领域。通过深入理解SSM在代码建模中的优势与局限性,可以设计出更高效、更准确的代码智能工具,提升软件开发的效率和质量。未来的研究可以探索如何进一步优化SSM架构,使其更好地适应各种代码理解任务。
📄 摘要(原文)
State Space Models (SSMs) have emerged as an efficient alternative to the transformer architecture. Recent studies show that SSMs can match or surpass Transformers on code understanding tasks, such as code retrieval, when trained under similar conditions. However, their internal mechanisms remain a black box. We present the first systematic analysis of what SSM-based code models actually learn and perform the first comparative analysis of SSM and Transformer-based code models. Our analysis reveals that SSMs outperform Transformers at capturing code syntax and semantics in pretraining but forgets certain syntactic and semantic relations during fine-tuning on task, especially when the task emphasizes short-range dependencies. To diagnose this, we introduce SSM-Interpret, a frequency-domain framework that exposes a spectral shift toward short-range dependencies during fine-tuning. Guided by these findings, we propose architectural modifications that significantly improve the performance of SSM-based code model, validating that our analysis directly enables better models.