Empirical Analysis of Adversarial Robustness and Explainability Drift in Cybersecurity Classifiers
作者: Mona Rajhans, Vishal Khawarey
分类: cs.CR, cs.AI, cs.LG
发布日期: 2026-02-06
备注: Accepted for publication in 18th ACM International Conference on Agents and Artificial Intelligence (ICAART 2026), Marbella, Spain
💡 一句话要点
针对网络安全分类器,研究对抗鲁棒性与可解释性漂移问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 对抗鲁棒性 可解释性漂移 网络安全分类器 对抗攻击 鲁棒性指数
📋 核心要点
- 网络安全分类器易受对抗攻击影响,导致精度下降和可解释性丧失,现有研究缺乏对鲁棒性和可解释性漂移的深入分析。
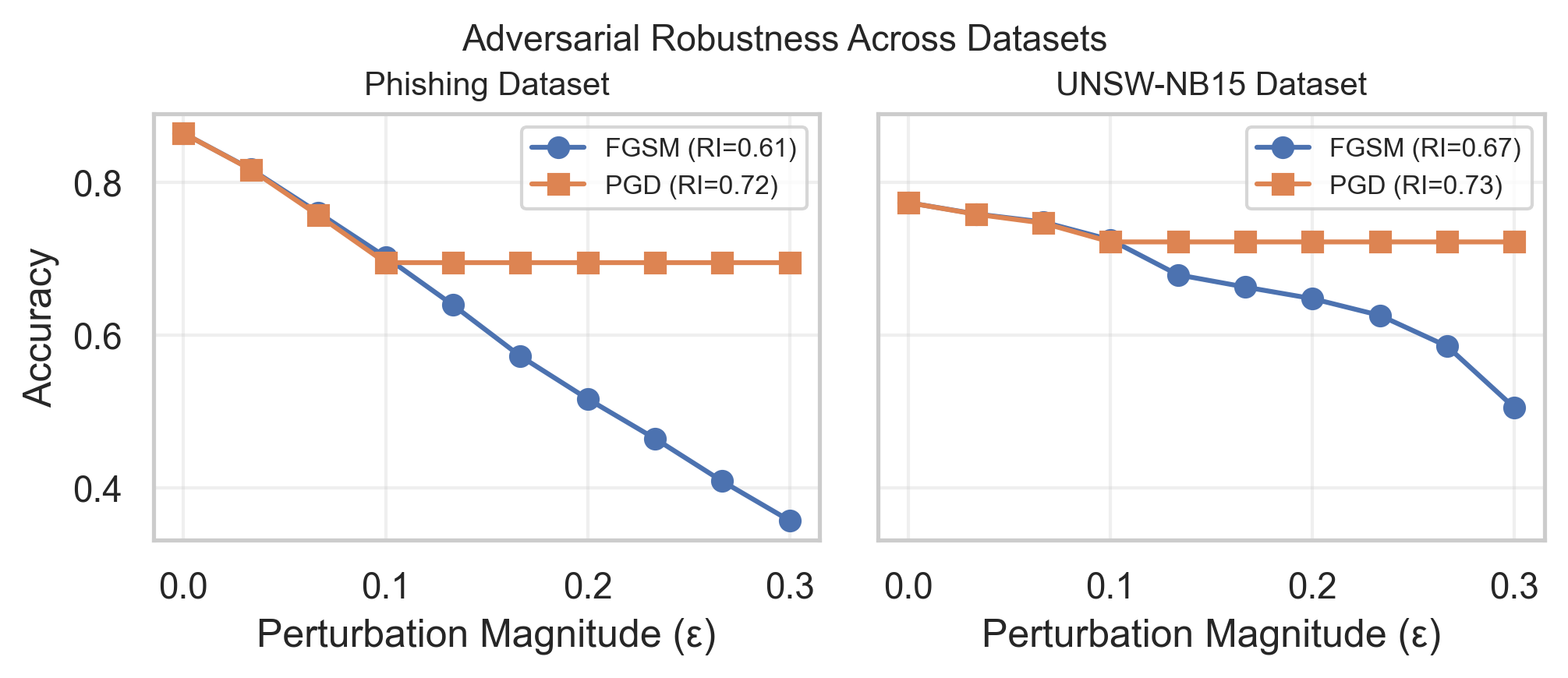
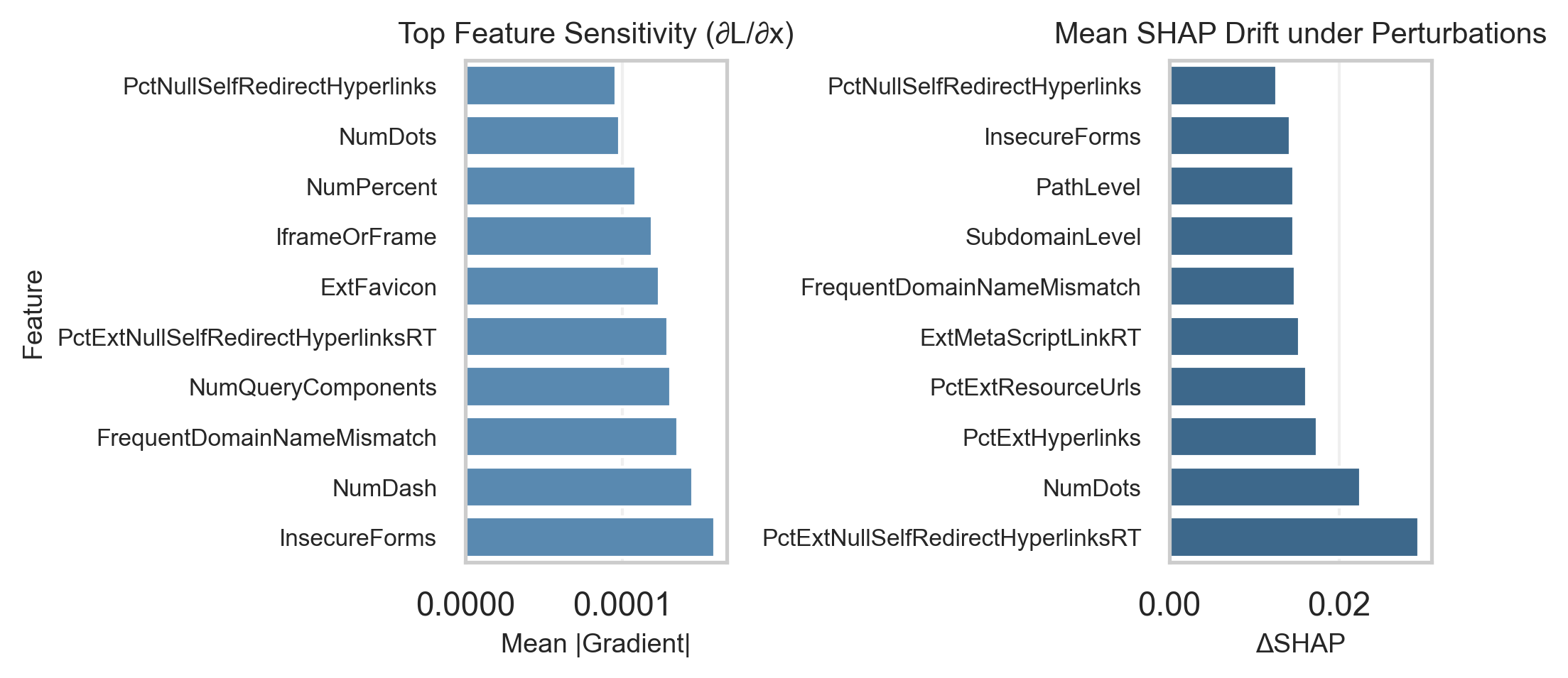
- 通过引入鲁棒性指数(RI)定量评估对抗攻击下的模型性能,并结合梯度和SHAP分析特征敏感性和属性漂移。
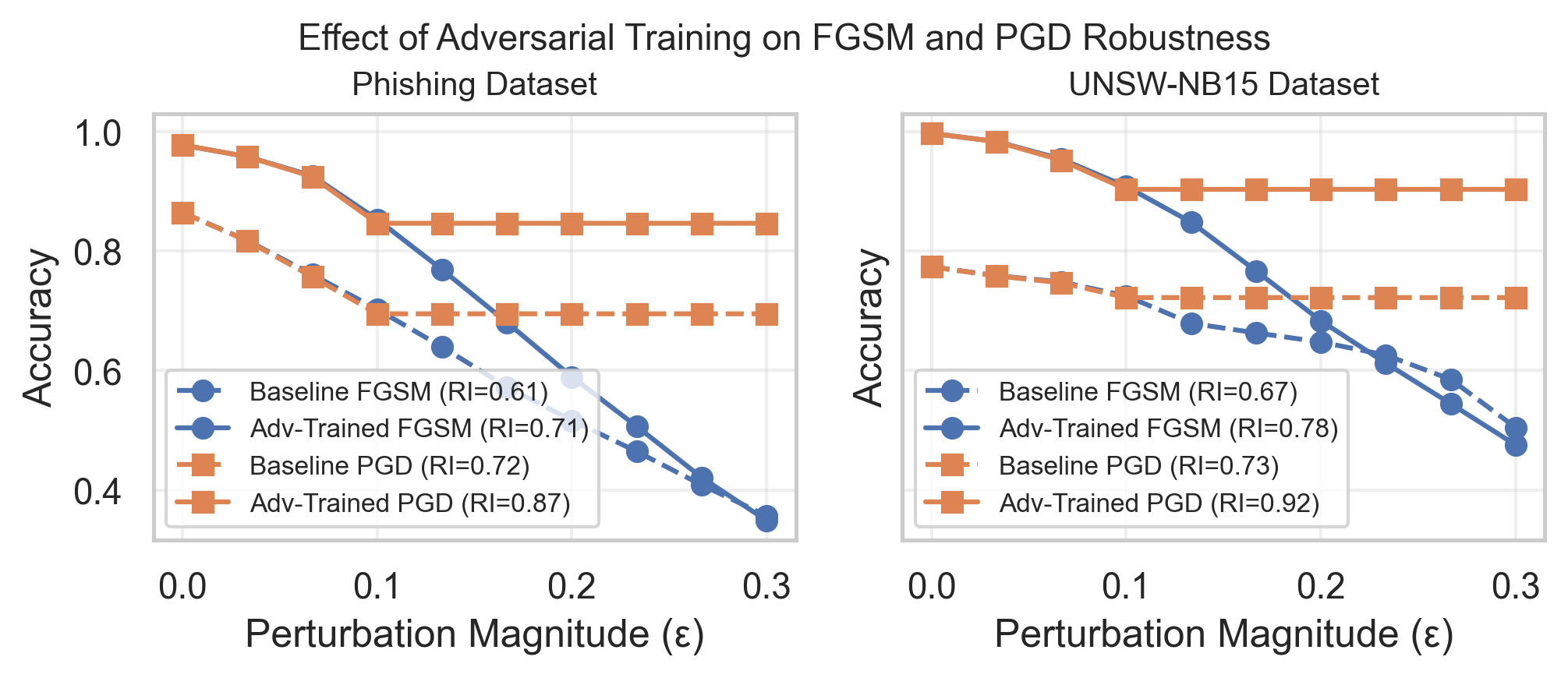
- 实验结果表明,对抗训练能有效提升鲁棒性指数,但同时也揭示了鲁棒性与可解释性之间的权衡关系。
📝 摘要(中文)
机器学习模型越来越多地应用于网络安全领域,如钓鱼检测和网络入侵防御。然而,这些模型仍然容易受到对抗性扰动的影响,即微小的、故意的输入修改,这些修改会降低检测精度并损害可解释性。本文对钓鱼URL分类和网络入侵检测这两个网络安全领域的对抗鲁棒性和可解释性漂移进行了实证研究。我们评估了L(无穷)有界的快速梯度符号法(FGSM)和投影梯度下降(PGD)扰动对模型精度的影响,并引入了一个定量指标,即鲁棒性指数(RI),定义为精度扰动曲线下的面积。基于梯度的特征敏感性和基于SHAP的属性漂移分析揭示了哪些输入特征最容易受到对抗性操纵。在Phishing Websites和UNSW NB15数据集上的实验表明了一致的鲁棒性趋势,对抗训练将RI提高了9%,同时保持了clean-data精度。这些发现突出了鲁棒性和可解释性退化之间的耦合,并强调了在设计可信的、人工智能驱动的网络安全系统时进行定量评估的重要性。
🔬 方法详解
问题定义:论文旨在解决网络安全分类器在面对对抗攻击时鲁棒性不足以及可解释性下降的问题。现有方法缺乏对模型在对抗扰动下的性能退化进行量化分析,并且没有充分研究对抗攻击对模型可解释性的影响。
核心思路:论文的核心思路是通过引入鲁棒性指数(RI)来量化模型在对抗扰动下的鲁棒性,并结合基于梯度的特征敏感性分析和基于SHAP的属性漂移分析来研究对抗攻击对模型可解释性的影响。通过这种方式,可以更全面地评估模型在对抗环境下的性能。
技术框架:论文的技术框架主要包括以下几个阶段:1) 使用FGSM和PGD等对抗攻击方法生成对抗样本;2) 评估对抗样本对模型精度的影响,并计算鲁棒性指数(RI);3) 使用基于梯度的特征敏感性分析和基于SHAP的属性漂移分析来研究对抗攻击对模型可解释性的影响;4) 通过对抗训练来提高模型的鲁棒性,并评估其对RI和可解释性的影响。
关键创新:论文的关键创新在于:1) 提出了鲁棒性指数(RI)这一定量指标,用于评估模型在对抗扰动下的鲁棒性;2) 结合了基于梯度的特征敏感性分析和基于SHAP的属性漂移分析,更全面地研究了对抗攻击对模型可解释性的影响;3) 通过实验验证了对抗训练在提高鲁棒性方面的有效性,并揭示了鲁棒性与可解释性之间的权衡关系。
关键设计:论文使用了L(无穷)范数约束的FGSM和PGD攻击来生成对抗样本。鲁棒性指数(RI)被定义为精度-扰动曲线下的面积,用于量化模型的鲁棒性。基于梯度的特征敏感性分析通过计算输入特征对模型输出的梯度来评估特征的重要性。基于SHAP的属性漂移分析使用SHAP值来衡量每个特征对模型预测的贡献,并分析对抗攻击对特征重要性的影响。对抗训练通过在训练集中加入对抗样本来提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,对抗训练可以将鲁棒性指数(RI)提高高达9%,同时保持clean-data精度。此外,研究还揭示了对抗攻击对模型可解释性的影响,并发现某些输入特征更容易受到对抗性操纵。这些发现强调了在设计网络安全模型时,需要同时考虑鲁棒性和可解释性。
🎯 应用场景
该研究成果可应用于提升网络安全系统中机器学习模型的可靠性和可信度。通过量化模型的鲁棒性和可解释性,可以更好地评估模型在实际应用中的风险,并指导模型的优化和改进。该研究对于构建更安全、更可靠的人工智能驱动的网络安全系统具有重要意义。
📄 摘要(原文)
Machine learning (ML) models are increasingly deployed in cybersecurity applications such as phishing detection and network intrusion prevention. However, these models remain vulnerable to adversarial perturbations small, deliberate input modifications that can degrade detection accuracy and compromise interpretability. This paper presents an empirical study of adversarial robustness and explainability drift across two cybersecurity domains phishing URL classification and network intrusion detection. We evaluate the impact of L (infinity) bounded Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) perturbations on model accuracy and introduce a quantitative metric, the Robustness Index (RI), defined as the area under the accuracy perturbation curve. Gradient based feature sensitivity and SHAP based attribution drift analyses reveal which input features are most susceptible to adversarial manipulation. Experiments on the Phishing Websites and UNSW NB15 datasets show consistent robustness trends, with adversarial training improving RI by up to 9 percent while maintaining clean-data accuracy. These findings highlight the coupling between robustness and interpretability degradation and underscore the importance of quantitative evaluation in the design of trustworthy, AI-driven cybersecurity systems.