Malicious Agent Skills in the Wild: A Large-Scale Security Empirical Study
作者: Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Leo Yu Zhang
分类: cs.CR, cs.AI, cs.CL, cs.ET
发布日期: 2026-02-06
💡 一句话要点
构建恶意Agent技能数据集,揭示LLM Agent生态系统中的安全漏洞
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: LLM Agent Agent技能安全 恶意技能检测 行为分析 安全漏洞
📋 核心要点
- 现有的基于LLM的Agent技能生态系统缺乏充分的安全审查,存在潜在的安全风险,但缺乏用于评估这些风险的ground-truth数据集。
- 该研究通过行为分析大规模Agent技能,构建了一个包含恶意技能及其漏洞的标注数据集,为安全研究提供了基础。
- 实验结果揭示了Agent技能生态系统中存在的多种攻击模式,并强调了影子特性和平台漏洞在高级攻击中的作用。
📝 摘要(中文)
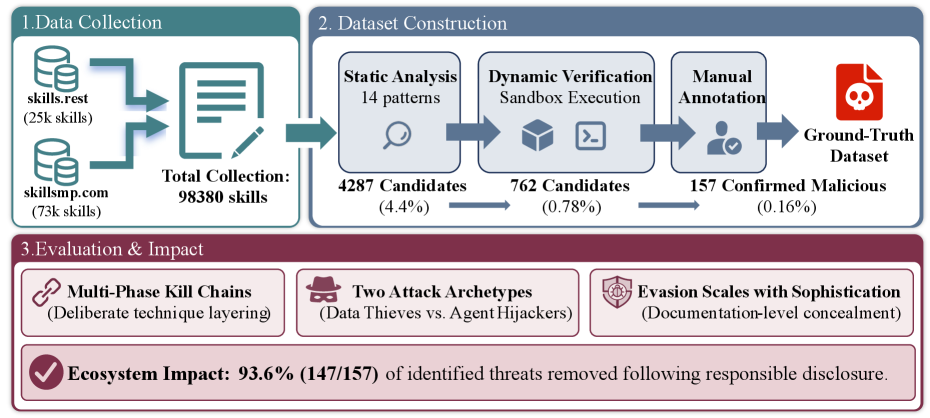
本文构建了首个恶意Agent技能的标注数据集,通过行为验证了来自两个社区注册中心的98380个技能,确认了157个恶意技能,共包含632个漏洞。研究发现,恶意技能平均包含4.03个漏洞,并横跨多个攻击链阶段。生态系统分为两类:数据窃取者,通过供应链技术窃取凭据;Agent劫持者,通过指令操纵来破坏Agent的决策。单个行为者通过模板化的品牌模仿占据了54.1%的恶意案例。未公开的“影子特性”出现在高级攻击中,某些技能甚至利用了AI平台的钩子系统和权限标志。负责任的披露使得93.6%的恶意技能在30天内被移除。研究团队发布了数据集和分析流程,以支持未来对Agent技能安全的研究。
🔬 方法详解
问题定义:论文旨在解决LLM Agent技能生态系统中缺乏系统性安全评估和恶意技能检测的问题。现有的Agent技能注册中心缺乏有效的审查机制,导致恶意技能得以传播,威胁用户安全。缺乏标注数据集阻碍了对恶意技能的识别和分析,使得安全研究难以开展。
核心思路:论文的核心思路是通过大规模的行为分析,对Agent技能进行安全评估,从而识别和标注恶意技能。通过构建包含恶意技能及其漏洞的数据集,为后续的安全研究提供基础。同时,分析恶意技能的攻击模式和利用的技术,为防御策略的制定提供指导。
技术框架:论文构建了一个自动化的分析流程,用于评估Agent技能的安全性。该流程包括以下主要阶段:1) 从社区注册中心收集Agent技能;2) 对技能进行行为分析,例如监控其网络活动、文件系统访问等;3) 根据行为特征,判断技能是否为恶意;4) 对恶意技能进行漏洞分析,确定其攻击目标和利用的技术;5) 将标注后的技能及其漏洞信息添加到数据集中。
关键创新:论文的关键创新在于构建了首个大规模的恶意Agent技能数据集,并提出了基于行为分析的恶意技能检测方法。该数据集为研究Agent技能安全提供了宝贵的资源,而行为分析方法能够有效地识别恶意技能,即使这些技能使用了混淆或规避技术。此外,论文还揭示了Agent技能生态系统中存在的多种攻击模式和利用的技术,为防御策略的制定提供了指导。
关键设计:论文在行为分析阶段,设计了一系列监控指标,用于检测Agent技能的恶意行为。这些指标包括:网络活动(例如,连接到恶意域名、发送敏感数据)、文件系统访问(例如,读取用户凭据、修改系统文件)、进程行为(例如,启动恶意进程、注入代码)。此外,论文还分析了恶意技能的指令,识别其中存在的漏洞,例如,指令注入、权限提升等。
🖼️ 关键图片


📊 实验亮点
该研究构建了包含98380个Agent技能的数据集,并从中识别出157个恶意技能,共包含632个漏洞。研究发现,单个攻击者占据了54.1%的恶意案例,并且高级攻击中100%使用了未公开的“影子特性”。负责任的披露使得93.6%的恶意技能在30天内被移除,表明及时响应可以有效降低安全风险。
🎯 应用场景
该研究成果可应用于提升LLM Agent技能生态系统的安全性。通过使用该数据集训练恶意技能检测模型,可以自动识别和阻止恶意技能的传播。研究结果还可以帮助开发者设计更安全的Agent技能,并指导平台制定更有效的安全审查策略。此外,该研究还可以促进对AI系统安全性的更广泛研究,例如,对抗性攻击、数据隐私等。
📄 摘要(原文)
Third-party agent skills extend LLM-based agents with instruction files and executable code that run on users' machines. Skills execute with user privileges and are distributed through community registries with minimal vetting, but no ground-truth dataset exists to characterize the resulting threats. We construct the first labeled dataset of malicious agent skills by behaviorally verifying 98,380 skills from two community registries, confirming 157 malicious skills with 632 vulnerabilities. These attacks are not incidental. Malicious skills average 4.03 vulnerabilities across a median of three kill chain phases, and the ecosystem has split into two archetypes: Data Thieves that exfiltrate credentials through supply chain techniques, and Agent Hijackers that subvert agent decision-making through instruction manipulation. A single actor accounts for 54.1\% of confirmed cases through templated brand impersonation. Shadow features, capabilities absent from public documentation, appear in 0\% of basic attacks but 100\% of advanced ones; several skills go further by exploiting the AI platform's own hook system and permission flags. Responsible disclosure led to 93.6\% removal within 30 days. We release the dataset and analysis pipeline to support future work on agent skill security.