LogicSkills: A Structured Benchmark for Formal Reasoning in Large Language Models
作者: Brian Rabern, Philipp Mondorf, Barbara Plank
分类: cs.AI, cs.CL
发布日期: 2026-02-06
备注: 13 pages, 5 figures
💡 一句话要点
LogicSkills:一个用于评估大语言模型形式推理能力的结构化基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 形式推理 逻辑推理 基准测试 符号化 反模型构建
📋 核心要点
- 现有逻辑推理基准难以区分大语言模型真正掌握的核心逻辑技能。
- LogicSkills基准通过隔离形式符号化、反模型构建和有效性评估三种技能来解决此问题。
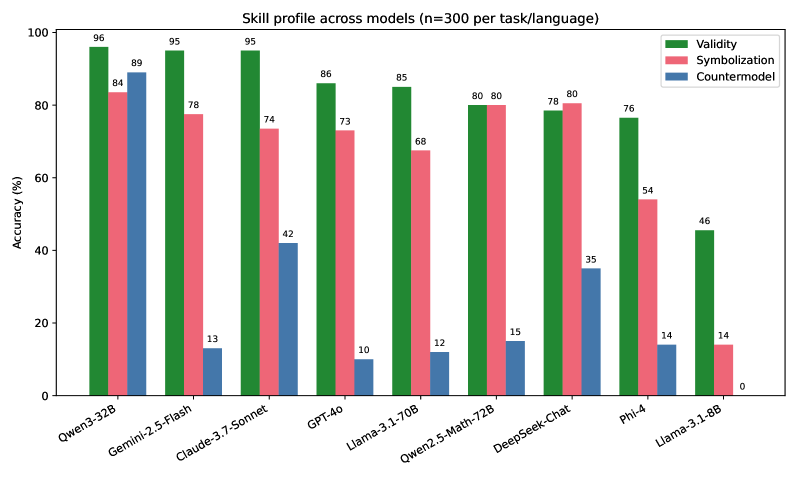
- 实验表明,模型在有效性评估上表现较好,但在符号化和反模型构建上表现较差。
📝 摘要(中文)
大型语言模型在各种逻辑推理基准测试中表现出了显著的性能。然而,它们真正掌握了哪些核心逻辑技能仍然不清楚。为了解决这个问题,我们引入了LogicSkills,这是一个统一的基准,旨在隔离形式推理中的三个基本技能:(i)形式符号化——将前提转化为一阶逻辑;(ii)反模型构建——构建一个有限结构,其中所有前提都为真,而结论为假;(iii)有效性评估——判断结论是否从给定的前提集合中得出。项目来自一阶逻辑(没有同一性)的双变量片段,并以自然英语和带有临时词语的卡罗尔风格语言呈现。所有例子都使用SMT求解器Z3验证了正确性和非平凡性。在领先的模型中,有效性方面的表现很高,但在符号化和反模型构建方面的表现明显较低,这表明模型依赖于表面模式,而不是真正的符号或基于规则的推理。
🔬 方法详解
问题定义:现有的大语言模型在逻辑推理任务上取得了不错的成果,但是否真正理解了逻辑背后的原理,还是仅仅依赖于表面模式,这是一个需要深入研究的问题。现有的基准测试难以区分模型是真正掌握了逻辑推理能力,还是仅仅通过记忆或者模式匹配来完成任务。因此,需要一个更加精细化的基准来评估模型在不同逻辑技能上的表现。
核心思路:LogicSkills的核心思路是将形式推理分解为三个关键的子任务:形式符号化、反模型构建和有效性评估。通过分别评估模型在这些子任务上的表现,可以更清晰地了解模型在哪些方面表现出色,在哪些方面存在不足。这种分解的思路有助于诊断模型的推理能力,并为未来的研究提供指导。
技术框架:LogicSkills基准包含三个主要部分,分别对应于形式符号化、反模型构建和有效性评估三个子任务。每个部分都包含一系列的逻辑问题,这些问题使用一阶逻辑的双变量片段表示,并以自然语言和卡罗尔风格的语言呈现。为了保证问题的质量,所有问题都使用SMT求解器Z3进行了验证。整体流程是:首先,人工设计逻辑问题;然后,使用Z3验证问题的正确性和非平凡性;最后,将问题以不同的形式呈现给大语言模型进行测试。
关键创新:LogicSkills的关键创新在于其对形式推理的分解和对不同逻辑技能的隔离。与以往的基准测试不同,LogicSkills不是简单地评估模型在整体逻辑推理任务上的表现,而是将任务分解为更小的、更具体的子任务,从而可以更精确地评估模型的推理能力。此外,LogicSkills还使用了多种不同的语言形式来呈现问题,从而可以更好地评估模型的泛化能力。
关键设计:LogicSkills使用了SMT求解器Z3来验证问题的正确性和非平凡性。Z3是一个高性能的SMT求解器,可以有效地解决一阶逻辑问题。此外,LogicSkills还使用了两种不同的语言形式来呈现问题:自然语言和卡罗尔风格的语言。卡罗尔风格的语言使用临时词语来代替具体的概念,从而可以更好地评估模型的抽象推理能力。在数据生成方面,作者精心设计了各种逻辑结构,并确保每个问题都具有一定的难度和挑战性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有大语言模型在有效性评估方面表现较好,但在形式符号化和反模型构建方面表现较差。这表明模型可能更多地依赖于表面模式,而不是真正的符号或基于规则的推理。例如,模型在判断逻辑结论是否成立时表现较好,但在将自然语言描述转化为逻辑表达式,或者构建反例证明结论不成立时,表现明显下降。
🎯 应用场景
该研究成果可应用于评估和提升大语言模型在形式化推理、知识表示和逻辑编程等领域的应用能力。通过LogicSkills基准,可以更准确地诊断模型的推理缺陷,并指导模型改进,使其在需要严谨逻辑推理的场景中发挥更大作用,例如智能合约验证、自动定理证明等。
📄 摘要(原文)
Large language models have demonstrated notable performance across various logical reasoning benchmarks. However, it remains unclear which core logical skills they truly master. To address this, we introduce LogicSkills, a unified benchmark designed to isolate three fundamental skills in formal reasoning: (i) $\textit{formal symbolization}\unicode{x2014}$translating premises into first-order logic; (ii) $\textit{countermodel construction}\unicode{x2014}$formulating a finite structure in which all premises are true while the conclusion is false; and (iii) $\textit{validity assessment}\unicode{x2014}$deciding whether a conclusion follows from a given set of premises. Items are drawn from the two-variable fragment of first-order logic (without identity) and are presented in both natural English and a Carroll-style language with nonce words. All examples are verified for correctness and non-triviality using the SMT solver Z3. Across leading models, performance is high on validity but substantially lower on symbolization and countermodel construction, suggesting reliance on surface-level patterns rather than genuine symbolic or rule-based reasoning.