RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
作者: Zhong Guan, Haoran Sun, Yongjian Guo, Shuai Di, Xiaodong Bai, Jing Long, Tianyun Zhao, Mingxi Luo, Chen Zhou, Yucheng Guo, Qiming Yang, Wanting Xu, Wen Huang, Yunxuan Ma, Hongke Zhao, Likang Wu, Xiaotie Deng, Xi Xiao, Sheng Wen, Yicheng Gong, Junwu Xiong
分类: cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出RL-VLA$^3$,通过全异步加速VLA模型的强化学习训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 强化学习 异步训练 具身智能 模型加速
📋 核心要点
- VLA模型训练效率低是瓶颈,现有RL框架同步执行导致资源利用率低和吞吐量受限。
- RL-VLA$^3$框架采用全异步策略训练,包含环境交互、rollout生成和策略更新全流程。
- 实验表明,该框架在LIBERO基准测试中吞吐量提升高达59.25%,优化后可达126.67%。
📝 摘要(中文)
近年来,视觉-语言-动作(VLA)模型已成为通向通用具身智能的关键途径,但其训练效率已成为关键瓶颈。虽然现有的基于强化学习(RL)的训练框架(如RLinf)可以增强模型的泛化能力,但它们仍然依赖于同步执行,导致环境交互、策略生成(rollout)和模型更新阶段(actor)期间严重的资源利用不足和吞吐量限制。为了克服这一挑战,本文首次提出并实现了一个全异步策略训练框架,该框架涵盖了从环境交互、rollout生成到actor策略更新的整个流程。系统地借鉴了大型模型RL中的异步优化思想,我们的框架设计了一个多级解耦架构。这包括环境交互和轨迹收集的异步并行化、策略生成的流式执行以及训练更新的解耦调度。我们在不同的VLA模型和环境中验证了我们方法的有效性。在LIBERO基准测试中,与现有的同步策略相比,该框架实现了高达59.25%的吞吐量提升。当深入优化分离策略时,吞吐量可以提高高达126.67%。我们通过消融研究验证了每个异步组件的有效性。在8到256个GPU上的缩放规律验证表明,我们的方法在大多数条件下具有出色的可扩展性。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型训练效率低下的问题。现有的基于强化学习的训练框架,如RLinf,虽然可以提高模型泛化能力,但其同步执行模式导致环境交互、策略生成和模型更新阶段的资源利用率不足和吞吐量受限。这限制了VLA模型在复杂环境中的应用和发展。
核心思路:论文的核心思路是引入全异步的策略训练框架,打破传统同步执行的限制。通过异步并行化环境交互和轨迹收集、流式执行策略生成以及解耦调度训练更新,充分利用计算资源,提高训练吞吐量。这种设计借鉴了大型模型强化学习中的异步优化思想,旨在实现更高效的VLA模型训练。
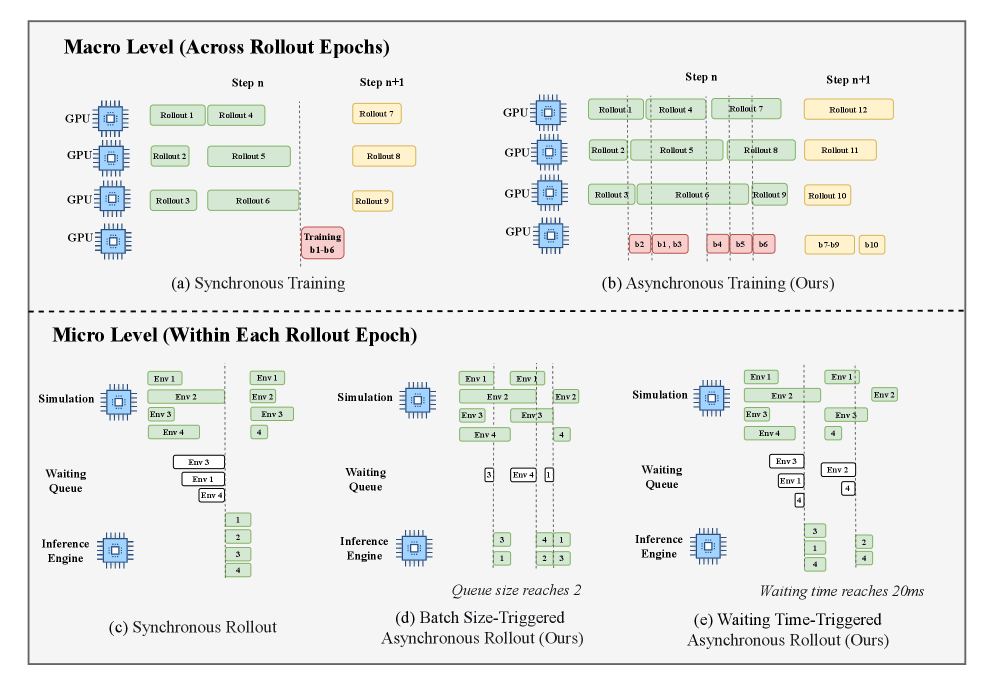
技术框架:RL-VLA$^3$框架采用多级解耦架构,包含以下主要模块:1) 异步环境交互模块,负责并行执行多个环境实例,收集轨迹数据;2) 流式策略生成模块,负责根据环境交互产生的数据,异步生成策略;3) 解耦训练更新模块,负责异步地更新actor策略。这些模块之间通过消息队列进行通信,实现完全解耦和异步执行。
关键创新:该论文最重要的技术创新在于首次提出了全异步的VLA模型训练框架。与现有同步框架相比,RL-VLA$^3$实现了环境交互、策略生成和模型更新的完全异步化,从而显著提高了资源利用率和训练吞吐量。这种全异步的设计是与现有方法的本质区别。
关键设计:论文的关键设计包括:1) 异步并行化环境交互,通过增加环境实例数量来提高数据收集速度;2) 流式策略生成,避免因策略生成阻塞环境交互;3) 解耦训练更新,允许actor策略在不同时间点使用不同的数据进行更新;4) 针对异步训练的调度策略,平衡不同模块的资源需求,避免资源争用。
🖼️ 关键图片
📊 实验亮点
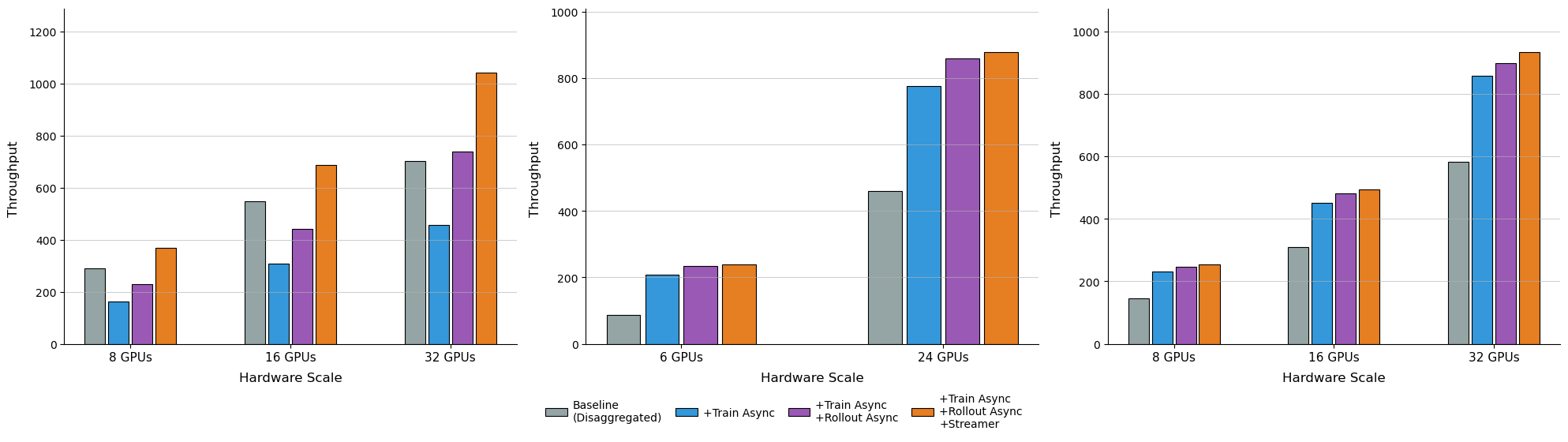
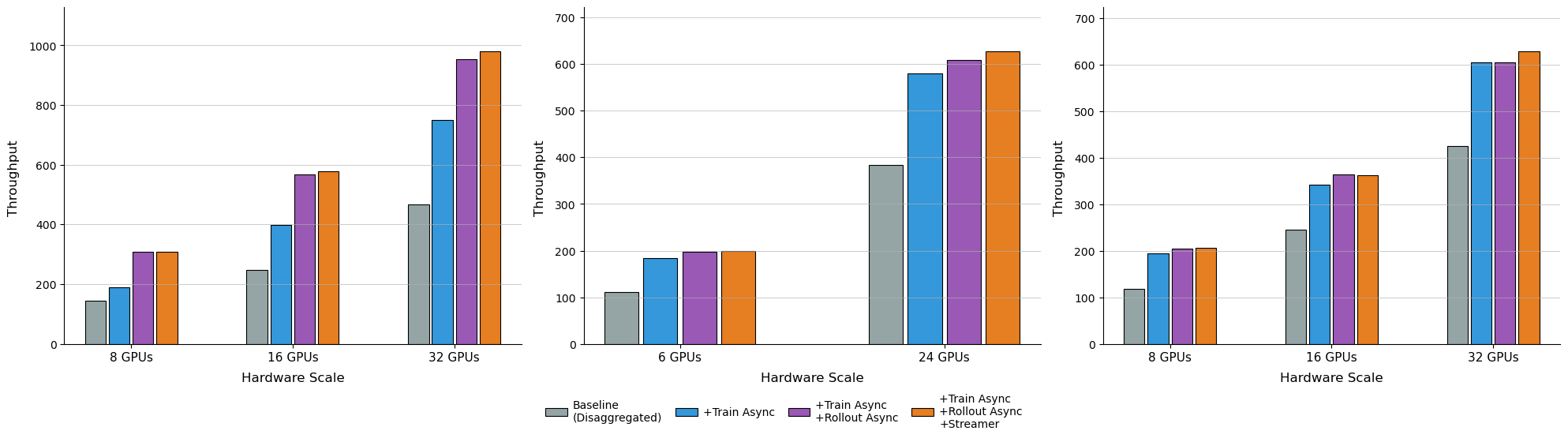
实验结果表明,RL-VLA$^3$框架在LIBERO基准测试中,相比现有同步策略,吞吐量提升高达59.25%。通过深入优化分离策略,吞吐量可以提升高达126.67%。消融实验验证了每个异步组件的有效性。在8到256个GPU上的扩展性实验表明,该方法在大多数情况下具有良好的可扩展性。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域。通过提高VLA模型的训练效率,可以加速这些模型在复杂环境中的部署和应用,实现更智能、更高效的具身智能系统。未来,该方法有望推动通用人工智能的发展。
📄 摘要(原文)
In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.