Multimodal Generative Retrieval Model with Staged Pretraining for Food Delivery on Meituan
作者: Boyu Chen, Tai Guo, Weiyu Cui, Yuqing Li, Xingxing Wang, Chuan Shi, Cheng Yang
分类: cs.IR, cs.AI
发布日期: 2026-02-06
💡 一句话要点
针对美团外卖场景,提出基于分阶段预训练的多模态生成式检索模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 分阶段预训练 生成式模型 美团外卖 语义ID 双塔模型 对比学习
📋 核心要点
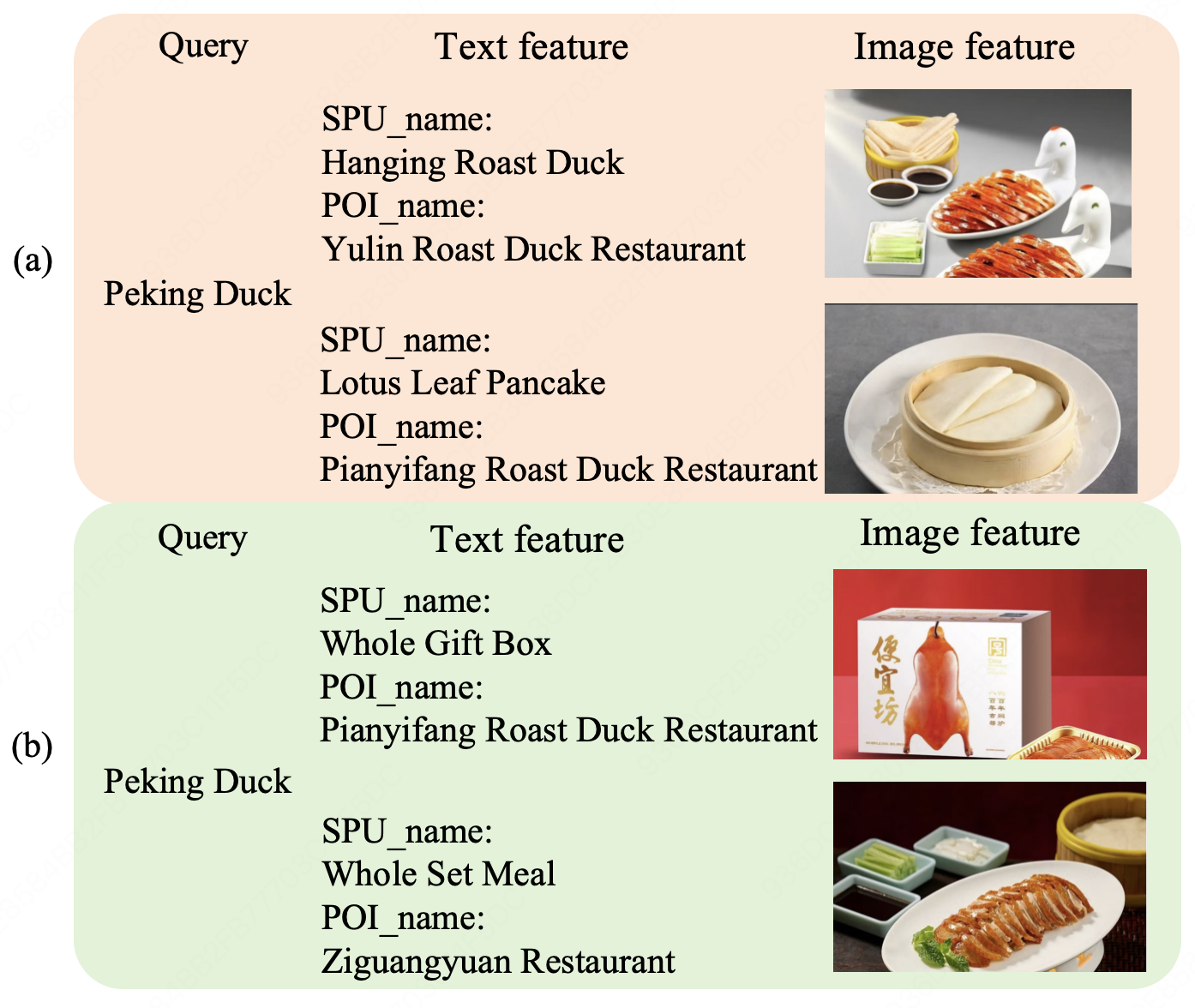
- 现有双塔多模态检索模型联合优化时,存在模态训练不均衡和“one-epoch”问题,导致模型无法有效利用所有模态特征。
- 提出分阶段预训练策略,引导模型在不同阶段关注特定任务,平衡模态训练,并设计生成式和判别式任务利用语义ID。
- 在美团外卖数据集上,该方法在离线指标和在线A/B测试中均显著优于现有方法,验证了其有效性和实用性。
📝 摘要(中文)
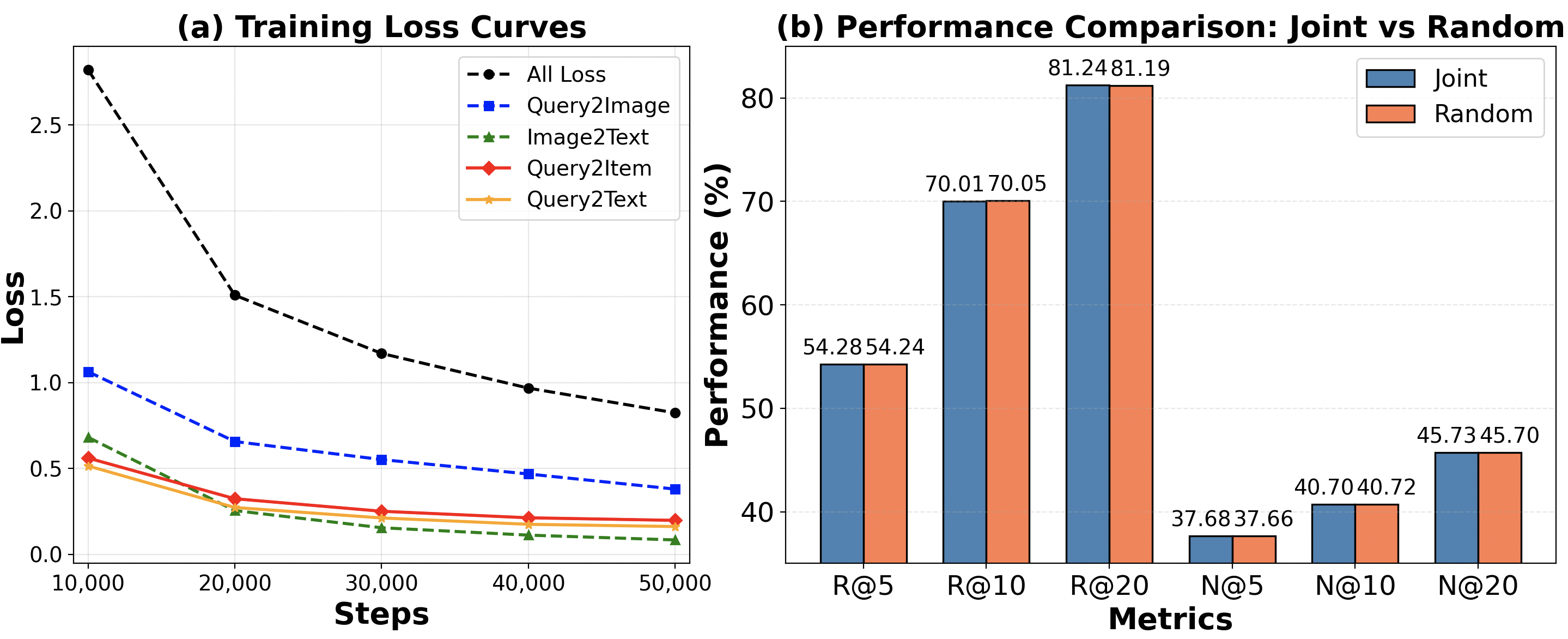
多模态检索模型在美团外卖等场景中变得越来越重要,丰富的多模态特征可以满足多样化的用户需求并实现精准检索。主流方法通常采用查询和物品之间的双塔架构,并对塔内和塔间任务进行联合优化。然而,我们观察到联合优化通常导致某些模态主导训练过程,而忽略其他模态。此外,不同模态之间不一致的训练速度容易导致“one-epoch”问题。为了解决这些挑战,我们提出了一种分阶段预训练策略,该策略引导模型在每个阶段专注于特定的任务,使其能够有效地关注和利用多模态特征,并允许灵活控制每个阶段的训练过程,以避免“one-epoch”问题。此外,为了更好地利用压缩高维多模态嵌入的语义ID,我们设计了生成式和判别式任务,以帮助模型理解SID、查询和物品特征之间的关联,从而提高整体性能。在美团大规模真实数据上进行的大量实验表明,与主流基线相比,我们的方法在R@5、R@10和R@20上分别实现了3.80%、2.64%和2.17%的提升,在N@5、N@10和N@20上分别实现了5.10%、4.22%和2.09%的提升。在美团平台上的在线A/B测试表明,我们的方法实现了1.12%的收入增长和1.02%的点击率增长,验证了我们的方法在实际应用中的有效性和优越性。
🔬 方法详解
问题定义:论文旨在解决美团外卖场景下,多模态检索模型训练过程中存在的模态利用不充分的问题。现有方法采用双塔结构进行联合优化,但容易出现某些模态主导训练,导致其他模态被忽略,同时不同模态训练速度不一致,易出现“one-epoch”问题,影响检索效果。
核心思路:论文的核心思路是采用分阶段预训练策略,将多模态特征的学习分解为多个阶段,每个阶段侧重于特定的任务,从而引导模型更好地关注和利用不同模态的特征。此外,利用语义ID(SID)压缩高维多模态嵌入,并通过生成式和判别式任务,增强模型对SID、查询和物品特征之间关联的理解。
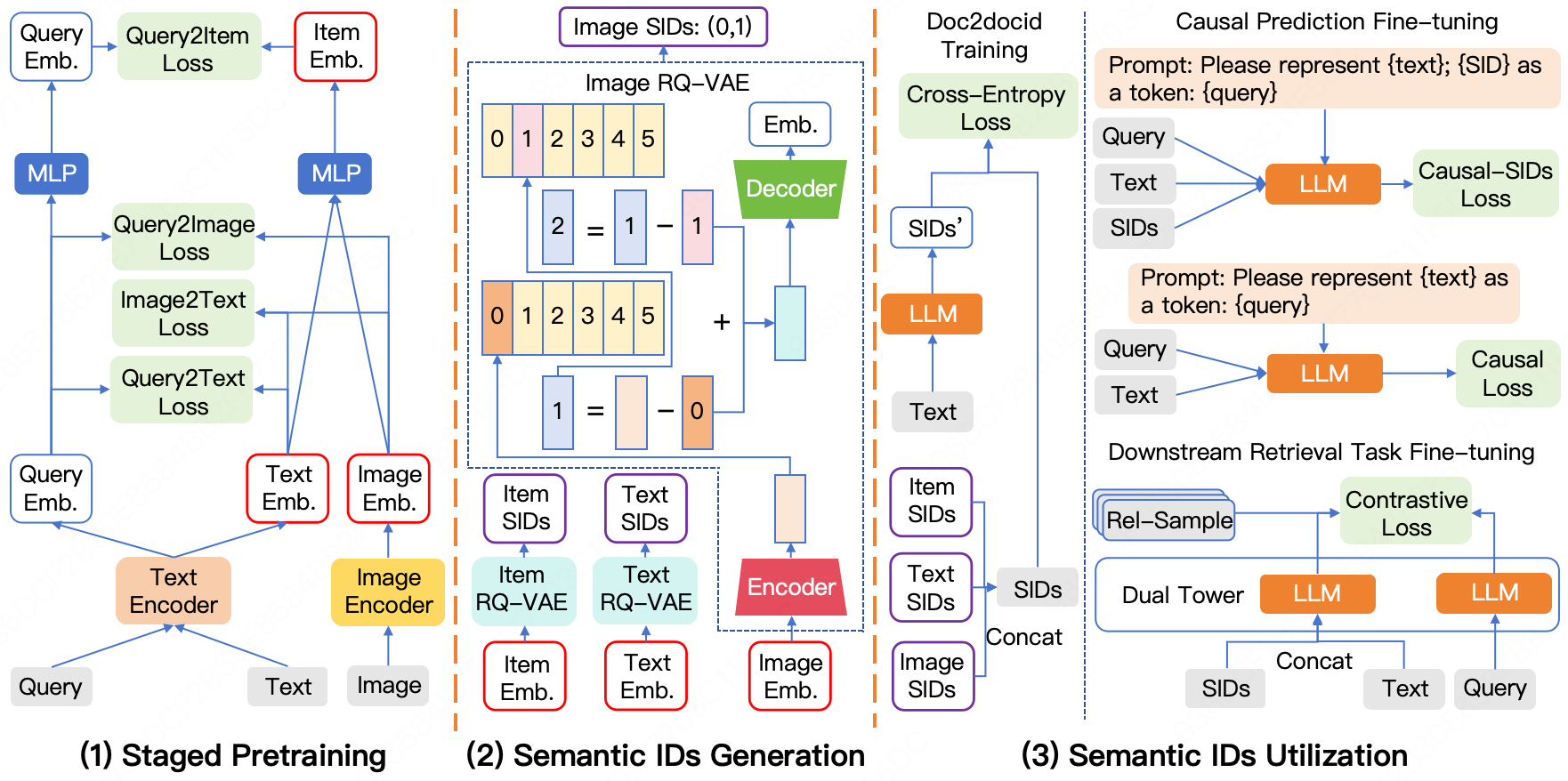
技术框架:整体框架包含三个主要阶段:第一阶段,进行单模态预训练,分别训练文本、图像等模态的表示;第二阶段,进行跨模态对齐预训练,学习不同模态之间的关联;第三阶段,进行联合训练,结合检索任务进行微调。模型采用双塔结构,查询塔和物品塔分别对查询和物品进行编码。在训练过程中,使用生成式任务(预测SID)和判别式任务(区分正负样本)来辅助学习。
关键创新:最重要的技术创新点在于分阶段预训练策略,它打破了传统联合训练的模式,允许对不同模态进行更精细的控制和优化,避免了模态之间的相互干扰和“one-epoch”问题。此外,结合生成式和判别式任务来利用语义ID,增强了模型对多模态信息的理解。
关键设计:在分阶段预训练中,每个阶段采用不同的损失函数和训练目标。例如,在单模态预训练阶段,可以使用Masked Language Model (MLM) 或对比学习等方法。在跨模态对齐阶段,可以使用InfoNCE损失来最大化正样本之间的互信息。在联合训练阶段,可以使用交叉熵损失或hinge loss等。语义ID的生成方式未知,但推测是通过聚类或量化等方法将高维嵌入映射到离散的ID空间。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在美团外卖数据集上取得了显著的性能提升。离线实验中,R@5、R@10和R@20指标分别提升了3.80%、2.64%和2.17%,N@5、N@10和N@20指标分别提升了5.10%、4.22%和2.09%。在线A/B测试显示,收入增长了1.12%,点击率增长了1.02%,验证了该方法在实际应用中的有效性。
🎯 应用场景
该研究成果可广泛应用于电商、外卖、推荐系统等领域,尤其是在需要利用多模态信息进行检索和排序的场景中。通过提升检索的准确性和效率,可以改善用户体验,提高平台收入,并为个性化推荐提供更丰富的信息。
📄 摘要(原文)
Multimodal retrieval models are becoming increasingly important in scenarios such as food delivery, where rich multimodal features can meet diverse user needs and enable precise retrieval. Mainstream approaches typically employ a dual-tower architecture between queries and items, and perform joint optimization of intra-tower and inter-tower tasks. However, we observe that joint optimization often leads to certain modalities dominating the training process, while other modalities are neglected. In addition, inconsistent training speeds across modalities can easily result in the one-epoch problem. To address these challenges, we propose a staged pretraining strategy, which guides the model to focus on specialized tasks at each stage, enabling it to effectively attend to and utilize multimodal features, and allowing flexible control over the training process at each stage to avoid the one-epoch problem. Furthermore, to better utilize the semantic IDs that compress high-dimensional multimodal embeddings, we design both generative and discriminative tasks to help the model understand the associations between SIDs, queries, and item features, thereby improving overall performance. Extensive experiments on large-scale real-world Meituan data demonstrate that our method achieves improvements of 3.80%, 2.64%, and 2.17% on R@5, R@10, and R@20, and 5.10%, 4.22%, and 2.09% on N@5, N@10, and N@20 compared to mainstream baselines. Online A/B testing on the Meituan platform shows that our approach achieves a 1.12% increase in revenue and a 1.02% increase in click-through rate, validating the effectiveness and superiority of our method in practical applications.