GhostCite: A Large-Scale Analysis of Citation Validity in the Age of Large Language Models
作者: Zuyao Xu, Yuqi Qiu, Lu Sun, FaSheng Miao, Fubin Wu, Xinyi Wang, Xiang Li, Haozhe Lu, ZhengZe Zhang, Yuxin Hu, Jialu Li, Jin Luo, Feng Zhang, Rui Luo, Xinran Liu, Yingxian Li, Jiaji Liu
分类: cs.CR, cs.AI
发布日期: 2026-02-06
💡 一句话要点
GhostCite:大规模分析大语言模型时代下引文有效性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 引文验证 学术诚信 自然语言处理 信息检索
📋 核心要点
- 现有学术写作中,大型语言模型(LLM)生成引文时存在严重的“幻觉”问题,导致大量无效或捏造的引文出现,威胁科学研究的可靠性。
- 论文提出CiteVerifier框架,用于大规模引文验证,并对多个LLM在不同研究领域的引文生成能力进行基准测试,量化了引文幻觉的严重程度。
- 实验分析了大量已发表的论文,发现无效引文比例正在上升,同时调查显示研究人员和审稿人在引文验证方面存在明显不足,加剧了问题。
📝 摘要(中文)
引文是科学主张可信度的基础,但无效或捏造的引文会破坏这种信任。随着大型语言模型(LLM)的出现,这种风险日益加剧:LLM越来越多地被用于学术写作,但它们捏造引文(“幽灵引文”)的倾向对引文有效性构成了系统性威胁。为了量化这种威胁并为缓解措施提供信息,我们开发了CiteVerifier,一个用于大规模引文验证的开源框架,并通过基于它的三个实验,对LLM时代的引文有效性进行了首次全面研究。我们对13个最先进的LLM在40个研究领域的引文生成进行了基准测试,发现所有模型都以14.23%到94.93%的比率幻觉引文,并且在不同的研究领域之间存在显著差异。此外,我们分析了来自顶级AI/ML和安全会议(2020-2025)上发表的56,381篇论文中的220万条引文,证实了1.07%的论文包含无效或捏造的引文(604篇论文),仅在2025年就增加了80.9%。此外,我们调查了97名研究人员,并在删除3个冲突样本后分析了94份有效回复,揭示了一个关键的“验证差距”:41.5%的研究人员复制粘贴BibTeX而不进行检查,44.4%的研究人员在遇到可疑参考文献时选择不采取行动;同时,76.7%的审稿人没有彻底检查参考文献,80.0%的审稿人从未怀疑过伪造的引文。我们的研究结果揭示了一个加速的危机,即不可靠的AI工具,加上研究人员不足的人工验证和同行评审的不足审查,使得伪造的引文污染了科学记录。我们为研究人员、会议组织者和工具开发者提出了干预措施,以保护引文的完整性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在学术写作中生成引文时出现的“幻觉”问题,即生成无效或捏造的引文。现有方法缺乏有效的工具和流程来大规模地检测和验证这些引文,导致科学文献中出现越来越多的错误信息。研究人员和审稿人对引文验证的重视程度不足,进一步加剧了这一问题。
核心思路:论文的核心思路是通过开发一个名为CiteVerifier的开源框架,实现大规模的引文验证。该框架能够自动检测和验证引文的有效性,从而帮助研究人员和审稿人识别和纠正错误引文。此外,论文还通过实验和调查,量化了LLM引文幻觉的程度,并揭示了研究人员和审稿人在引文验证方面的不足。
技术框架:CiteVerifier框架包含以下主要模块:1) 引文提取模块,用于从论文中提取引文信息;2) 引文验证模块,用于验证引文的有效性,例如检查引文是否存在、内容是否一致等;3) 报告生成模块,用于生成引文验证报告,方便研究人员和审稿人查看。论文还设计了实验流程,包括LLM引文生成基准测试和已发表论文的引文分析。
关键创新:论文的主要创新点在于:1) 提出了CiteVerifier框架,为大规模引文验证提供了一个有效的工具;2) 对LLM引文幻觉进行了全面的量化分析,揭示了问题的严重性;3) 通过调查揭示了研究人员和审稿人在引文验证方面的不足。与现有方法相比,CiteVerifier能够更有效地检测和验证引文,并为研究人员和审稿人提供更全面的引文验证信息。
关键设计:CiteVerifier框架的具体实现细节未知,摘要中没有提供关于参数设置、损失函数、网络结构等技术细节。但可以推测,引文验证模块可能使用了自然语言处理技术,例如命名实体识别、关系抽取等,来分析引文内容并进行验证。
🖼️ 关键图片

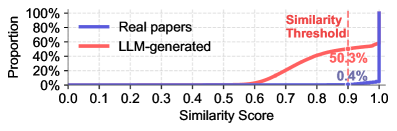

📊 实验亮点
实验结果表明,所有测试的LLM都存在不同程度的引文幻觉,比率从14.23%到94.93%不等。对已发表论文的分析发现,1.07%的论文包含无效或捏造的引文,且2025年这一比例显著上升,增加了80.9%。调查显示,41.5%的研究人员复制粘贴BibTeX而不检查,76.7%的审稿人没有彻底检查参考文献。
🎯 应用场景
该研究成果可应用于学术出版、科研诚信管理、教育等领域。CiteVerifier框架可以帮助期刊编辑部、科研机构和高校自动检测和纠正论文中的错误引文,提高学术论文的质量和可靠性。此外,该研究还可以促进研究人员和审稿人对引文验证的重视,从而维护科学研究的诚信。
📄 摘要(原文)
Citations provide the basis for trusting scientific claims; when they are invalid or fabricated, this trust collapses. With the advent of Large Language Models (LLMs), this risk has intensified: LLMs are increasingly used for academic writing, yet their tendency to fabricate citations (
ghost citations'') poses a systemic threat to citation validity. To quantify this threat and inform mitigation, we develop CiteVerifier, an open-source framework for large-scale citation verification, and conduct the first comprehensive study of citation validity in the LLM era through three experiments built on it. We benchmark 13 state-of-the-art LLMs on citation generation across 40 research domains, finding that all models hallucinate citations at rates from 14.23\% to 94.93\%, with significant variation across research domains. Moreover, we analyze 2.2 million citations from 56,381 papers published at top-tier AI/ML and Security venues (2020--2025), confirming that 1.07\% of papers contain invalid or fabricated citations (604 papers), with an 80.9\% increase in 2025 alone. Furthermore, we survey 97 researchers and analyze 94 valid responses after removing 3 conflicting samples, revealing a criticalverification gap'': 41.5\% of researchers copy-paste BibTeX without checking and 44.4\% choose no-action responses when encountering suspicious references; meanwhile, 76.7\% of reviewers do not thoroughly check references and 80.0\% never suspect fake citations. Our findings reveal an accelerating crisis where unreliable AI tools, combined with inadequate human verification by researchers and insufficient peer review scrutiny, enable fabricated citations to contaminate the scientific record. We propose interventions for researchers, venues, and tool developers to protect citation integrity.