Trifuse: Enhancing Attention-Based GUI Grounding via Multimodal Fusion
作者: Longhui Ma, Di Zhao, Siwei Wang, Zhao Lv, Miao Wang
分类: cs.AI, cs.CV
发布日期: 2026-02-06
备注: 17 pages, 10 figures
💡 一句话要点
Trifuse:通过多模态融合增强基于注意力的GUI元素定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI元素定位 多模态融合 注意力机制 OCR 人机交互
📋 核心要点
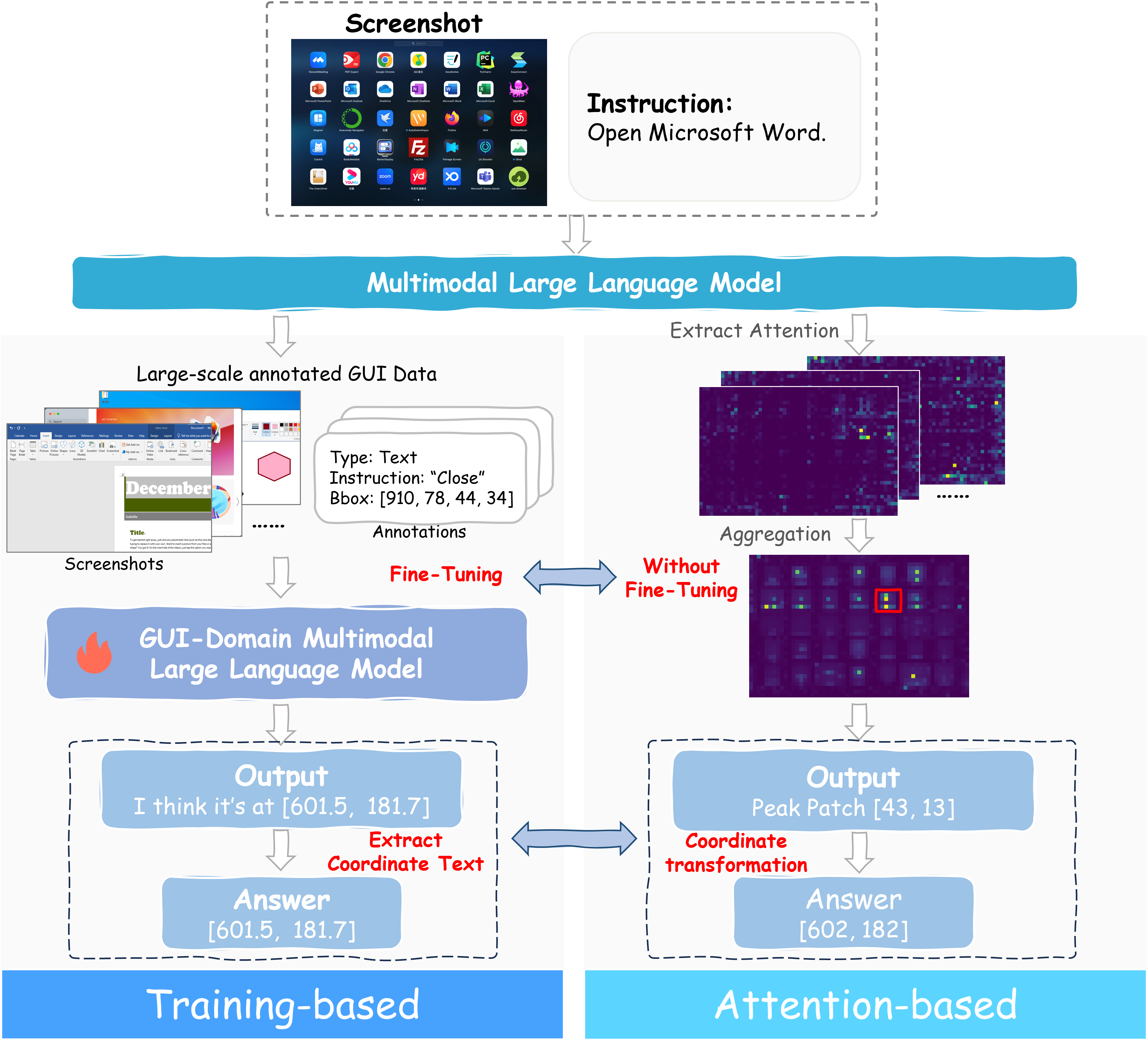
- 现有GUI元素定位方法依赖大量标注数据微调MLLM,泛化性差,且基于注意力的方法缺乏显式空间锚点。
- Trifuse通过融合注意力、OCR文本和图标语义,利用共识-单峰策略,增强定位的可靠性和准确性。
- 实验表明,Trifuse无需微调即可在多个基准测试中取得良好性能,并验证了OCR和标题线索的有效性。
📝 摘要(中文)
GUI元素定位旨在将自然语言指令映射到正确的界面元素,是GUI代理的感知基础。现有方法主要依赖于使用大规模GUI数据集微调多模态大型语言模型(MLLM)来预测目标元素坐标,这种方法数据密集型且泛化能力差。最近基于注意力机制的方法利用MLLM注意力机制中的定位信号,无需特定任务的微调,但由于GUI图像中缺乏显式和互补的空间锚点,导致可靠性较低。为了解决这个限制,我们提出了Trifuse,一个基于注意力的定位框架,它显式地集成了互补的空间锚点。Trifuse通过共识-单峰(CS)融合策略整合了注意力、OCR衍生的文本线索和图标级标题语义,该策略在保持清晰定位峰值的同时,强制执行跨模态一致性。在四个定位基准上的大量评估表明,Trifuse在没有特定任务微调的情况下实现了强大的性能,大大减少了对昂贵标注数据的依赖。此外,消融研究表明,结合OCR和标题线索可以持续提高基于注意力的定位性能,突出了其作为GUI定位通用框架的有效性。
🔬 方法详解
问题定义:GUI元素定位旨在将自然语言指令映射到GUI界面中的特定元素。现有方法,特别是基于微调多模态大语言模型(MLLM)的方法,需要大量的标注数据,并且在面对未见过的GUI界面时泛化能力较差。而基于注意力机制的方法虽然避免了微调,但由于GUI图像缺乏明确的空间锚点,导致定位的可靠性不足。
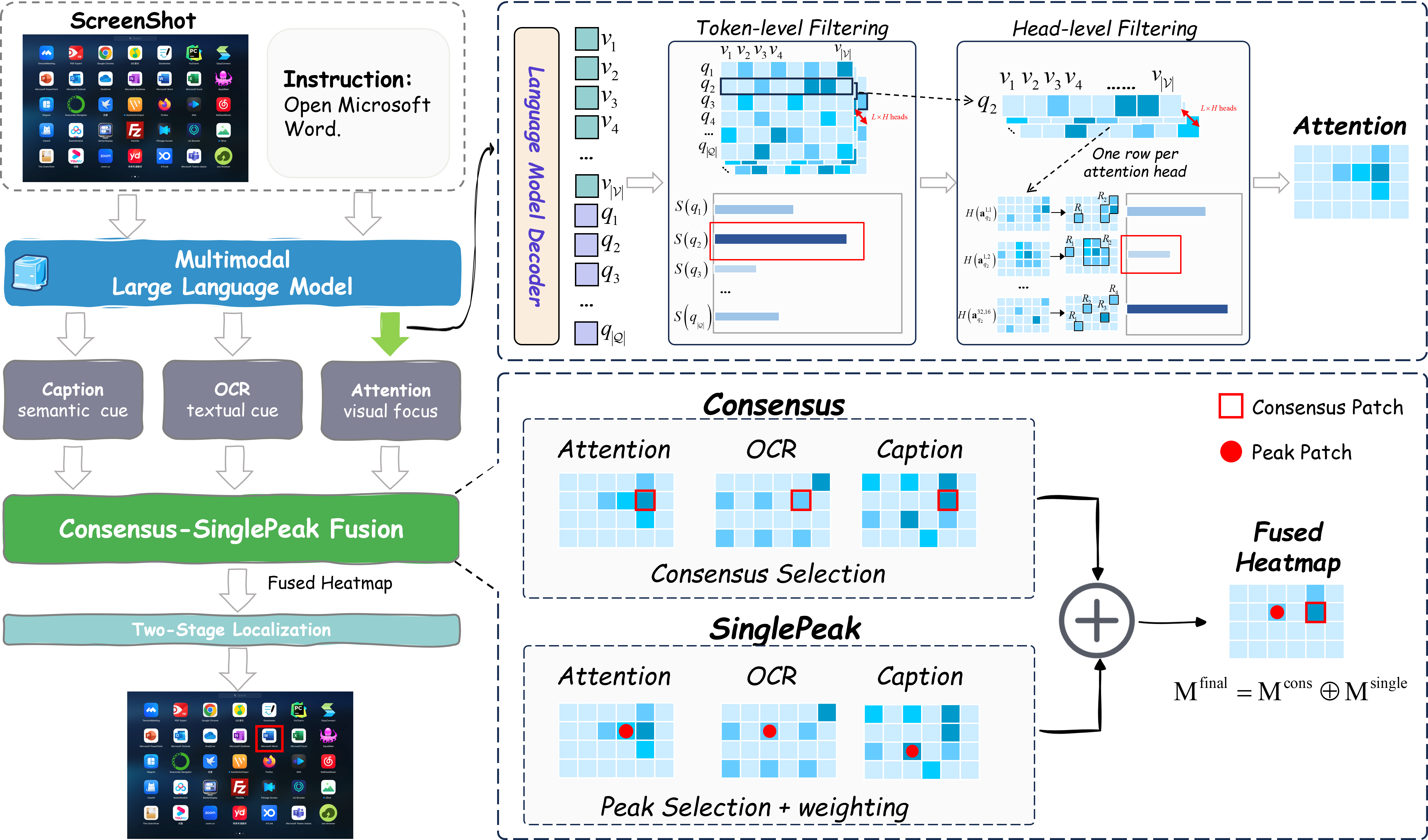
核心思路:Trifuse的核心思路是通过显式地整合互补的空间锚点来增强基于注意力的GUI元素定位。具体来说,它融合了视觉注意力、OCR提取的文本信息以及图标级别的语义信息,从而提供更丰富、更可靠的定位线索。这种多模态融合的设计旨在克服单一模态信息的局限性,提高定位的准确性和鲁棒性。
技术框架:Trifuse框架主要包含三个模态的输入:视觉注意力图、OCR提取的文本信息和图标级别的语义信息。首先,从预训练的MLLM中提取视觉注意力图,该注意力图反映了模型对图像不同区域的关注程度。其次,利用OCR技术从GUI图像中提取文本信息,这些文本信息可以作为定位的重要线索。然后,对GUI中的图标进行语义标注,提供更细粒度的语义信息。最后,通过一个名为“共识-单峰”(Consensus-SinglePeak, CS)的融合策略,将这三个模态的信息进行整合,生成最终的定位结果。
关键创新:Trifuse的关键创新在于其多模态融合策略以及共识-单峰(CS)融合方法。与现有方法相比,Trifuse不是仅仅依赖于视觉注意力,而是显式地引入了OCR文本和图标语义作为互补的空间锚点。CS融合策略旨在强制跨模态的一致性,同时保持清晰的定位峰值,从而提高定位的准确性和可靠性。这种融合策略使得Trifuse能够在没有特定任务微调的情况下,实现强大的定位性能。
关键设计:共识-单峰(CS)融合策略是Trifuse的关键设计。该策略首先计算不同模态之间的相似度,然后利用这些相似度来调整各个模态的权重。具体来说,对于每个候选区域,CS策略会计算其在不同模态下的得分,并选择得分最高的区域作为最终的定位结果。此外,Trifuse还使用了预训练的MLLM作为视觉注意力的提取器,并采用了标准的OCR技术和图标语义标注方法。损失函数方面,Trifuse主要关注如何最大化不同模态之间的共识,并最小化定位结果的不确定性。
🖼️ 关键图片

📊 实验亮点
Trifuse在四个GUI元素定位基准测试中取得了显著的性能提升,无需特定任务的微调。消融实验表明,加入OCR和图标语义信息后,定位精度得到持续提高,验证了多模态融合的有效性。实验结果表明,Trifuse在低资源场景下具有很强的竞争力,能够有效减少对大规模标注数据的依赖。
🎯 应用场景
Trifuse在GUI自动化测试、辅助技术、人机交互等领域具有广泛的应用前景。它可以帮助自动化测试工具更准确地定位GUI元素,提高测试效率和覆盖率。对于视觉障碍用户,Trifuse可以辅助他们更方便地操作GUI界面。此外,Trifuse还可以用于开发更智能的GUI代理,实现更自然、更高效的人机交互。
📄 摘要(原文)
GUI grounding maps natural language instructions to the correct interface elements, serving as the perception foundation for GUI agents. Existing approaches predominantly rely on fine-tuning multimodal large language models (MLLMs) using large-scale GUI datasets to predict target element coordinates, which is data-intensive and generalizes poorly to unseen interfaces. Recent attention-based alternatives exploit localization signals in MLLMs attention mechanisms without task-specific fine-tuning, but suffer from low reliability due to the lack of explicit and complementary spatial anchors in GUI images. To address this limitation, we propose Trifuse, an attention-based grounding framework that explicitly integrates complementary spatial anchors. Trifuse integrates attention, OCR-derived textual cues, and icon-level caption semantics via a Consensus-SinglePeak (CS) fusion strategy that enforces cross-modal agreement while retaining sharp localization peaks. Extensive evaluations on four grounding benchmarks demonstrate that Trifuse achieves strong performance without task-specific fine-tuning, substantially reducing the reliance on expensive annotated data. Moreover, ablation studies reveal that incorporating OCR and caption cues consistently improves attention-based grounding performance across different backbones, highlighting its effectiveness as a general framework for GUI grounding.