Progress Constraints for Reinforcement Learning in Behavior Trees
作者: Finn Rietz, Mart Kartašev, Petter Ögren, Johannes A. Stork
分类: cs.AI
发布日期: 2026-02-06 (更新: 2026-02-11)
💡 一句话要点
提出基于进度约束的强化学习行为树方法,提升任务性能与样本效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 行为树 强化学习 进度约束 机器人控制 自主决策
📋 核心要点
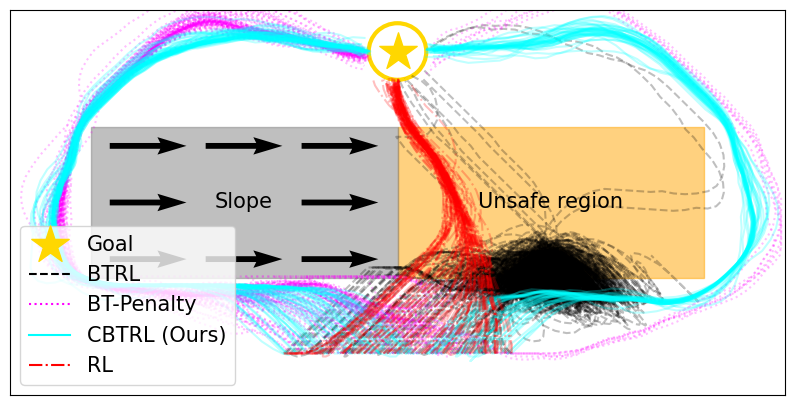
- 现有BT-RL集成方法可能导致控制器相互抵消,降低整体性能,难以保证子目标的实现。
- 论文提出进度约束机制,利用可行性估计器约束动作集,保证BT的收敛性,避免无效动作。
- 实验表明,该方法在性能、样本效率和约束满足度方面优于现有BT-RL集成方法。
📝 摘要(中文)
行为树(BTs)为决策提供了一种结构化和反应式的框架,通常用于根据环境条件在子控制器之间切换。另一方面,强化学习(RL)可以学习到接近最优的控制器,但有时会遇到稀疏奖励、安全探索和长时程信用分配等问题。将BTs与RL相结合具有互利的潜力:BT设计编码了结构化的领域知识,可以简化RL训练,而RL可以自动学习BTs中的控制器。然而,BTs和RL的简单集成可能导致一些控制器相互抵消,可能撤销先前实现的子目标,从而降低整体性能。为了解决这个问题,我们提出了进度约束,这是一种新颖的机制,其中可行性估计器基于理论BT收敛结果约束允许的动作集。在2D概念验证和高保真仓库环境中的经验评估表明,与先前的BT-RL集成方法相比,性能、样本效率和约束满足度均有所提高。
🔬 方法详解
问题定义:论文旨在解决将行为树(BTs)与强化学习(RL)结合时,由于控制器之间的相互干扰导致性能下降的问题。现有方法缺乏对控制器行为的约束,可能出现撤销已完成子目标的情况,导致训练效率低下和最终性能不佳。
核心思路:论文的核心思路是引入“进度约束”,通过可行性估计器来限制RL agent的动作空间。该约束基于行为树的理论收敛结果,确保agent选择的动作能够朝着完成当前子目标的方向前进,避免无效或有害的动作,从而提高学习效率和最终性能。
技术框架:整体框架包含一个行为树,其中叶子节点由RL控制器控制。在每个时间步,可行性估计器根据当前状态和行为树的结构,计算出允许的动作集合。RL agent只能从这个受限的动作集合中选择动作。框架包含以下主要模块:行为树执行器、RL控制器、可行性估计器和环境。
关键创新:最重要的创新点在于“进度约束”机制。与传统的BT-RL集成方法不同,该方法不是直接让RL agent学习所有可能的动作,而是通过理论分析和可行性估计,动态地限制agent的动作空间,从而引导agent朝着正确的方向学习。这种约束机制能够显著提高样本效率和最终性能。
关键设计:可行性估计器的设计是关键。论文基于行为树的收敛性理论,定义了动作的“进度”概念,并设计了相应的估计器来评估每个动作的进度。具体实现细节(如估计器的具体形式、参数设置等)可能因应用场景而异,但核心思想是确保agent选择的动作能够朝着完成当前子目标的方向前进。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的进度约束方法在2D概念验证和高保真仓库环境中均优于现有的BT-RL集成方法。在仓库环境中,该方法在完成任务所需的时间和步数方面均有显著提升,同时能够更好地满足约束条件,避免无效动作。具体性能提升幅度未知,但实验结果表明该方法具有良好的应用潜力。
🎯 应用场景
该研究成果可应用于机器人导航、自动化仓库管理、游戏AI等领域。通过结合行为树的结构化知识和强化学习的自学习能力,可以开发出更加智能、高效和可靠的控制系统。未来,该方法有望扩展到更复杂的任务和环境,实现更高级别的自主决策。
📄 摘要(原文)
Behavior Trees (BTs) provide a structured and reactive framework for decision-making, commonly used to switch between sub-controllers based on environmental conditions. Reinforcement Learning (RL), on the other hand, can learn near-optimal controllers but sometimes struggles with sparse rewards, safe exploration, and long-horizon credit assignment. Combining BTs with RL has the potential for mutual benefit: a BT design encodes structured domain knowledge that can simplify RL training, while RL enables automatic learning of the controllers within BTs. However, naive integration of BTs and RL can lead to some controllers counteracting other controllers, possibly undoing previously achieved subgoals, thereby degrading the overall performance. To address this, we propose progress constraints, a novel mechanism where feasibility estimators constrain the allowed action set based on theoretical BT convergence results. Empirical evaluations in a 2D proof-of-concept and a high-fidelity warehouse environment demonstrate improved performance, sample efficiency, and constraint satisfaction, compared to prior methods of BT-RL integration.