TKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning
作者: Zihao Jiang, Miao Peng, Zhenyan Shan, Wenjie Xu, Ben Liu, Gong Chen, Ziqi Gao, Min Peng
分类: cs.AI, cs.DB
发布日期: 2026-02-05
💡 一句话要点
提出TKG-Thinker,通过Agent强化学习实现时序知识图谱的动态推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序知识图谱 知识图谱问答 强化学习 大语言模型 动态推理
📋 核心要点
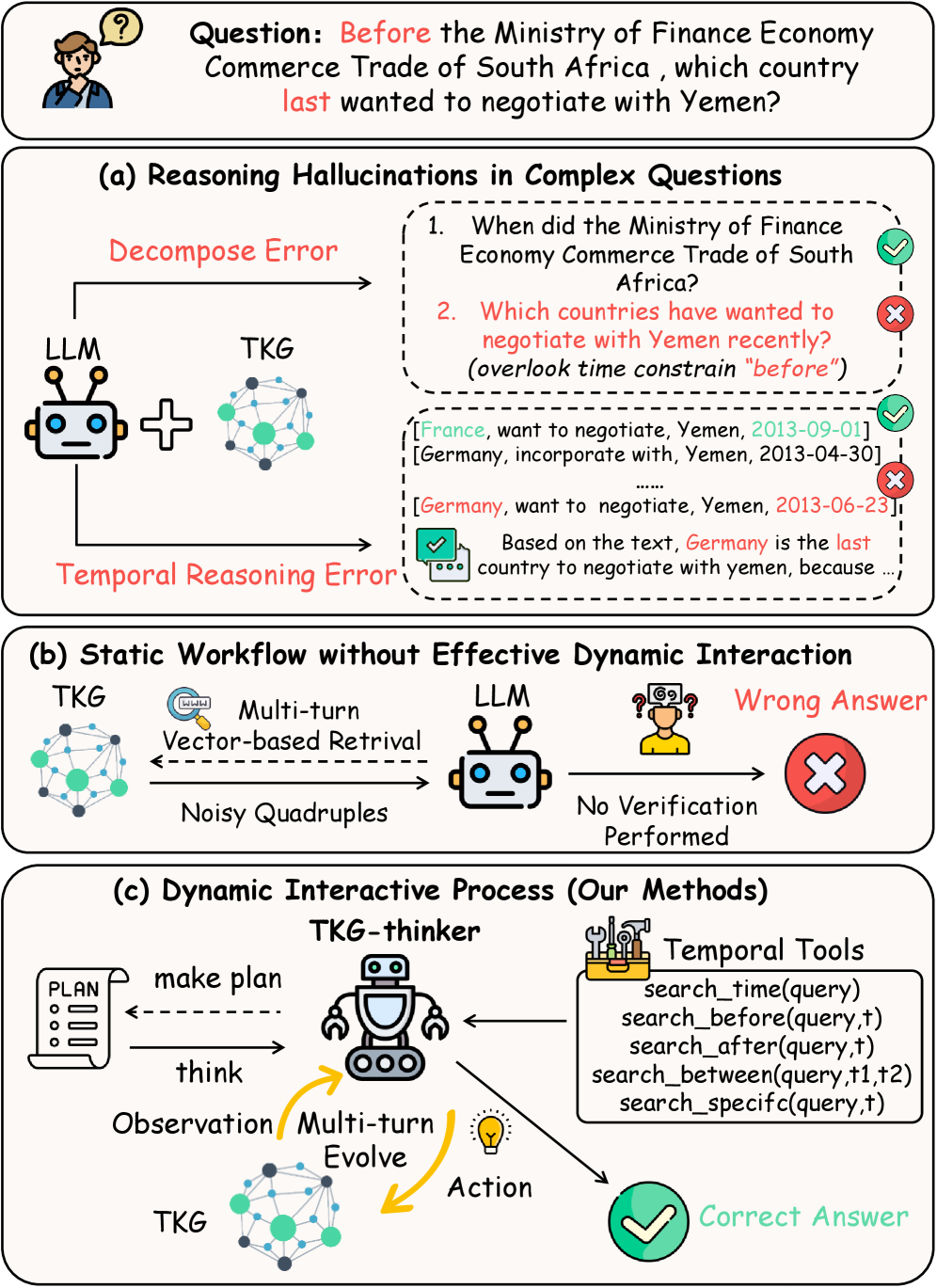
- 现有TKGQA方法依赖静态prompting,限制了LLM的自主性和泛化能力,且易在复杂时序约束下产生推理幻觉。
- TKG-Thinker通过Agent强化学习,实现与TKG的动态交互,自主规划推理路径,并自适应检索相关信息。
- 实验表明,TKG-Thinker在多个基准数据集上取得了SOTA性能,并在复杂场景下展现出良好的泛化能力。
📝 摘要(中文)
本文提出TKG-Thinker,一个用于时序知识图谱问答(TKGQA)的新型Agent,旨在解决现有大语言模型(LLM)在TKGQA中面临的推理幻觉和静态prompting导致的自主性和泛化性不足问题。TKG-Thinker通过自主规划和自适应检索能力,实现对TKG的动态多轮交互,从而进行深入的时序推理。该方法采用双重训练策略:首先使用思维链数据进行监督微调(SFT),赋予Agent核心规划能力;然后利用强化学习(RL),通过多维度奖励优化复杂时序约束下的推理策略。在基准数据集上的实验结果表明,TKG-Thinker在三个开源LLM上均取得了最先进的性能,并在复杂的TKGQA设置中表现出强大的泛化能力。
🔬 方法详解
问题定义:论文旨在解决时序知识图谱问答(TKGQA)中,现有方法依赖静态prompting导致LLM自主性和泛化性不足,以及在复杂时序约束下易产生推理幻觉的问题。现有方法无法充分利用TKG的动态信息,缺乏与环境的有效交互。
核心思路:论文的核心思路是构建一个Agent,使其能够通过与TKG环境的动态交互,自主规划推理路径,并自适应地检索相关信息。通过强化学习优化Agent的推理策略,使其能够更好地处理复杂的时序约束。
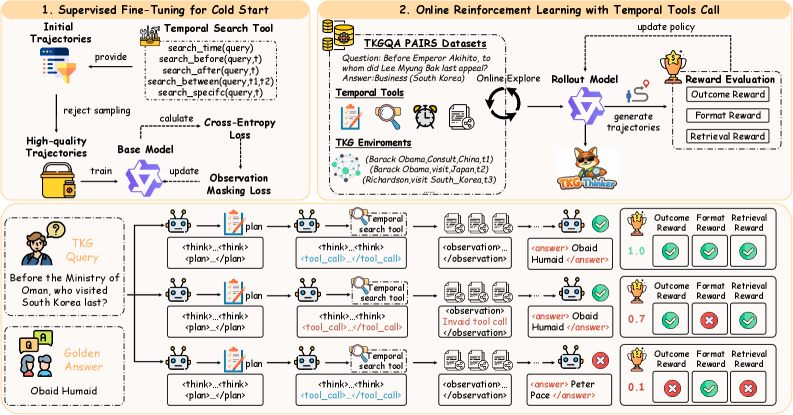
技术框架:TKG-Thinker的整体框架包含以下几个主要模块:1) Agent:负责与TKG环境交互,规划推理路径,并执行检索操作。2) TKG环境:提供时序知识图谱的信息,并根据Agent的动作给出反馈。3) 奖励函数:用于评估Agent的推理效果,并指导其学习。4) 双重训练策略:包括监督微调(SFT)和强化学习(RL)两个阶段。
关键创新:最重要的技术创新点在于将强化学习引入TKGQA,通过Agent与TKG环境的动态交互,实现了自主推理和自适应检索。与现有静态prompting方法相比,TKG-Thinker能够更好地利用TKG的动态信息,并有效缓解推理幻觉问题。
关键设计:在SFT阶段,使用思维链数据训练Agent的规划能力。在RL阶段,设计了多维度奖励函数,包括正确性奖励、效率奖励和时序一致性奖励,以优化Agent的推理策略。具体参数设置和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
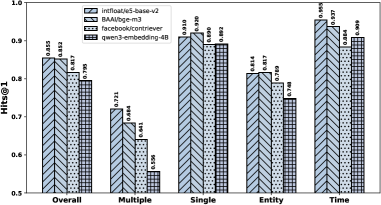
TKG-Thinker在基准数据集上取得了state-of-the-art的性能。具体而言,在三个开源LLM上进行了实验,结果表明TKG-Thinker显著优于现有的prompting方法。论文中给出了具体的性能数据,但由于摘要中未提供详细数值,具体提升幅度未知。
🎯 应用场景
TKG-Thinker的研究成果可应用于智能问答系统、知识图谱补全、事件预测等领域。通过动态推理和自适应检索,该方法能够更准确地回答时序相关的问题,提升知识图谱的应用价值。未来,该方法有望应用于金融风控、医疗诊断等需要时序推理的复杂场景。
📄 摘要(原文)
Temporal knowledge graph question answering (TKGQA) aims to answer time-sensitive questions by leveraging temporal knowledge bases. While Large Language Models (LLMs) demonstrate significant potential in TKGQA, current prompting strategies constrain their efficacy in two primary ways. First, they are prone to reasoning hallucinations under complex temporal constraints. Second, static prompting limits model autonomy and generalization, as it lack optimization through dynamic interaction with temporal knowledge graphs (TKGs) environments. To address these limitations, we propose \textbf{TKG-Thinker}, a novel agent equipped with autonomous planning and adaptive retrieval capabilities for reasoning over TKGs. Specifically, TKG-Thinker performs in-depth temporal reasoning through dynamic multi-turn interactions with TKGs via a dual-training strategy. We first apply Supervised Fine-Tuning (SFT) with chain-of thought data to instill core planning capabilities, followed by a Reinforcement Learning (RL) stage that leverages multi-dimensional rewards to refine reasoning policies under intricate temporal constraints. Experimental results on benchmark datasets with three open-source LLMs show that TKG-Thinker achieves state-of-the-art performance and exhibits strong generalization across complex TKGQA settings.