A Guide to Large Language Models in Modeling and Simulation: From Core Techniques to Critical Challenges
作者: Philippe J. Giabbanelli
分类: cs.AI
发布日期: 2026-02-05
备注: Book chapter. Accepted in Artificial Intelligence in Modeling and Simulation, Philippe J. Giabbanelli and Istvan David (eds). Series on Simulation Foundations, Methods and Applications. Springer, Cham. Series ISSN: 2195-2817
💡 一句话要点
为建模与仿真应用提供LLM使用指南,强调设计原则、诊断策略和评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 建模与仿真 提示工程 知识增强 RAG LoRA 非确定性 超参数优化
📋 核心要点
- 现有LLM在建模与仿真应用中存在非确定性、知识增强和数据处理等方面的挑战。
- 论文提出一套LLM使用指南,强调有原则的设计选择、诊断策略和经验评估。
- 该指南旨在帮助建模人员在建模与仿真任务中更有效地利用LLM,避免常见陷阱。
📝 摘要(中文)
大型语言模型(LLM)已迅速成为研究人员和从业者的常用工具。提示工程、温度参数和少样本示例等概念已被广泛认知,LLM也越来越多地应用于建模与仿真(M&S)工作流程中。然而,看似简单的实践可能会引入微妙的问题、不必要的复杂性,甚至导致较差的结果。例如,添加更多数据可能会适得其反(如通过模型崩溃降低性能或无意中消除现有的安全措施),在没有事先评估模型已知内容的情况下花费时间微调模型可能是不必要的,将温度设置为0不足以使LLM具有确定性,提供大量的M&S数据作为输入可能过多(LLM无法关注所有内容),但简单的简化可能会丢失信息。本文旨在为如何使用LLM提供全面而实用的指导,重点是M&S应用。我们讨论了常见的混淆来源,包括非确定性、知识增强(包括RAG和LoRA)、M&S数据的分解以及超参数设置。我们强调有原则的设计选择、诊断策略和经验评估,旨在帮助建模人员就何时、如何以及是否依赖LLM做出明智的决策。
🔬 方法详解
问题定义:现有方法在建模与仿真(M&S)领域应用LLM时,存在诸多问题。例如,简单地增加数据量可能导致模型性能下降,过度简化数据可能丢失关键信息,盲目微调模型可能浪费资源,以及难以保证LLM输出的确定性。这些问题阻碍了LLM在M&S领域的有效应用。
核心思路:论文的核心思路是提供一套系统性的LLM使用指南,帮助研究人员和从业者在M&S应用中做出明智的决策。该指南强调在应用LLM之前进行充分的评估和诊断,并根据具体任务选择合适的技术和参数设置。
技术框架:论文并没有提出一个具体的模型或算法框架,而是提供了一套通用的指导原则和最佳实践。这些原则涵盖了LLM应用的各个方面,包括数据准备、模型选择、提示工程、知识增强、超参数调整和结果评估。论文还讨论了常见的混淆来源,并提供了相应的解决方案。
关键创新:论文的创新之处在于其系统性和实用性。它不是简单地介绍LLM的技术细节,而是深入分析了LLM在M&S应用中可能遇到的问题,并提供了具体的解决方案和建议。这种以问题为导向的方法有助于研究人员和从业者更好地理解和应用LLM。
关键设计:论文强调了以下关键设计:1) 针对M&S数据的特点进行数据分解和预处理;2) 根据任务需求选择合适的知识增强方法(如RAG或LoRA);3) 通过诊断策略评估LLM的性能和可靠性;4) 基于经验评估调整超参数设置,以获得最佳结果。
🖼️ 关键图片
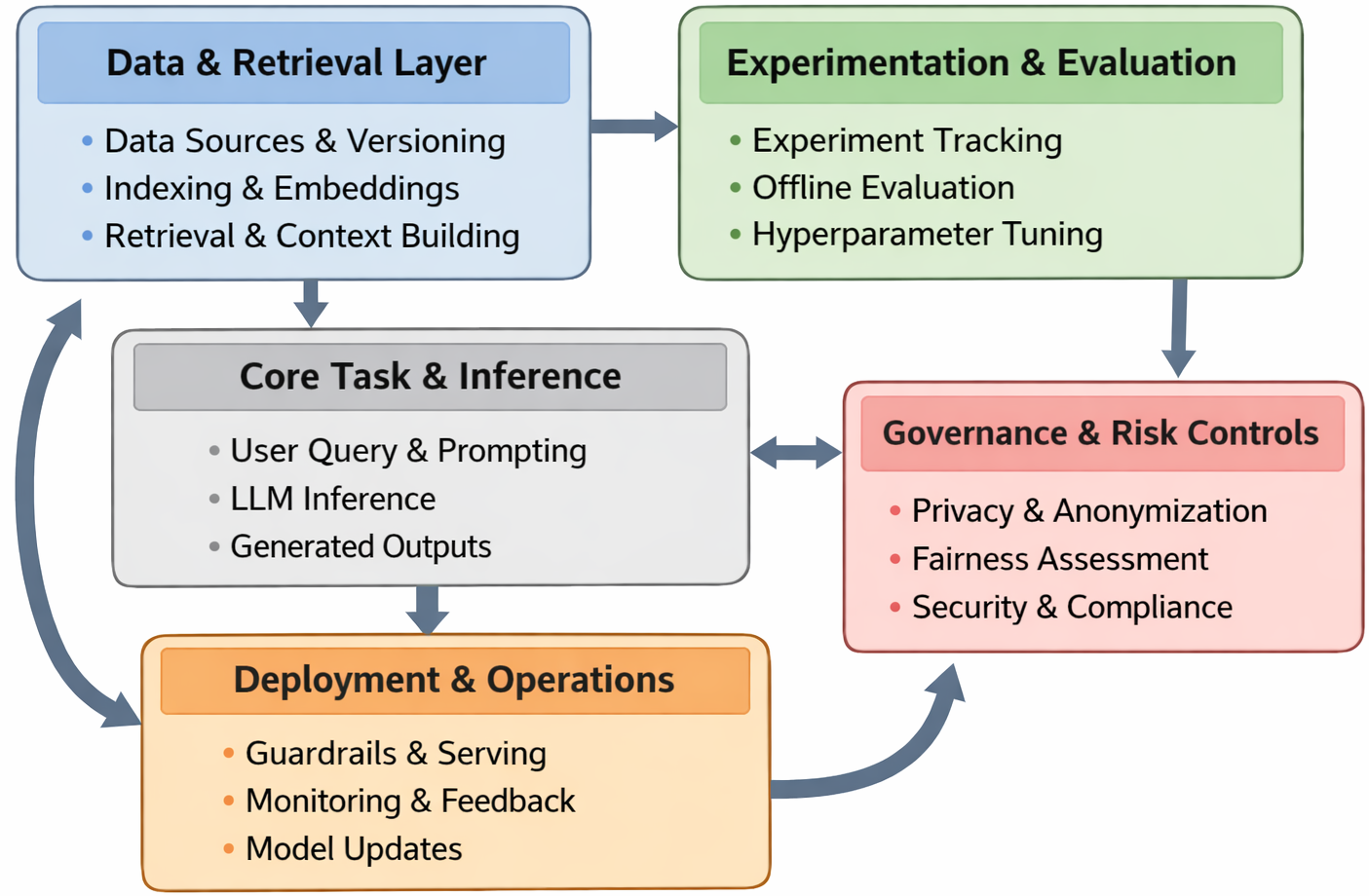
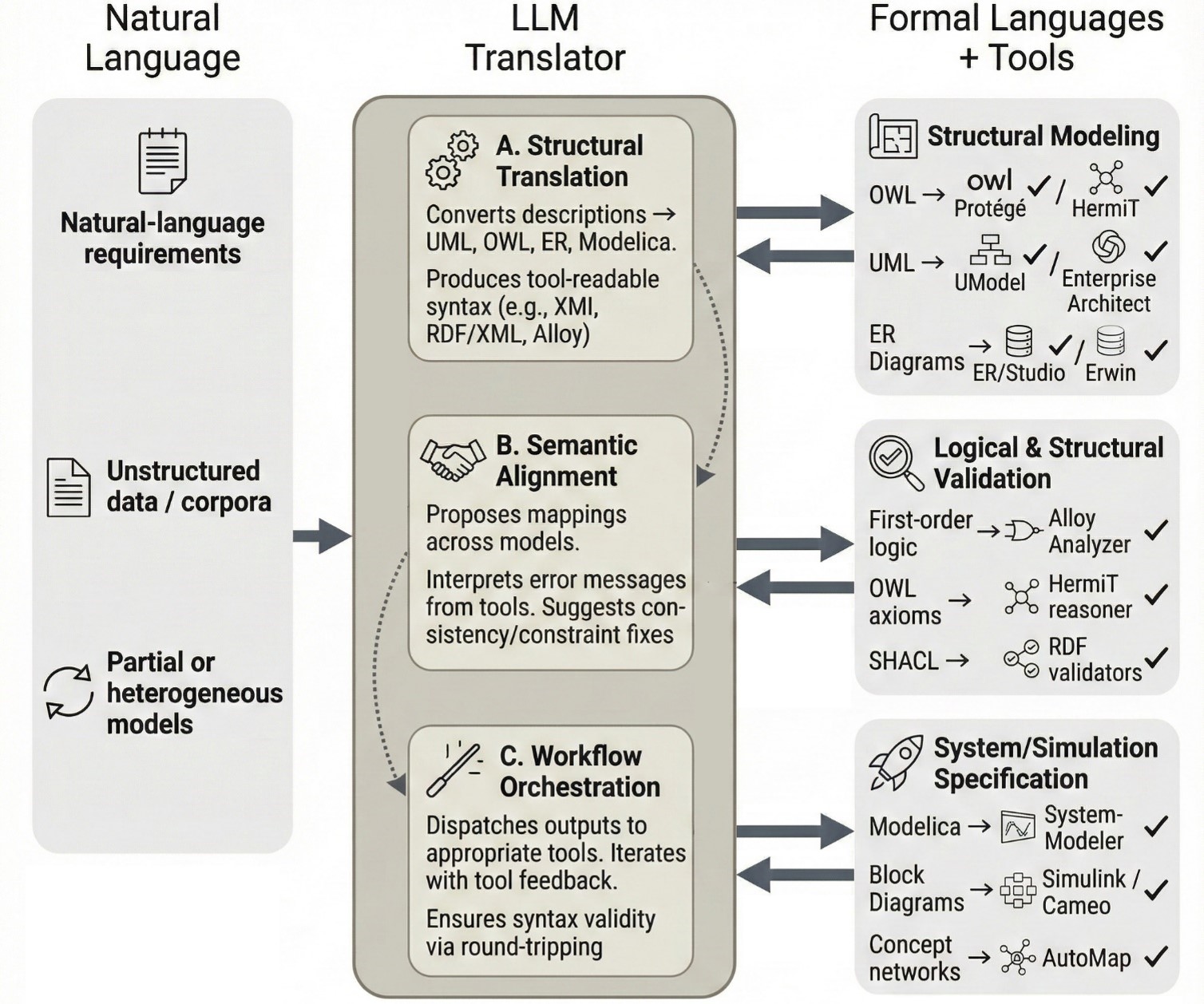
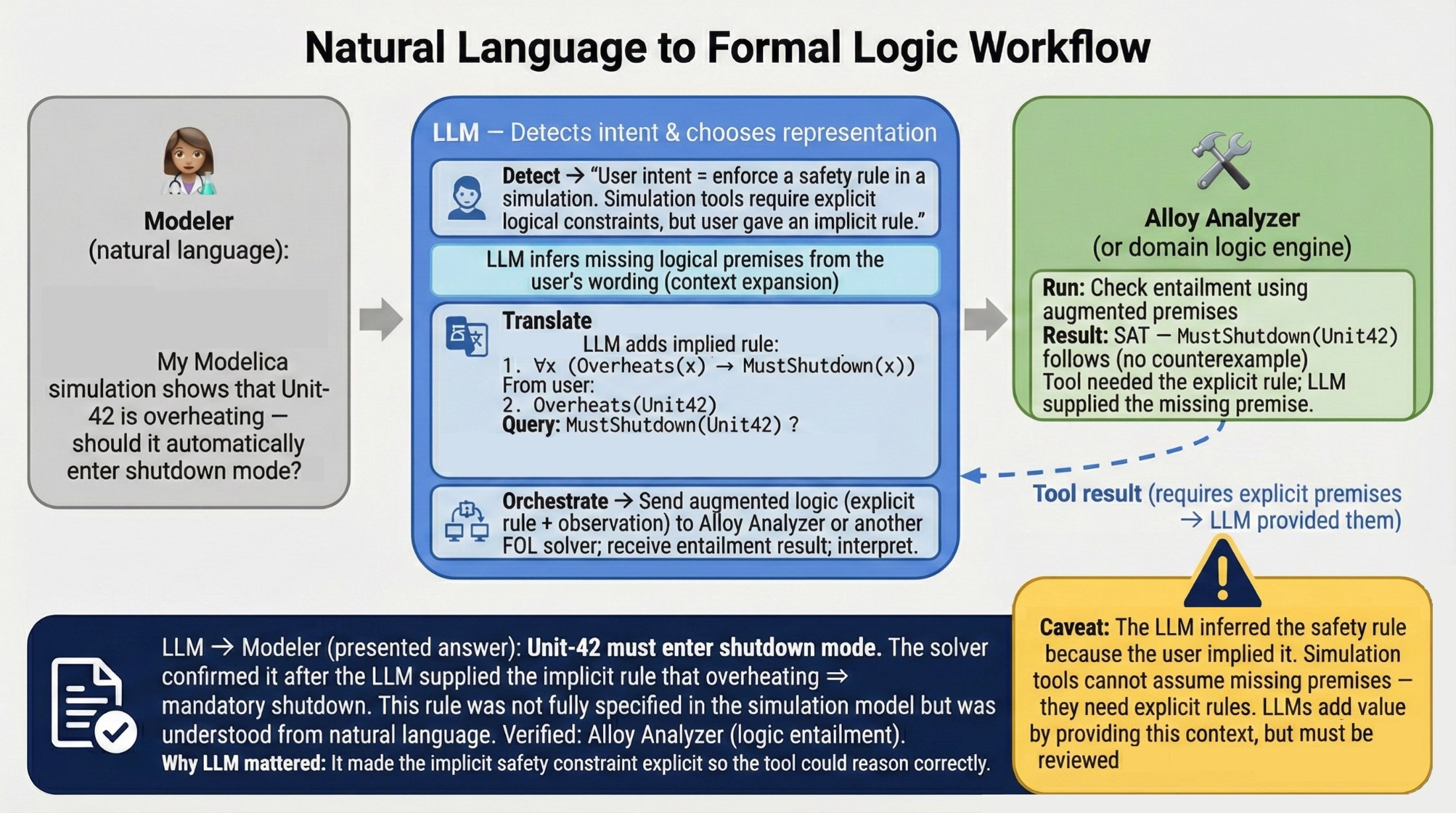
📊 实验亮点
论文重点在于提供实践指导而非实验结果。其亮点在于对LLM在建模与仿真应用中常见问题的深入分析,以及针对这些问题提出的实用解决方案。例如,论文讨论了如何避免因数据量过大而导致的性能下降,以及如何选择合适的知识增强方法来提高模型的准确性。这些指导对于实际应用具有重要价值。
🎯 应用场景
该研究成果可广泛应用于各种建模与仿真领域,例如物理仿真、社会行为建模、经济预测等。通过遵循本文提出的指南,研究人员和从业者可以更有效地利用LLM来提高建模与仿真的效率和准确性,从而为科学研究、工程设计和决策支持提供更有力的支持。
📄 摘要(原文)
Large language models (LLMs) have rapidly become familiar tools to researchers and practitioners. Concepts such as prompting, temperature, or few-shot examples are now widely recognized, and LLMs are increasingly used in Modeling & Simulation (M&S) workflows. However, practices that appear straightforward may introduce subtle issues, unnecessary complexity, or may even lead to inferior results. Adding more data can backfire (e.g., deteriorating performance through model collapse or inadvertently wiping out existing guardrails), spending time on fine-tuning a model can be unnecessary without a prior assessment of what it already knows, setting the temperature to 0 is not sufficient to make LLMs deterministic, providing a large volume of M&S data as input can be excessive (LLMs cannot attend to everything) but naive simplifications can lose information. We aim to provide comprehensive and practical guidance on how to use LLMs, with an emphasis on M&S applications. We discuss common sources of confusion, including non-determinism, knowledge augmentation (including RAG and LoRA), decomposition of M&S data, and hyper-parameter settings. We emphasize principled design choices, diagnostic strategies, and empirical evaluation, with the goal of helping modelers make informed decisions about when, how, and whether to rely on LLMs.