Quantum Reinforcement Learning with Transformers for the Capacitated Vehicle Routing Problem
作者: Eva Andrés
分类: cs.AI, cs.ET
发布日期: 2026-02-05
备注: 22 pages, 12 figures
💡 一句话要点
提出基于Transformer的量子强化学习方法,解决带容量约束车辆路径问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子强化学习 车辆路径问题 Transformer 组合优化 A2C 混合量子-经典算法 物流优化
📋 核心要点
- 传统车辆路径问题求解方法难以有效处理大规模、高复杂度的带容量约束场景。
- 利用量子计算的优势,结合Transformer架构,设计混合量子-经典强化学习智能体。
- 实验表明,量子增强模型在路由距离、紧凑性和重叠度上优于经典模型,展现潜力。
📝 摘要(中文)
本文比较了经典和量子强化学习(RL)方法在解决带容量约束车辆路径问题(CVRP)中的应用。具体而言,实现了经典、全量子和混合三种变体的优势演员-评论家(A2C)智能体,并集成Transformer架构,通过自注意力和交叉注意力机制捕捉车辆、客户和仓库之间的关系。实验重点关注具有容量约束的多车辆场景,考虑了20个客户和4辆车,并进行了十次独立运行。通过路由距离、路线紧凑性和路线重叠来评估性能。结果表明,所有三种方法都能够学习有效的路由策略。然而,量子增强模型优于经典基线,并产生更鲁棒的路线组织,其中混合架构在距离、紧凑性和路线重叠方面实现了最佳整体性能。除了定量改进之外,定性可视化显示,基于量子的模型生成了更结构化和连贯的路由解决方案。这些发现突出了混合量子-经典强化学习模型在解决复杂组合优化问题(如CVRP)方面的潜力。
🔬 方法详解
问题定义:论文旨在解决带容量约束的车辆路径问题(CVRP)。现有方法在处理大规模问题时计算复杂度高,难以找到全局最优解,尤其是在车辆数量和客户数量增加时。传统方法可能陷入局部最优,导致路线效率低下,增加运输成本。
核心思路:论文的核心思路是将量子计算的优势与经典强化学习相结合,利用量子计算加速优化过程,并使用Transformer架构捕捉车辆、客户和仓库之间的复杂关系。通过这种混合方法,旨在找到更优的车辆路径,降低运输成本,提高效率。
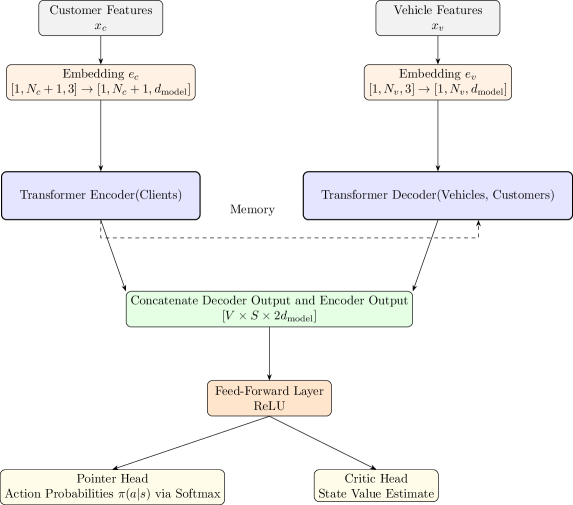
技术框架:整体框架包括三个主要变体:经典A2C、全量子A2C和混合量子-经典A2C。所有变体都使用Transformer架构作为策略网络和价值网络。Transformer通过自注意力和交叉注意力机制处理输入数据,生成动作(车辆路径)。训练过程基于优势演员-评论家算法,通过与环境交互不断优化策略。
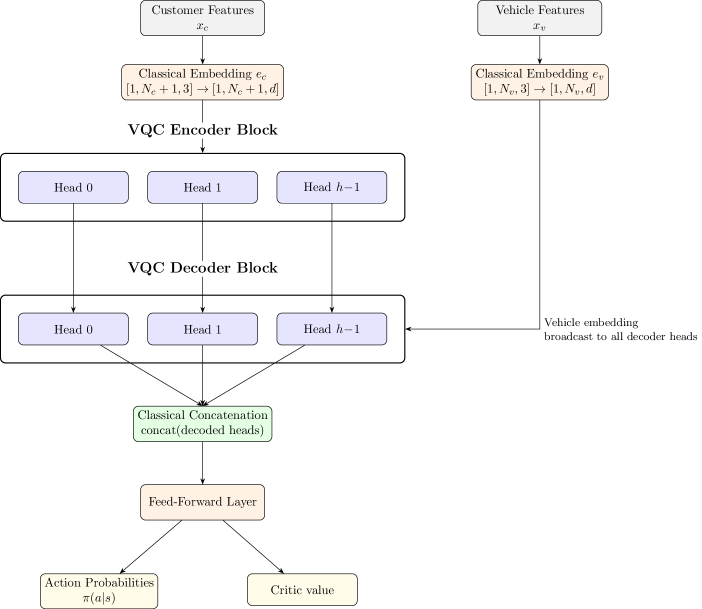
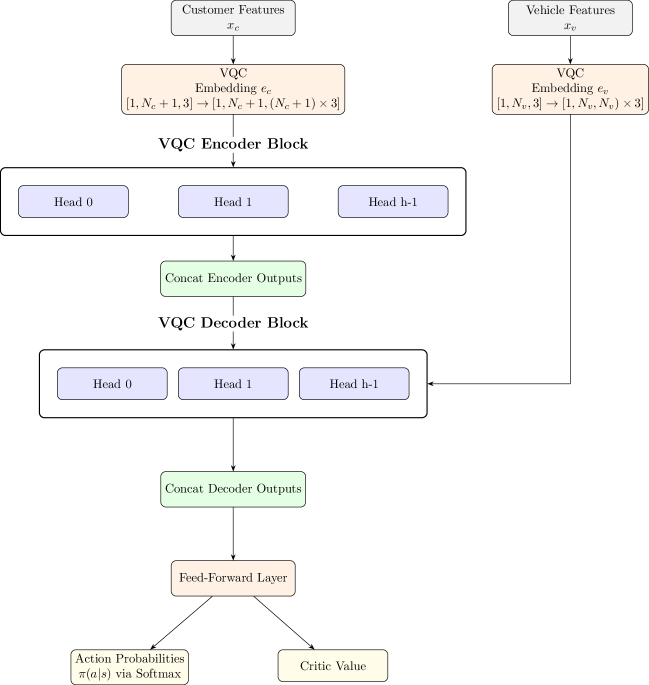
关键创新:最重要的技术创新点在于混合量子-经典A2C架构。该架构利用量子计算加速部分计算过程,同时保留经典计算的灵活性。与纯经典方法相比,量子增强可以更快地探索解空间,找到更优的解。与纯量子方法相比,混合方法更容易实现和部署。
关键设计:论文使用了优势演员-评论家(A2C)算法,其中演员网络和评论家网络都基于Transformer架构。Transformer的输入包括车辆、客户和仓库的位置信息。损失函数包括演员网络的策略梯度损失和评论家网络的均方误差损失。实验中,使用了特定的超参数设置,例如学习率、折扣因子和探索率,以优化模型的训练效果。具体量子线路的设计细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,量子增强模型在解决带容量约束的车辆路径问题上优于经典基线。具体而言,混合量子-经典A2C架构在路由距离、路线紧凑性和路线重叠方面均取得了最佳性能。定性可视化结果也显示,量子模型能够生成更结构化和连贯的路由解决方案。虽然论文没有给出具体的性能提升百分比,但整体结果表明量子计算在优化车辆路径问题方面具有潜力。
🎯 应用场景
该研究成果可应用于物流配送、供应链管理、交通运输等领域。通过优化车辆路径,可以降低运输成本、减少能源消耗、提高配送效率。尤其是在城市物流、冷链运输等对时效性要求较高的场景中,该方法具有重要的应用价值。未来,该研究可以进一步扩展到更复杂的车辆路径问题,例如考虑时间窗、多车场等约束。
📄 摘要(原文)
This paper addresses the Capacitated Vehicle Routing Problem (CVRP) by comparing classical and quantum Reinforcement Learning (RL) approaches. An Advantage Actor-Critic (A2C) agent is implemented in classical, full quantum, and hybrid variants, integrating transformer architectures to capture the relationships between vehicles, clients, and the depot through self- and cross-attention mechanisms. The experiments focus on multi-vehicle scenarios with capacity constraints, considering 20 clients and 4 vehicles, and are conducted over ten independent runs. Performance is assessed using routing distance, route compactness, and route overlap. The results show that all three approaches are capable of learning effective routing policies. However, quantum-enhanced models outperform the classical baseline and produce more robust route organization, with the hybrid architecture achieving the best overall performance across distance, compactness, and route overlap. In addition to quantitative improvements, qualitative visualizations reveal that quantum-based models generate more structured and coherent routing solutions. These findings highlight the potential of hybrid quantum-classical reinforcement learning models for addressing complex combinatorial optimization problems such as the CVRP.