Same Answer, Different Representations: Hidden instability in VLMs
作者: Farooq Ahmad Wani, Alessandro Suglia, Rohit Saxena, Aryo Pradipta Gema, Wai-Chung Kwan, Fazl Barez, Maria Sofia Bucarelli, Fabrizio Silvestri, Pasquale Minervini
分类: cs.AI, cs.CV
发布日期: 2026-02-06
💡 一句话要点
揭示视觉语言模型内部表征不稳定性:相同答案,不同表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 鲁棒性评估 表征稳定性 内部嵌入漂移 频谱敏感性
📋 核心要点
- 现有VLM鲁棒性评估主要关注输出不变性,忽略了内部表征的稳定性,可能导致对模型真实鲁棒性的误判。
- 提出一种表征感知和频率感知的评估框架,从内部嵌入漂移、频谱敏感性和结构平滑度等多维度评估VLM的稳定性。
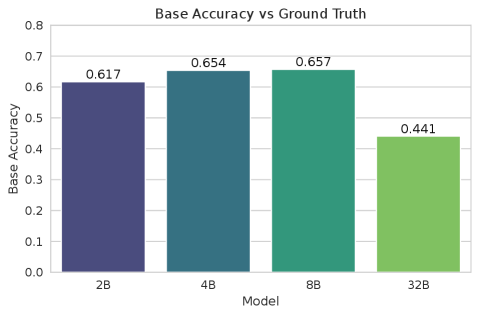
- 实验表明,VLM在保持输出不变的情况下,内部表征可能发生显著漂移,且模型规模增大并不一定提高鲁棒性。
📝 摘要(中文)
本文研究了视觉语言模型(VLM)的鲁棒性,通常通过输出层面的不变性来评估,隐含地假设稳定的预测反映了稳定的多模态处理。本文认为这种假设是不充分的。我们引入了一个表征感知和频率感知的评估框架,该框架测量内部嵌入漂移、频谱敏感性和结构平滑度(视觉tokens的空间一致性),以及标准的基于标签的指标。将此框架应用于SEEDBench、MMMU和POPE数据集上的现代VLM,揭示了三种不同的失效模式。首先,模型经常在保持预测答案的同时经历显著的内部表征漂移;对于文本覆盖等扰动,这种漂移接近图像间变异的幅度,表明表征移动到通常被不相关输入占据的区域,尽管输出没有改变。其次,鲁棒性不会随着规模的增加而提高;更大的模型实现了更高的准确率,但表现出相等或更大的敏感性,这与更尖锐但更脆弱的决策边界一致。第三,我们发现扰动对任务的影响不同:当它们扰乱模型如何组合粗略和精细的视觉线索时,它们会损害推理;但在幻觉基准测试中,它们可以通过使模型生成更保守的答案来减少误报。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)的鲁棒性评估主要依赖于输出层面的不变性,即输入发生微小扰动时,模型的预测结果是否保持不变。然而,这种评估方式忽略了模型内部表征的稳定性。即使输出结果不变,模型的内部表征也可能发生显著变化,这表明模型可能依赖于脆弱的决策边界,从而导致在更复杂的场景下失效。因此,如何全面评估VLM的鲁棒性,特别是其内部表征的稳定性,是一个亟待解决的问题。
核心思路:本文的核心思路是引入一种表征感知和频率感知的评估框架,从多个维度评估VLM的内部表征稳定性。该框架不仅关注模型的输出结果,还关注模型内部嵌入的漂移程度、频谱敏感性以及视觉tokens的空间一致性。通过综合评估这些指标,可以更全面地了解VLM的鲁棒性,并发现潜在的失效模式。这种方法的核心在于,认为稳定的输出并不一定意味着稳定的内部处理过程,需要深入挖掘模型内部的表征变化。
技术框架:该评估框架包含以下几个主要模块:1) 内部嵌入漂移测量:计算原始图像和扰动图像在VLM内部产生的嵌入向量之间的距离,以衡量表征的漂移程度。2) 频谱敏感性分析:通过分析嵌入向量的频谱,评估模型对输入扰动的敏感程度。3) 结构平滑度评估:衡量视觉tokens在空间上的一致性,即相邻tokens的嵌入向量是否相似。4) 标准标签评估:使用传统的基于标签的指标,如准确率,评估模型的输出性能。该框架将这些模块结合起来,形成一个综合的评估体系。
关键创新:本文最重要的技术创新点在于提出了一个表征感知和频率感知的评估框架,该框架能够从多个维度评估VLM的内部表征稳定性。与传统的只关注输出结果的评估方法相比,该框架能够更全面地了解VLM的鲁棒性,并发现潜在的失效模式。此外,本文还揭示了VLM的一些有趣的现象,例如,模型在保持输出不变的情况下,内部表征可能发生显著漂移,且模型规模增大并不一定提高鲁棒性。
关键设计:在内部嵌入漂移测量方面,使用了余弦相似度来衡量嵌入向量之间的距离。在频谱敏感性分析方面,使用了快速傅里叶变换(FFT)来分析嵌入向量的频谱。在结构平滑度评估方面,使用了相邻tokens的嵌入向量之间的欧氏距离来衡量空间一致性。此外,在实验中,使用了SEEDBench、MMMU和POPE等多个数据集,以评估该框架的有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使在输出结果保持不变的情况下,VLM的内部表征也可能发生显著漂移,对于文本覆盖等扰动,这种漂移接近图像间变异的幅度。此外,实验还发现,模型规模增大并不一定提高鲁棒性,更大的模型可能表现出更尖锐但更脆弱的决策边界。在幻觉基准测试中,扰动可以通过使模型生成更保守的答案来减少误报。
🎯 应用场景
该研究成果可应用于提升视觉语言模型的鲁棒性和可靠性,尤其是在安全攸关的应用场景中,如自动驾驶、医疗诊断等。通过更全面地评估模型的内部表征稳定性,可以更好地发现和修复模型的潜在缺陷,从而提高模型的泛化能力和抗干扰能力。此外,该研究还可以为未来的VLM架构设计提供指导,例如,设计更稳定的表征学习方法。
📄 摘要(原文)
The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.