Sample-Efficient Policy Space Response Oracles with Joint Experience Best Response
作者: Ariyan Bighashdel, Thiago D. Simão, Frans A. Oliehoek
分类: cs.MA, cs.AI, cs.LG
发布日期: 2026-02-06
备注: Accepted at the 25th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2026)
💡 一句话要点
提出Joint Experience Best Response,提升PSRO在多智能体强化学习中的样本效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 策略空间响应预言 样本效率 离线强化学习 最佳响应 联合经验 分布偏移
📋 核心要点
- 多智能体强化学习面临非平稳环境和策略多样性维护的挑战,导致训练成本高昂。
- 提出Joint Experience Best Response (JBR)方法,通过复用联合经验数据,提升最佳响应计算的样本效率。
- 实验表明,增强探索的JBR在准确性和效率之间取得了最佳平衡,混合BR在降低样本成本的同时保持了性能。
📝 摘要(中文)
多智能体强化学习(MARL)为精确的博弈论分析提供了一种可扩展的替代方案,但面临非平稳性和维持捕获非传递交互的多样化策略群体的需求。策略空间响应预言(PSRO)通过迭代地扩展具有近似最佳响应(BR)的受限博弈来解决这些问题,但每个智能体的BR训练使得它在多智能体或模拟器代价高昂的环境中成本过高。我们引入了Joint Experience Best Response (JBR),这是一种对PSRO的即插即用修改,它在当前元策略配置下收集一次轨迹,并重用此联合数据集来同时计算所有智能体的BR。这分摊了环境交互并提高了最佳响应计算的样本效率。由于JBR将BR计算转换为离线RL问题,我们提出了三种针对分布偏移偏差的补救措施:(i)具有安全策略改进的保守JBR,(ii)增强探索的JBR,它扰动数据收集并允许理论保证,以及(iii)混合BR,它将JBR与周期性的独立BR更新交错。在基准多智能体环境中,增强探索的JBR实现了最佳的准确性-效率权衡,而混合BR以一小部分样本成本实现了接近PSRO的性能。总的来说,JBR使PSRO对于大规模战略学习更具实用性,同时保持了均衡的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中,使用策略空间响应预言(PSRO)方法时,由于每个智能体都需要独立进行最佳响应(BR)训练,导致样本效率低下的问题。尤其是在智能体数量多或者模拟器交互成本高昂的环境下,这种低效性会严重限制PSRO的实际应用。
核心思路:论文的核心思路是利用所有智能体的联合经验来计算最佳响应,而不是每个智能体独立进行训练。通过一次性收集所有智能体在当前元策略下的轨迹数据,然后将这些数据用于所有智能体的最佳响应计算,从而分摊环境交互的成本,提高样本效率。
技术框架:JBR方法作为PSRO的改进,整体框架仍然遵循PSRO的迭代流程:(1) 使用当前元策略生成联合经验数据;(2) 使用JBR方法,基于联合经验数据计算每个智能体的最佳响应;(3) 更新元策略;(4) 重复以上步骤直到收敛。JBR主要替换了PSRO中独立的BR训练模块,将其转化为一个离线强化学习问题。
关键创新:JBR的关键创新在于将多智能体的最佳响应计算转化为一个离线强化学习问题,并提出了三种策略来解决由此带来的分布偏移问题:(1) Conservative JBR:采用安全策略改进方法,避免策略过度偏离原始数据分布;(2) Exploration-Augmented JBR:通过扰动数据收集过程,增加数据的多样性,并提供理论保证;(3) Hybrid BR:将JBR与周期性的独立BR更新相结合,平衡样本效率和性能。
关键设计:Conservative JBR可能采用诸如Trust Region Policy Optimization (TRPO) 或 Proximal Policy Optimization (PPO) 等算法,限制策略更新的幅度。Exploration-Augmented JBR可能通过添加噪声到智能体的动作或者状态来实现数据扰动。Hybrid BR的关键在于确定JBR和独立BR更新的频率,这可能需要根据具体环境进行调整。
🖼️ 关键图片
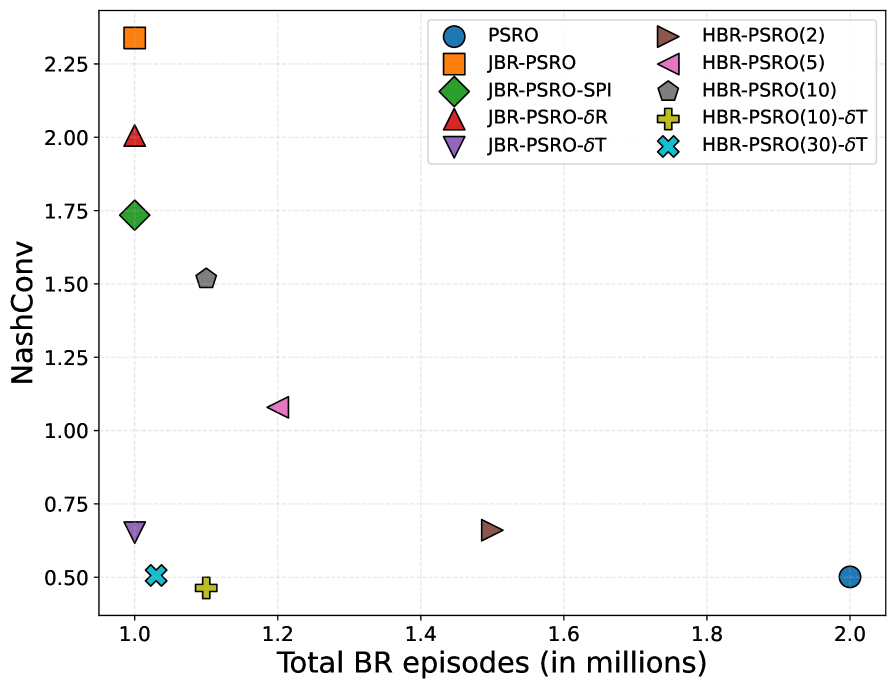


📊 实验亮点
实验结果表明,Exploration-Augmented JBR在多个基准多智能体环境中实现了最佳的准确性-效率权衡。Hybrid BR方法在样本成本大幅降低的情况下,能够达到接近标准PSRO的性能。这些结果验证了JBR方法在提高PSRO样本效率方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的复杂环境,例如机器人协同、交通调度、资源分配、网络安全等。通过提高样本效率,JBR使得PSRO方法能够更好地应用于大规模、高成本的实际场景,加速多智能体系统的开发和部署。
📄 摘要(原文)
Multi-agent reinforcement learning (MARL) offers a scalable alternative to exact game-theoretic analysis but suffers from non-stationarity and the need to maintain diverse populations of strategies that capture non-transitive interactions. Policy Space Response Oracles (PSRO) address these issues by iteratively expanding a restricted game with approximate best responses (BRs), yet per-agent BR training makes it prohibitively expensive in many-agent or simulator-expensive settings. We introduce Joint Experience Best Response (JBR), a drop-in modification to PSRO that collects trajectories once under the current meta-strategy profile and reuses this joint dataset to compute BRs for all agents simultaneously. This amortizes environment interaction and improves the sample efficiency of best-response computation. Because JBR converts BR computation into an offline RL problem, we propose three remedies for distribution-shift bias: (i) Conservative JBR with safe policy improvement, (ii) Exploration-Augmented JBR that perturbs data collection and admits theoretical guarantees, and (iii) Hybrid BR that interleaves JBR with periodic independent BR updates. Across benchmark multi-agent environments, Exploration-Augmented JBR achieves the best accuracy-efficiency trade-off, while Hybrid BR attains near-PSRO performance at a fraction of the sample cost. Overall, JBR makes PSRO substantially more practical for large-scale strategic learning while preserving equilibrium robustness.