Towards Green AI: Decoding the Energy of LLM Inference in Software Development
作者: Lola Solovyeva, Fernando Castor
分类: cs.SE, cs.AI
发布日期: 2026-02-05
💡 一句话要点
分析LLM推理能耗,提出抑制“胡言乱语”行为以降低软件开发能耗
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 能耗分析 软件开发 绿色AI 推理优化 代码生成 预填充 解码
📋 核心要点
- 大型语言模型在软件开发中的应用日益广泛,但其高能耗问题对可持续发展构成挑战。
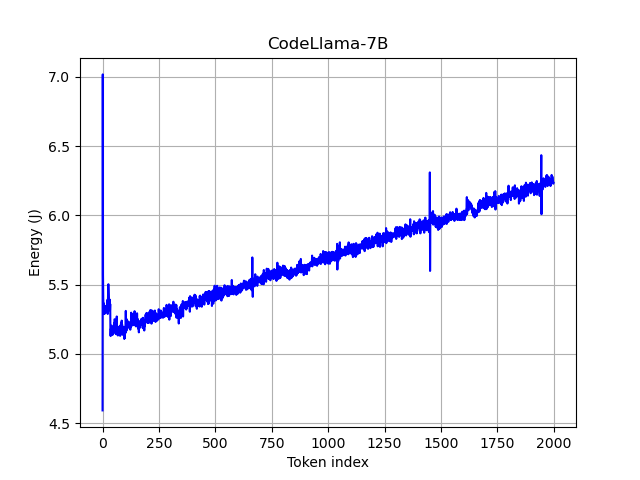
- 论文通过阶段性分析LLM推理能耗,着重研究预填充和解码阶段的能耗模式。
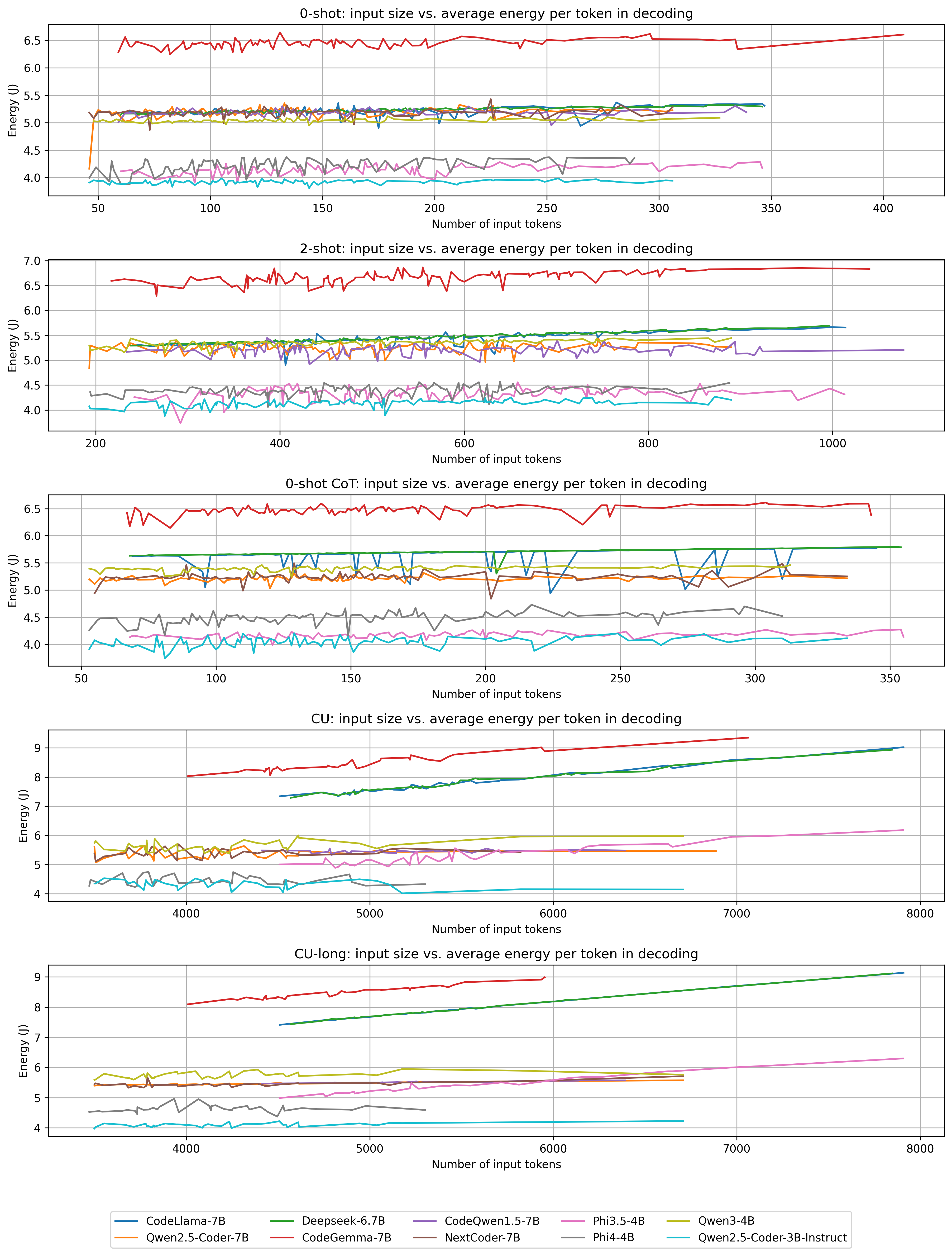
- 实验发现预填充成本影响解码能耗,并提出抑制“胡言乱语”行为可显著降低能耗。
📝 摘要(中文)
人工智能辅助工具日益融入软件开发流程,但它们对大型语言模型(LLM)的依赖带来了巨大的计算和能源成本。理解和降低LLM推理的能源消耗对于可持续软件开发至关重要。本研究对LLM推理的能耗进行了阶段级分析,区分了(1)预填充阶段(模型处理输入并构建内部表示)和(2)解码阶段(使用存储状态生成输出token)。我们研究了六个6B-7B和四个3B-4B的基于Transformer的模型,并在以代码为中心的基准测试HumanEval(用于代码生成)和LongBench(用于代码理解)上评估它们。结果表明,在两个参数组中,模型在不同阶段表现出不同的能量模式。此外,我们观察到预填充成本的增加会放大解码期间每个token的能量成本,放大倍数从1.3%到51.8%不等,具体取决于模型。最后,十个模型中有三个表现出“胡言乱语”行为,即在输出中添加过多的内容,不必要地增加了能源消耗。我们实现了代码生成的“胡言乱语”抑制,实现了44%到89%的节能,而没有影响生成精度。结论表明,预填充成本会影响解码,而解码主导着能源消耗,“胡言乱语”抑制可以节省高达89%的能源。因此,降低推理能耗需要同时减轻“胡言乱语”行为和限制预填充对解码的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在软件开发应用中推理能耗过高的问题。现有方法缺乏对LLM推理过程细粒度的能耗分析,无法有效定位和解决能耗瓶颈。此外,模型可能产生冗余的“胡言乱语”内容,进一步加剧能耗。
核心思路:论文的核心思路是对LLM推理过程进行阶段性分析,区分预填充和解码阶段,并研究各阶段的能耗特征。通过识别导致高能耗的关键因素,例如预填充成本对解码的影响以及“胡言乱语”行为,提出相应的优化策略,例如抑制“胡言乱语”行为。
技术框架:论文的技术框架主要包括以下几个部分: 1. 选择多个不同规模(6B-7B和3B-4B)的基于Transformer的LLM。 2. 在代码生成(HumanEval)和代码理解(LongBench)等代码相关的基准测试上评估这些模型。 3. 对LLM推理过程进行阶段性划分,区分预填充和解码阶段,并测量各阶段的能耗。 4. 分析预填充成本对解码阶段能耗的影响。 5. 识别并量化模型中的“胡言乱语”行为。 6. 实现“胡言乱语”抑制策略,并评估其对能耗的影响。
关键创新:论文的关键创新在于: 1. 对LLM推理过程进行阶段性、细粒度的能耗分析,揭示了预填充成本对解码阶段能耗的影响。 2. 识别并量化了LLM中的“胡言乱语”行为,并提出了相应的抑制策略。 3. 实验证明,通过抑制“胡言乱语”行为,可以在不影响生成精度的前提下显著降低能耗。
关键设计:论文的关键设计包括: 1. 使用专业的能耗测量工具,精确测量LLM推理过程中各个阶段的能耗。 2. 设计合理的指标来量化“胡言乱语”行为,例如输出文本的长度和冗余程度。 3. 实现简单有效的“胡言乱语”抑制策略,例如设置输出长度上限或使用过滤规则。
🖼️ 关键图片
📊 实验亮点
实验结果表明,预填充成本的增加会放大解码期间每个token的能量成本,放大倍数从1.3%到51.8%不等。更重要的是,通过抑制“胡言乱语”行为,代码生成任务的能耗可降低44%到89%,而不会影响生成精度。这些结果突显了降低LLM推理能耗的巨大潜力。
🎯 应用场景
该研究成果可应用于各种AI辅助软件开发工具,例如代码自动补全、代码生成和代码理解等。通过降低LLM推理的能耗,可以提高这些工具的可持续性和经济性,并减少其对环境的影响。未来,该研究可以扩展到其他类型的LLM和应用场景,为实现绿色AI做出贡献。
📄 摘要(原文)
Context: AI-assisted tools are increasingly integrated into software development workflows, but their reliance on large language models (LLMs) introduces substantial computational and energy costs. Understanding and reducing the energy footprint of LLM inference is therefore essential for sustainable software development. Objective: In this study, we conduct a phase-level analysis of LLM inference energy consumption, distinguishing between the (1) prefill, where the model processes the input and builds internal representations, and (2) decoding, where output tokens are generated using the stored state. Method: We investigate six 6B-7B and four 3B-4B transformer-based models, evaluating them on code-centric benchmarks HumanEval for code generation and LongBench for code understanding. Results: Our findings show that, within both parameter groups, models exhibit distinct energy patterns across phases. Furthermore, we observed that increases in prefill cost amplify the energy cost per token during decoding, with amplifications ranging from 1.3% to 51.8% depending on the model. Lastly, three out of ten models demonstrate babbling behavior, adding excessive content to the output that unnecessarily inflates energy consumption. We implemented babbling suppression for code generation, achieving energy savings ranging from 44% to 89% without affecting generation accuracy. Conclusion: These findings show that prefill costs influence decoding, which dominates energy consumption, and that babbling suppression can yield up to 89% energy savings. Reducing inference energy therefore requires both mitigating babbling behavior and limiting impact of prefill on decoding.