Agent2Agent Threats in Safety-Critical LLM Assistants: A Human-Centric Taxonomy
作者: Lukas Stappen, Ahmet Erkan Turan, Johann Hagerer, Georg Groh
分类: cs.AI, cs.HC
发布日期: 2026-02-05
💡 一句话要点
提出AgentHeLLM框架,应对LLM智能座舱Agent2Agent通信中的安全威胁
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM安全 智能座舱 Agent2Agent通信 威胁建模 攻击路径分析
📋 核心要点
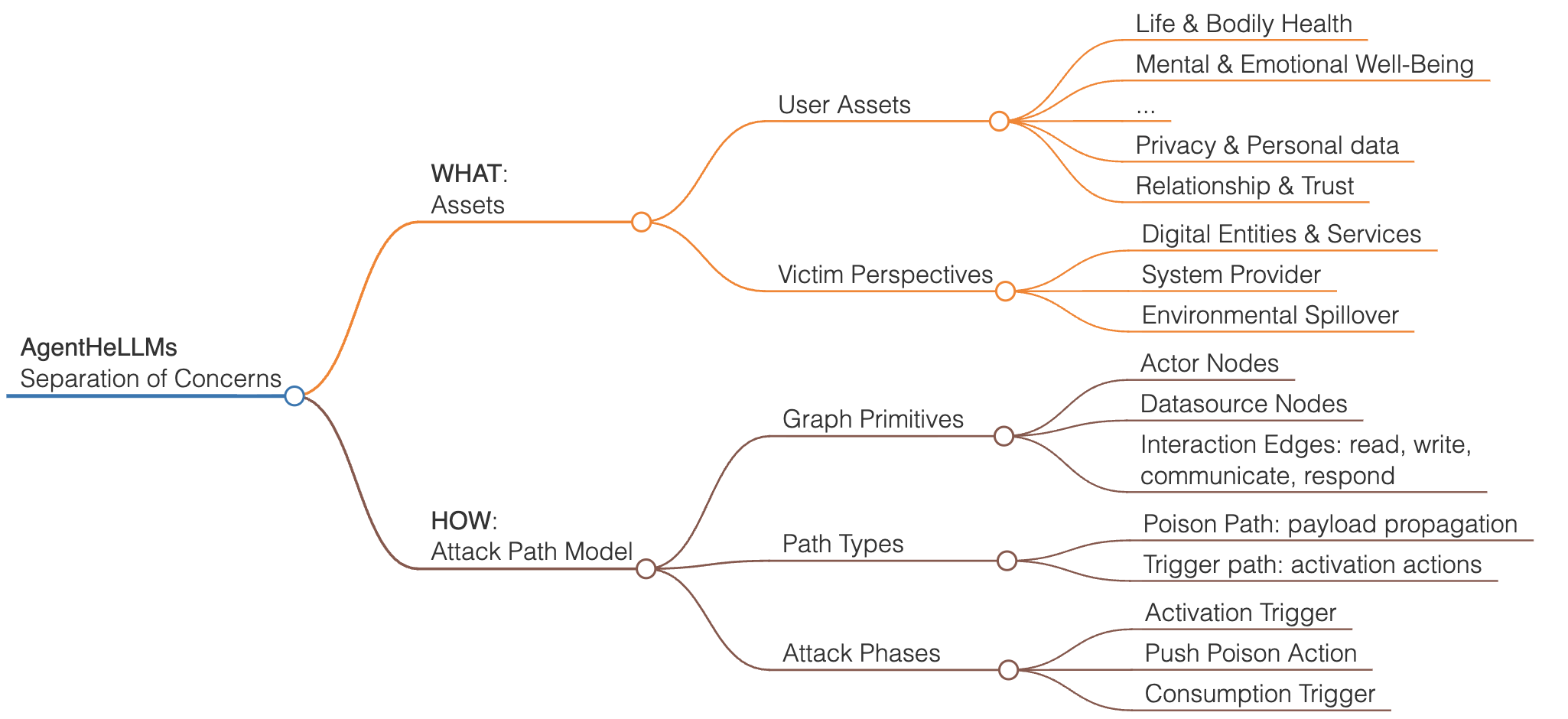
- 现有AI安全框架在安全关键系统中缺乏严格的“关注点分离”,混淆了资产和攻击路径,难以有效应对LLM智能座舱中的新型安全威胁。
- AgentHeLLM框架通过正式分离资产识别和攻击路径分析,并引入以人为中心的资产分类法,系统性地建模和分析潜在的安全风险。
- AgentHeLLM Attack Path Generator工具利用双层搜索策略自动发现多阶段攻击路径,验证了框架的实用性,为防御LLM智能座舱安全威胁提供了新思路。
📝 摘要(中文)
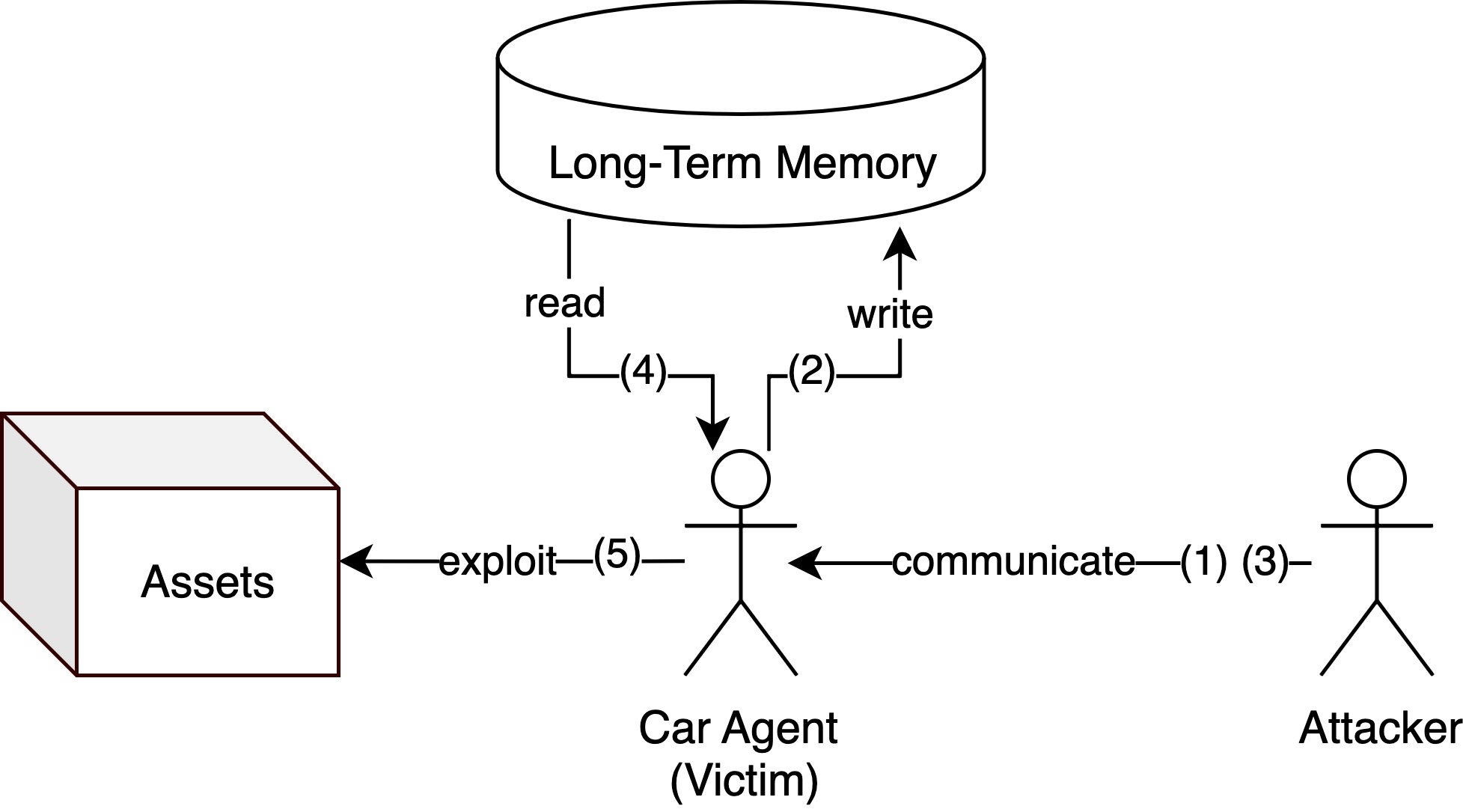
本文关注将基于大型语言模型(LLM)的对话Agent集成到车辆中带来的新型安全挑战,尤其是在Agent通过Google的Agent-to-Agent (A2A)等协议与外部服务协调时,自然语言有效载荷可能被恶意利用,导致驾驶员分心甚至未经授权的车辆控制。现有AI安全框架缺乏安全关键系统工程中严格的“关注点分离”标准,混淆了受保护的资产和攻击方式。为此,本文提出了名为AgentHeLLM(Agent Hazard Exploration for LLM Assistants)的威胁建模框架,将资产识别与攻击路径分析正式分离。该框架引入了以人为中心的资产分类法,源于面向危害的“受害者建模”并受到《世界人权宣言》的启发,以及区分毒害路径(恶意数据传播)和触发路径(激活动作)的正式图模型。通过开源攻击路径建议工具AgentHeLLM Attack Path Generator,展示了该框架的实际应用性,该工具使用双层搜索策略自动执行多阶段威胁发现。
🔬 方法详解
问题定义:论文旨在解决基于LLM的智能座舱Agent在Agent2Agent通信中面临的安全威胁问题。现有AI安全框架的痛点在于缺乏安全关键系统工程中严格的“关注点分离”,即将需要保护的资产与攻击路径混淆在一起,导致无法系统性地识别和应对潜在的风险。特别是在智能座舱Agent与外部服务交互时,自然语言有效载荷可能被恶意利用,造成严重的安全后果。
核心思路:论文的核心思路是将资产识别与攻击路径分析进行明确分离,从而更清晰地理解和应对安全威胁。通过借鉴安全关键系统工程的原则,论文提出了AgentHeLLM框架,该框架首先明确定义了需要保护的资产(例如驾驶员的安全、车辆的控制权等),然后独立地分析可能导致这些资产受损的攻击路径。这种分离使得威胁建模过程更加系统化和可控。
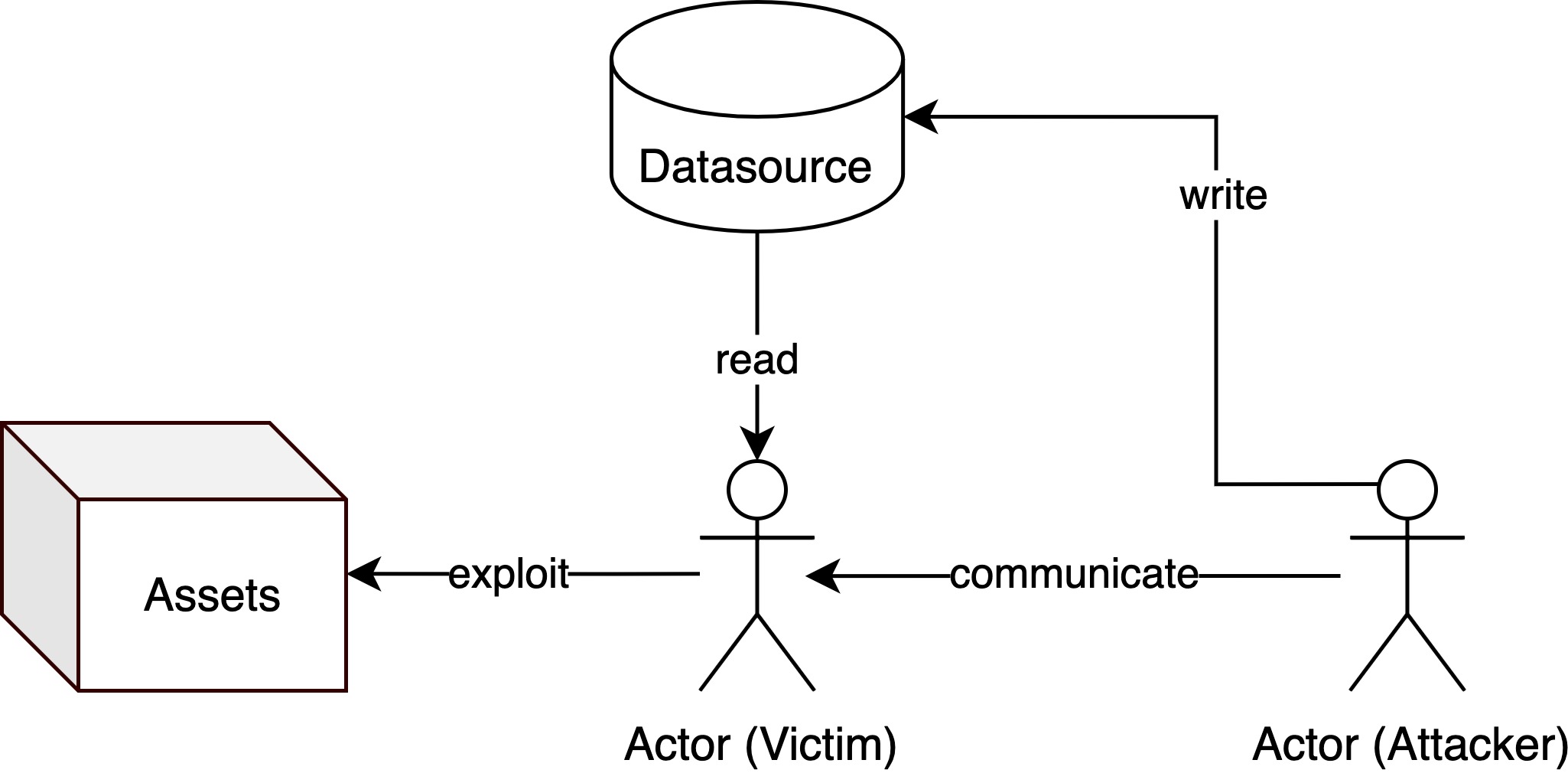
技术框架:AgentHeLLM框架包含以下主要模块:1) 人为中心的资产分类法:基于“受害者建模”和《世界人权宣言》定义了需要保护的资产。2) 基于图的威胁模型:区分了毒害路径(恶意数据传播)和触发路径(激活动作),用于建模攻击路径。3) AgentHeLLM Attack Path Generator:一个开源工具,使用双层搜索策略自动发现多阶段攻击路径。该工具能够根据定义的资产和攻击模型,自动生成潜在的攻击路径,帮助安全研究人员和开发人员识别和缓解安全风险。
关键创新:论文最重要的技术创新点在于提出了AgentHeLLM框架,该框架通过明确分离资产识别和攻击路径分析,解决了现有AI安全框架的不足。与现有方法相比,AgentHeLLM框架更加系统化和可控,能够更有效地识别和应对基于LLM的智能座舱Agent面临的安全威胁。此外,以人为中心的资产分类法也使得威胁建模过程更加关注用户的安全和权益。
关键设计:AgentHeLLM Attack Path Generator工具使用了双层搜索策略,第一层搜索用于发现潜在的攻击触发点,第二层搜索用于构建完整的攻击路径。具体的参数设置和搜索算法细节在论文中未详细描述,属于未知信息。框架中资产的定义和分类是关键,直接影响威胁建模的范围和准确性。
🖼️ 关键图片
📊 实验亮点
论文提出了AgentHeLLM Attack Path Generator工具,能够自动发现多阶段攻击路径,验证了框架的实用性。虽然论文中没有给出具体的性能数据和对比基线,但该工具的开源为安全研究人员和开发人员提供了一个有力的工具,可以用于识别和缓解基于LLM的智能座舱Agent面临的安全风险。工具的具体性能提升幅度未知。
🎯 应用场景
该研究成果可应用于智能座舱系统的安全设计、威胁建模和漏洞挖掘。通过AgentHeLLM框架,开发者可以系统地识别和评估潜在的安全风险,并采取相应的防御措施,从而提高智能座舱系统的安全性和可靠性。此外,该框架还可以用于评估现有智能座舱系统的安全性,并指导安全加固工作。未来,该研究可以扩展到其他基于LLM的智能Agent系统,例如智能家居、智能医疗等。
📄 摘要(原文)
The integration of Large Language Model (LLM)-based conversational agents into vehicles creates novel security challenges at the intersection of agentic AI, automotive safety, and inter-agent communication. As these intelligent assistants coordinate with external services via protocols such as Google's Agent-to-Agent (A2A), they establish attack surfaces where manipulations can propagate through natural language payloads, potentially causing severe consequences ranging from driver distraction to unauthorized vehicle control. Existing AI security frameworks, while foundational, lack the rigorous "separation of concerns" standard in safety-critical systems engineering by co-mingling the concepts of what is being protected (assets) with how it is attacked (attack paths). This paper addresses this methodological gap by proposing a threat modeling framework called AgentHeLLM (Agent Hazard Exploration for LLM Assistants) that formally separates asset identification from attack path analysis. We introduce a human-centric asset taxonomy derived from harm-oriented "victim modeling" and inspired by the Universal Declaration of Human Rights, and a formal graph-based model that distinguishes poison paths (malicious data propagation) from trigger paths (activation actions). We demonstrate the framework's practical applicability through an open-source attack path suggestion tool AgentHeLLM Attack Path Generator that automates multi-stage threat discovery using a bi-level search strategy.