SeeUPO: Sequence-Level Agentic-RL with Convergence Guarantees
作者: Tianyi Hu, Qingxu Fu, Yanxi Chen, Zhaoyang Liu, Bolin Ding
分类: cs.AI
发布日期: 2026-02-06
💡 一句话要点
提出SeeUPO,一种具备收敛保证的序列级Agentic-RL算法,解决多轮交互场景下的训练不稳定性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 Agentic-RL 多轮交互 收敛保证
📋 核心要点
- 现有基于LLM的Agentic-RL算法在多轮交互场景中缺乏收敛保证,导致训练不稳定,难以达到最优策略。
- SeeUPO将多轮交互建模为顺序多Agent Bandit问题,通过反向逐轮更新策略,利用后向归纳保证收敛性。
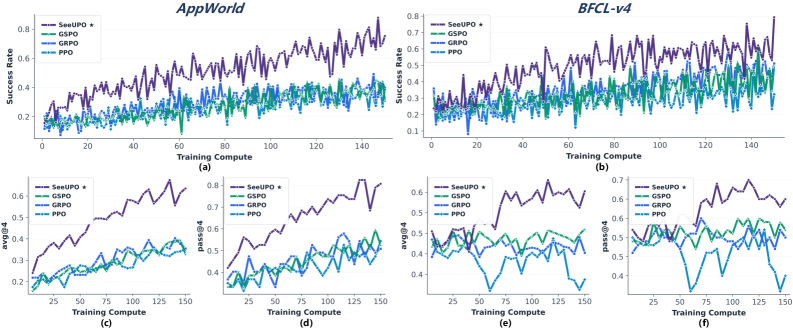
- 实验表明,SeeUPO在AppWorld和BFCL v4上显著优于现有算法,在Qwen3-14B和Qwen2.5-14B上均有大幅提升。
📝 摘要(中文)
强化学习(RL)已成为训练基于大型语言模型(LLM)的AI Agent的主流范式。然而,现有的骨干RL算法在Agentic场景中缺乏经过验证的收敛保证,尤其是在多轮设置中,这可能导致训练不稳定,无法收敛到最优策略。本文系统地分析了策略更新机制和优势估计方法的不同组合如何影响单轮/多轮场景中的收敛特性。研究发现,采用Group Relative Advantage Estimation (GRAE)的REINFORCE算法在无折扣条件下可以收敛到全局最优,但PPO与GRAE的结合会破坏PPO原有的单调改进特性。此外,本文证明了主流骨干RL算法无法在多轮场景中同时实现无评论家(critic-free)和收敛保证。为此,本文提出SeeUPO (Sequence-level Sequential Update Policy Optimization),这是一种针对多轮交互的、具有收敛保证的无评论家方法。SeeUPO将多轮交互建模为顺序执行的多Agent Bandit问题,通过以反向执行顺序逐轮顺序策略更新,通过后向归纳确保单调改进并收敛到全局最优解。在AppWorld和BFCL v4上的实验表明,SeeUPO相对于现有骨干算法有显著改进:在Qwen3-14B上相对增益为43.3%-54.6%,在Qwen2.5-14B上相对增益为24.1%-41.9%(跨基准平均),同时具有卓越的训练稳定性。
🔬 方法详解
问题定义:现有基于大型语言模型的Agentic-RL方法在多轮交互场景中存在训练不稳定的问题,缺乏收敛性保证。尤其是在复杂任务中,Agent需要进行多轮决策,传统的RL算法难以保证策略的单调改进和最终收敛到最优策略。现有的方法要么依赖于评论家网络,要么无法在多轮场景下保证收敛性。
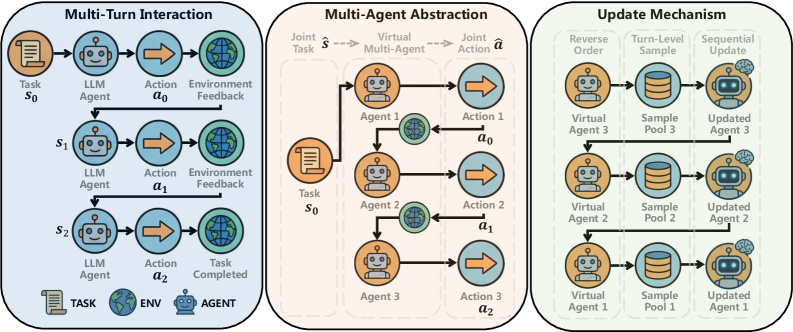
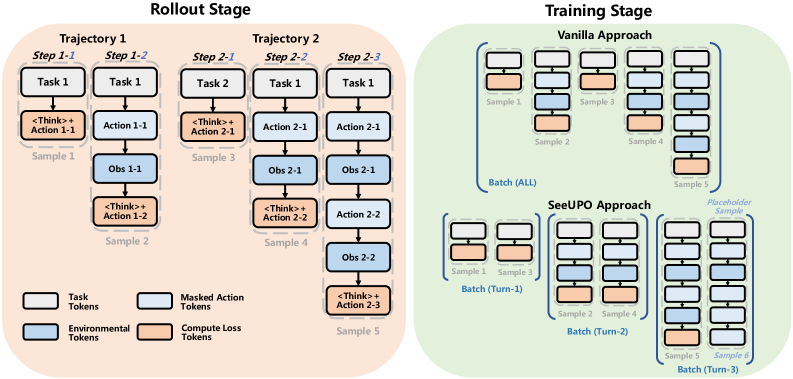
核心思路:SeeUPO的核心思路是将多轮交互过程视为一个序列化的多Agent Bandit问题,并采用后向归纳法进行策略更新。通过将整个交互序列分解为多个独立的决策步骤,并从序列的末端开始,逐步向前更新策略,从而保证每一步的策略改进都是单调的,最终实现全局最优。
技术框架:SeeUPO的整体框架包括以下几个主要阶段:1) 将多轮交互环境建模为序列化的多Agent Bandit问题。2) 从交互序列的最后一个时间步开始,计算该时间步的奖励和优势函数。3) 使用计算得到的优势函数更新当前时间步的策略。4) 依次向前迭代,直到更新完所有时间步的策略。5) 重复以上步骤,直到策略收敛。
关键创新:SeeUPO最重要的创新在于其序列化的策略更新方式和后向归纳法的应用。与传统的RL算法不同,SeeUPO不是一次性更新整个策略,而是逐轮更新,并保证每一步的策略改进都是单调的。此外,SeeUPO是一种无评论家(critic-free)的方法,避免了评论家网络带来的偏差和不稳定性。
关键设计:SeeUPO的关键设计包括:1) 使用Group Relative Advantage Estimation (GRAE)来估计优势函数,以减少方差。2) 采用Trust Region Policy Optimization (TRPO)的策略更新方式,以保证策略更新的稳定性。3) 使用反向执行顺序进行策略更新,以实现后向归纳。4) 损失函数的设计目标是最大化期望回报,同时保证策略更新的单调性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SeeUPO在AppWorld和BFCL v4两个基准测试中均取得了显著的性能提升。在Qwen3-14B模型上,SeeUPO的相对增益为43.3%-54.6%,在Qwen2.5-14B模型上,相对增益为24.1%-41.9%(跨基准平均)。此外,SeeUPO还表现出更强的训练稳定性,能够更快地收敛到最优策略。
🎯 应用场景
SeeUPO具有广泛的应用前景,可用于训练各种基于LLM的AI Agent,例如对话机器人、游戏AI、自动化客服等。该方法能够提高Agent在复杂多轮交互场景中的性能和稳定性,使其能够更好地完成各种任务。尤其是在需要高可靠性和可预测性的应用场景中,SeeUPO的收敛保证特性具有重要价值。
📄 摘要(原文)
Reinforcement learning (RL) has emerged as the predominant paradigm for training large language model (LLM)-based AI agents. However, existing backbone RL algorithms lack verified convergence guarantees in agentic scenarios, especially in multi-turn settings, which can lead to training instability and failure to converge to optimal policies. In this paper, we systematically analyze how different combinations of policy update mechanisms and advantage estimation methods affect convergence properties in single/multi-turn scenarios. We find that REINFORCE with Group Relative Advantage Estimation (GRAE) can converge to the globally optimal under undiscounted conditions, but the combination of PPO & GRAE breaks PPO's original monotonic improvement property. Furthermore, we demonstrate that mainstream backbone RL algorithms cannot simultaneously achieve both critic-free and convergence guarantees in multi-turn scenarios. To address this, we propose SeeUPO (Sequence-level Sequential Update Policy Optimization), a critic-free approach with convergence guarantees for multi-turn interactions. SeeUPO models multi-turn interaction as sequentially executed multi-agent bandit problems. Through turn-by-turn sequential policy updates in reverse execution order, it ensures monotonic improvement and convergence to global optimal solution via backward induction. Experiments on AppWorld and BFCL v4 demonstrate SeeUPO's substantial improvements over existing backbone algorithms: relative gains of 43.3%-54.6% on Qwen3-14B and 24.1%-41.9% on Qwen2.5-14B (averaged across benchmarks), along with superior training stability.