HyPER: Bridging Exploration and Exploitation for Scalable LLM Reasoning with Hypothesis Path Expansion and Reduction
作者: Shengxuan Qiu, Haochen Huang, Shuzhang Zhong, Pengfei Zuo, Meng Li
分类: cs.AI
发布日期: 2026-02-06
💡 一句话要点
HyPER:通过假设路径扩展与缩减,桥接探索与利用,实现可扩展的LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多路径推理 探索与利用 动态控制 混合专家模型
📋 核心要点
- 现有方法在多路径推理中探索与利用的平衡上存在不足,树搜索规则僵化,并行推理冗余。
- HyPER提出一种动态扩展-缩减控制策略,通过在线控制器和token级细化机制,优化计算资源分配。
- 实验表明,HyPER在多个推理基准上,显著提升了准确率,同时降低了token使用量。
📝 摘要(中文)
通过多路径思维链扩展测试时计算可以提高推理准确性,但其有效性关键取决于探索-利用的权衡。现有方法以僵化的方式处理这种权衡:树状搜索通过脆弱的扩展规则硬编码探索,干扰了预训练的推理能力;而并行推理过度探索冗余的假设路径,并依赖于较弱的答案选择。基于正确和错误的推理路径通常仅在后期阶段才出现分歧的观察,我们将测试时扩展重新定义为假设池上的动态扩展-缩减控制问题。我们提出了HyPER,一种用于混合专家模型中多路径解码的无训练在线控制策略,它使用轻量级的路径统计信息在固定预算下重新分配计算资源。HyPER包含一个在线控制器,随着假设池的演变从探索过渡到利用;一个token级别的细化机制,可以在不进行完整路径重采样的情况下实现高效的生成时利用;以及一种长度和置信度感知的聚合策略,用于可靠的答案时利用。在四个混合专家语言模型上进行的跨多个推理基准的实验表明,HyPER始终实现了卓越的准确性-计算权衡,在减少25%到40%的token使用量的同时,将准确性提高了8%到10%。
🔬 方法详解
问题定义:现有的大语言模型在进行复杂推理时,依赖于多路径的思维链。然而,如何在探索不同的推理路径(exploration)和利用已有的较优路径(exploitation)之间进行权衡是一个关键问题。传统的树搜索方法依赖固定的扩展规则,容易干扰模型本身的推理能力。而并行推理则会产生大量的冗余路径,效率低下。因此,如何在有限的计算资源下,高效地探索和利用不同的推理路径,是本文要解决的核心问题。
核心思路:HyPER的核心思路是将多路径推理过程视为一个动态的扩展-缩减控制问题。它不再采用固定的探索策略,而是根据当前假设池的状态,动态地调整探索和利用的比例。具体来说,HyPER通过一个在线控制器来决定何时扩展新的假设路径,何时缩减不 promising 的路径,从而在计算预算的约束下,最大化推理的准确性。这种动态调整的策略能够更好地适应不同推理阶段的需求,提高推理效率。
技术框架:HyPER的整体框架包含三个主要模块:1) 在线控制器:负责根据当前假设池的状态,动态地决定扩展和缩减的比例。2) Token级细化机制:在生成token时,允许对已有的假设路径进行细微的调整,从而在不进行完整路径重采样的情况下,实现高效的利用。3) 长度和置信度感知的聚合策略:在最终选择答案时,综合考虑不同路径的长度和置信度,选择最可靠的答案。整个流程是在混合专家模型上进行的,利用其强大的推理能力。
关键创新:HyPER的关键创新在于其动态的扩展-缩减控制策略。与传统的固定策略相比,HyPER能够根据当前推理的状态,自适应地调整探索和利用的比例。这种动态调整的策略能够更好地适应不同推理阶段的需求,提高推理效率。此外,token级别的细化机制也能够在不增加过多计算量的情况下,对已有的假设路径进行优化。
关键设计:在线控制器使用轻量级的路径统计信息(例如路径长度、置信度等)作为输入,通过一个简单的策略网络来决定扩展和缩减的比例。Token级别的细化机制通过对已生成的token进行微调,来优化假设路径。长度和置信度感知的聚合策略则通过加权平均的方式,综合考虑不同路径的输出,选择最终的答案。具体的参数设置和网络结构取决于具体的混合专家模型和推理任务。
🖼️ 关键图片

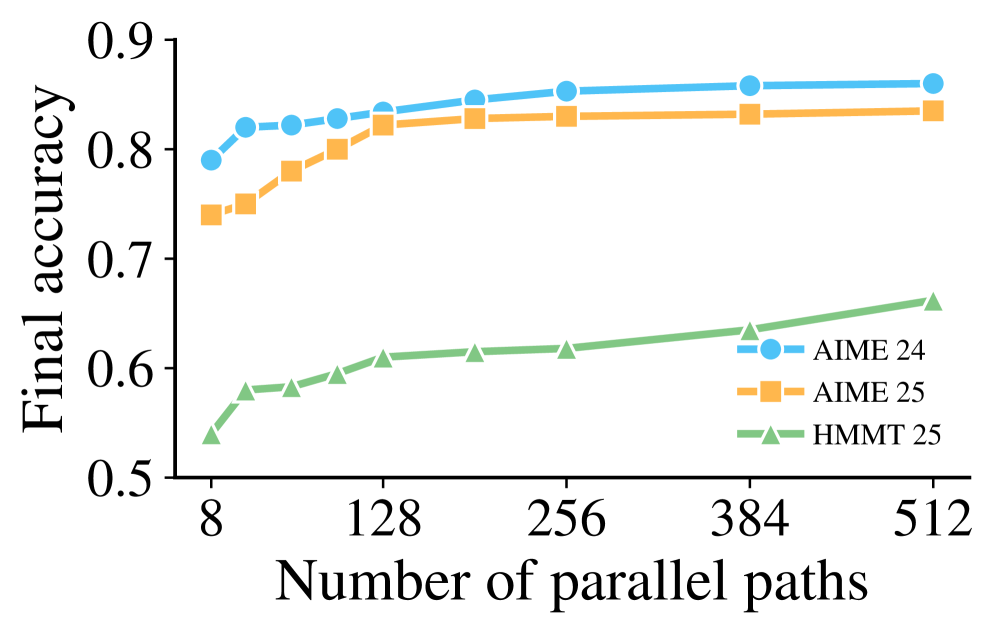

📊 实验亮点
实验结果表明,HyPER在四个混合专家语言模型上,跨多个推理基准测试中,始终实现了卓越的准确性-计算权衡。具体来说,HyPER在减少25%到40%的token使用量的同时,将准确性提高了8%到10%。这些结果表明,HyPER能够有效地平衡探索和利用,提高推理的效率和准确性。
🎯 应用场景
HyPER具有广泛的应用前景,可以应用于各种需要复杂推理的场景,例如问答系统、对话系统、代码生成等。通过提高推理的准确性和效率,HyPER可以显著提升这些系统的性能,并降低计算成本。此外,HyPER的动态扩展-缩减控制策略也可以推广到其他需要探索-利用权衡的问题中,例如强化学习、优化算法等。
📄 摘要(原文)
Scaling test-time compute with multi-path chain-of-thought improves reasoning accuracy, but its effectiveness depends critically on the exploration-exploitation trade-off. Existing approaches address this trade-off in rigid ways: tree-structured search hard-codes exploration through brittle expansion rules that interfere with post-trained reasoning, while parallel reasoning over-explores redundant hypothesis paths and relies on weak answer selection. Motivated by the observation that the optimal balance is phase-dependent and that correct and incorrect reasoning paths often diverge only at late stages, we reformulate test-time scaling as a dynamic expand-reduce control problem over a pool of hypotheses. We propose HyPER, a training-free online control policy for multi-path decoding in mixture-of-experts models that reallocates computation under a fixed budget using lightweight path statistics. HyPER consists of an online controller that transitions from exploration to exploitation as the hypothesis pool evolves, a token-level refinement mechanism that enables efficient generation-time exploitation without full-path resampling, and a length- and confidence-aware aggregation strategy for reliable answer-time exploitation. Experiments on four mixture-of-experts language models across diverse reasoning benchmarks show that HyPER consistently achieves a superior accuracy-compute trade-off, improving accuracy by 8 to 10 percent while reducing token usage by 25 to 40 percent.