NEX: Neuron Explore-Exploit Scoring for Label-Free Chain-of-Thought Selection and Model Ranking
作者: Kang Chen, Zhuoka Feng, Sihan Zhao, Kai Xiong, Junjie Nian, Yaoning Wang, Changyi Xiao, Yixin Cao
分类: cs.AI
发布日期: 2026-02-05
备注: 21 pages, 9 figures, 5 tables
💡 一句话要点
NEX:基于神经元探索-利用评分的无标签CoT选择与模型排序
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 无监督学习 神经元激活 模型选择 模型排序
📋 核心要点
- 现有CoT选择方法缺乏对目标分布的监督,导致探索过度和过度思考。
- NEX框架将推理过程分解为探索(E)和利用(X)阶段,通过神经元激活模式进行无监督评分。
- 实验表明,NEX能够有效预测模型准确率并识别更优模型变体,无需任务标签。
📝 摘要(中文)
大型语言模型越来越多地花费推理计算资源来采样多个思维链(Chain-of-Thought, CoT)轨迹或搜索合并后的检查点。这使得瓶颈从生成转移到选择,而通常缺乏对目标分布的监督。我们发现,基于熵的探索代理与准确率呈现倒U型关系,表明额外的探索可能会变得冗余并导致过度思考。我们提出了NEX,一个白盒无标签的无监督评分框架,它将推理视为交替的E阶段(探索)和X阶段(利用)。NEX通过稀疏激活缓存检测E阶段,表现为每个token新激活的MLP神经元的峰值,然后使用粘性两状态隐马尔可夫模型(HMM)来推断E-X阶段,并通过E阶段引入的神经元是否在后续X阶段被重用来评估其价值。这些信号产生了可解释的神经元权重和一个单一的Good-Mass Fraction分数,用于在没有任务答案的情况下对候选响应和合并变体进行排序。在推理基准和Qwen3合并系列中,基于小型未标记激活集计算的NEX能够预测下游准确率并识别更好的变体;我们进一步通过人工标注验证了E-X信号,并通过“有效与冗余”神经元转移提供了因果证据。
🔬 方法详解
问题定义:现有的大型语言模型推理过程中,为了提高性能,通常会生成多个CoT轨迹或搜索合并后的检查点。然而,如何有效地从这些候选结果中选择最佳答案成为了新的瓶颈。现有的选择方法往往缺乏对目标分布的监督,容易出现探索过度,导致模型“过度思考”,反而降低了准确率。因此,如何在没有标签的情况下,有效地评估和选择最佳的CoT结果或模型变体,是一个亟待解决的问题。
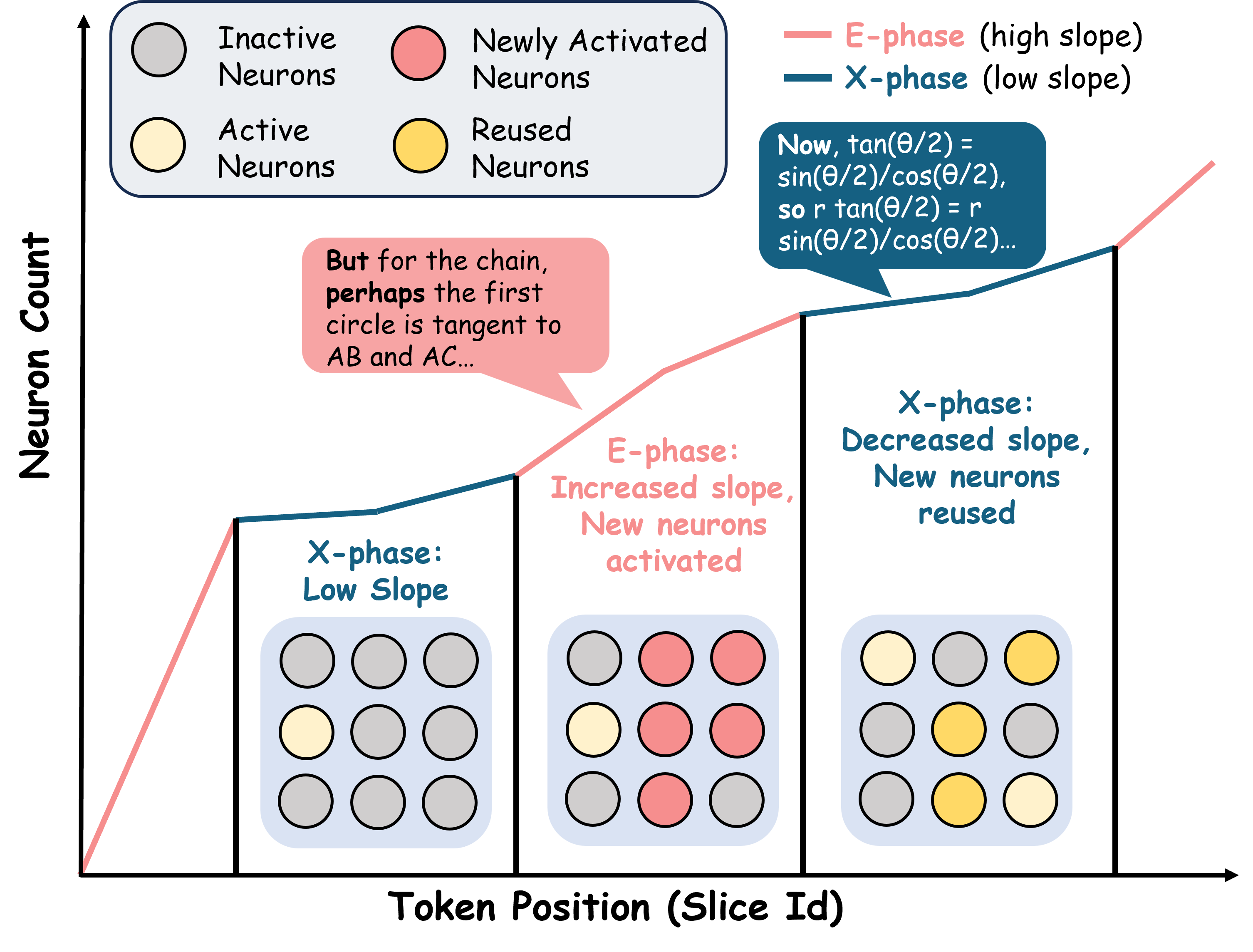
核心思路:NEX的核心思路是将大型语言模型的推理过程视为一个交替进行的探索(E)和利用(X)过程。探索阶段对应于模型尝试新的推理路径,激活新的神经元;利用阶段对应于模型巩固已有的推理路径,重复使用已激活的神经元。通过分析神经元的激活模式,可以推断出E-X阶段,并评估每个神经元对最终结果的贡献。
技术框架:NEX框架主要包含以下几个模块:1) 神经元激活缓存:记录模型推理过程中每个token激活的神经元。2) E-X阶段推断:通过检测每个token新激活的MLP神经元的峰值来识别E阶段,然后使用粘性两状态隐马尔可夫模型(HMM)来推断E-X阶段。3) 神经元评分:根据神经元在E阶段被引入,并在后续X阶段被重用的情况,对神经元进行评分。4) Good-Mass Fraction (GMF) 计算:基于神经元权重计算一个单一的GMF分数,用于对候选响应和模型变体进行排序。
关键创新:NEX的关键创新在于提出了一个无标签的、基于神经元激活模式的E-X阶段推断方法。与传统的基于熵的探索代理不同,NEX能够更准确地捕捉模型推理过程中的探索和利用行为,并根据神经元的贡献进行评分。这种方法不需要任何标签数据,就可以有效地评估和选择最佳的CoT结果或模型变体。
关键设计:NEX的关键设计包括:1) 使用稀疏激活缓存来减少计算量。2) 使用粘性HMM来平滑E-X阶段的推断结果。3) 根据神经元在E阶段的引入和在X阶段的重用情况来评估神经元的贡献。4) 使用Good-Mass Fraction (GMF) 作为最终的评分指标,GMF越高,表示模型性能越好。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在推理基准和Qwen3合并系列中,基于小型未标记激活集计算的NEX能够有效预测下游准确率并识别更好的变体。通过人工标注验证了E-X信号的有效性,并通过“有效与冗余”神经元转移提供了因果证据。这些结果表明,NEX是一种有效的无标签CoT选择和模型排序方法。
🎯 应用场景
NEX可应用于各种需要从多个候选答案中选择最佳答案的场景,例如思维链推理、模型合并等。它能够帮助研究人员和开发者在没有标签数据的情况下,快速评估和选择最佳的模型变体,从而加速模型开发和优化过程。此外,NEX还可以用于分析模型的推理过程,帮助人们更好地理解大型语言模型的工作原理。
📄 摘要(原文)
Large language models increasingly spend inference compute sampling multiple chain-of-thought traces or searching over merged checkpoints. This shifts the bottleneck from generation to selection, often without supervision on the target distribution. We show entropy-based exploration proxies follow an inverted-U with accuracy, suggesting extra exploration can become redundant and induce overthinking. We propose NEX, a white-box label-free unsupervised scoring framework that views reasoning as alternating E-phase (exploration) and X-phase (exploitation). NEX detects E-phase as spikes in newly activated MLP neurons per token from sparse activation caches, then uses a sticky two-state HMM to infer E-X phases and credits E-introduced neurons by whether they are reused in the following X span. These signals yield interpretable neuron weights and a single Good-Mass Fraction score to rank candidate responses and merged variants without task answers. Across reasoning benchmarks and Qwen3 merge families, NEX computed on a small unlabeled activation set predicts downstream accuracy and identifies better variants; we further validate the E-X signal with human annotations and provide causal evidence via "Effective-vs-Redundant" neuron transfer.