Compound Deception in Elite Peer Review: A Failure Mode Taxonomy of 100 Fabricated Citations at NeurIPS 2025
作者: Samar Ansari
分类: cs.DL, cs.AI
发布日期: 2026-02-05
💡 一句话要点
揭示AI生成文献引用欺骗:NeurIPS 2025中100个伪造引用的失效模式分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成内容 文献引用 学术不端 同行评审 失效模式分析
📋 核心要点
- 大型语言模型(LLMs)在学术写作中被广泛使用,但它们经常产生幻觉,生成不存在的文献引用,这给学术诚信带来了挑战。
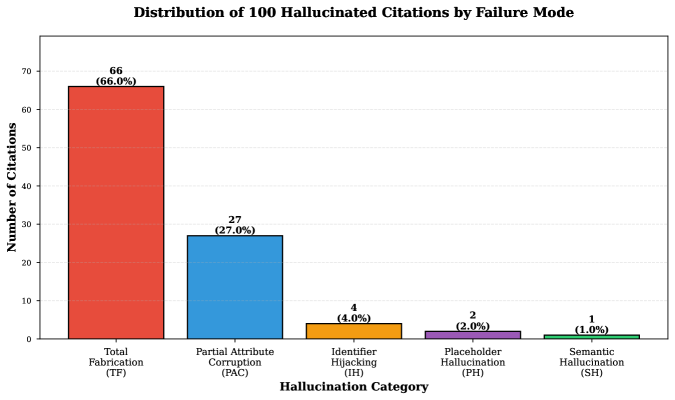
- 该研究通过分析NeurIPS 2025会议论文中出现的100个AI生成的伪造引用,提出了一个五类失效模式分类法,揭示了引用捏造的复杂性。
- 研究发现所有伪造引用都表现出复合失效模式,表明现有同行评审机制在检测此类欺骗性引用方面存在不足,并建议采用自动引用验证。
📝 摘要(中文)
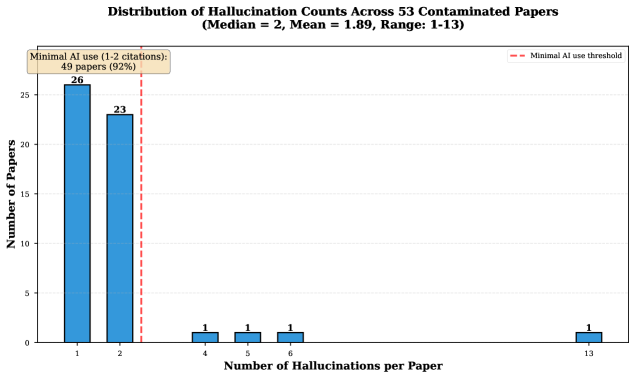
本研究分析了2025年神经信息处理系统会议(NeurIPS)接收论文中出现的100个由AI生成、捏造的文献引用。尽管每篇论文都经过3-5位专家研究人员的评审,但这些伪造的引用仍然未被发现,出现在53篇已发表的论文中(约占所有接收论文的1%)。我们开发了一个五类分类法,根据失效模式对这些捏造的引用进行分类:完全捏造(66%)、部分属性篡改(27%)、标识符劫持(4%)、占位符捏造(2%)和语义捏造(1%)。分析揭示了一个关键发现:每个捏造的引用(100%)都表现出复合失效模式。次要特征的分布以语义捏造(63%)和标识符劫持(29%)为主,它们经常与完全捏造同时出现,以制造一种貌似合理和虚假的可验证性。这些复合结构同时利用了多种验证启发式方法,解释了为什么同行评审未能检测到它们。分布呈现出双峰模式:92%的受污染论文包含1-2个捏造的引用(少量AI使用),而8%的论文包含4-13个捏造的引用(严重依赖)。这些发现表明,当前的同行评审过程不包括有效的引用验证,并且该问题已从NeurIPS扩展到其他主要会议、政府报告和专业咨询。我们建议在提交时强制执行自动引用验证,作为一种可实施的解决方案,以防止伪造的引用在科学文献中变得常态。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在学术写作中生成虚假引用,导致学术不端行为的问题。现有同行评审机制难以有效检测这些虚假引用,使得它们能够混入高质量的学术论文中,对学术界的信任和知识积累造成潜在威胁。
核心思路:论文的核心思路是通过对实际案例进行分析,构建一个失效模式分类法,揭示虚假引用的构成方式和特点。通过理解这些模式,可以更好地设计检测方法,并改进现有的评审流程。同时,论文强调了复合失效模式的重要性,即虚假引用往往不是单一的错误,而是多种错误的组合,这使得它们更难被发现。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:从NeurIPS 2025接收的论文中识别出包含虚假引用的论文。2) 案例分析:对100个虚假引用进行深入分析,识别其失效模式。3) 分类法构建:基于分析结果,构建一个五类失效模式分类法。4) 统计分析:统计不同失效模式的分布情况,特别是复合失效模式的出现频率。5) 解决方案提出:基于分析结果,提出自动引用验证的解决方案。
关键创新:论文的关键创新在于:1) 提出了一个针对AI生成虚假引用的失效模式分类法,为理解和检测此类引用提供了理论基础。2) 揭示了复合失效模式的存在,强调了虚假引用的复杂性和欺骗性。3) 基于实际案例分析,提出了自动引用验证的解决方案,具有实际应用价值。
关键设计:论文的关键设计包括:1) 失效模式分类法的五类划分:完全捏造、部分属性篡改、标识符劫持、占位符捏造和语义捏造。2) 复合失效模式的分析方法:通过分析每个虚假引用中包含的多种失效模式,揭示其欺骗性。3) 自动引用验证的实现方案:建议在论文提交时强制执行自动引用验证,以防止虚假引用进入学术文献。
🖼️ 关键图片

📊 实验亮点
研究发现,NeurIPS 2025会议接收的论文中约1%包含AI生成的虚假引用,且所有虚假引用都表现出复合失效模式。其中,66%为完全捏造,27%为部分属性篡改,语义捏造和标识符劫持分别占63%和29%(作为次要特征)。92%的受污染论文包含1-2个虚假引用,而8%包含4-13个,表明AI使用程度不一。
🎯 应用场景
该研究成果可应用于学术出版领域,通过在论文提交和评审阶段引入自动引用验证工具,提高学术论文的质量和可信度。此外,该研究对于识别和防范AI生成的虚假信息具有指导意义,可应用于信息安全、舆情分析等领域,以维护信息的真实性和可靠性。
📄 摘要(原文)
Large language models (LLMs) are increasingly used in academic writing workflows, yet they frequently hallucinate by generating citations to sources that do not exist. This study analyzes 100 AI-generated hallucinated citations that appeared in papers accepted by the 2025 Conference on Neural Information Processing Systems (NeurIPS), one of the world's most prestigious AI conferences. Despite review by 3-5 expert researchers per paper, these fabricated citations evaded detection, appearing in 53 published papers (approx. 1% of all accepted papers). We develop a five-category taxonomy that classifies hallucinations by their failure mode: Total Fabrication (66%), Partial Attribute Corruption (27%), Identifier Hijacking (4%), Placeholder Hallucination (2%), and Semantic Hallucination (1%). Our analysis reveals a critical finding: every hallucination (100%) exhibited compound failure modes. The distribution of secondary characteristics was dominated by Semantic Hallucination (63%) and Identifier Hijacking (29%), which often appeared alongside Total Fabrication to create a veneer of plausibility and false verifiability. These compound structures exploit multiple verification heuristics simultaneously, explaining why peer review fails to detect them. The distribution exhibits a bimodal pattern: 92% of contaminated papers contain 1-2 hallucinations (minimal AI use) while 8% contain 4-13 hallucinations (heavy reliance). These findings demonstrate that current peer review processes do not include effective citation verification and that the problem extends beyond NeurIPS to other major conferences, government reports, and professional consulting. We propose mandatory automated citation verification at submission as an implementable solution to prevent fabricated citations from becoming normalized in scientific literature.