Determining Energy Efficiency Sweet Spots in Production LLM Inference
作者: Hiari Pizzini Cavagna, Andrea Proia, Giacomo Madella, Giovanni B. Esposito, Francesco Antici, Daniele Cesarini, Zeynep Kiziltan, Andrea Bartolini
分类: cs.AI, cs.PF
发布日期: 2026-02-05
备注: To appear at ICPE 2026 (International Conference on Performance Engineering)
💡 一句话要点
提出Transformer架构能耗分析模型,优化LLM推理能效
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM推理 能源效率 Transformer架构 能耗建模
📋 核心要点
- 现有LLM推理能耗评估方法依赖于输入输出长度的线性函数,未能捕捉非线性能效特性。
- 论文提出基于Transformer架构复杂度的分析模型,精确表征能效曲线与输入输出长度的关系。
- 实验表明,优化序列长度至能效“最佳点”可显著降低能耗,支持更高效的LLM部署策略。
📝 摘要(中文)
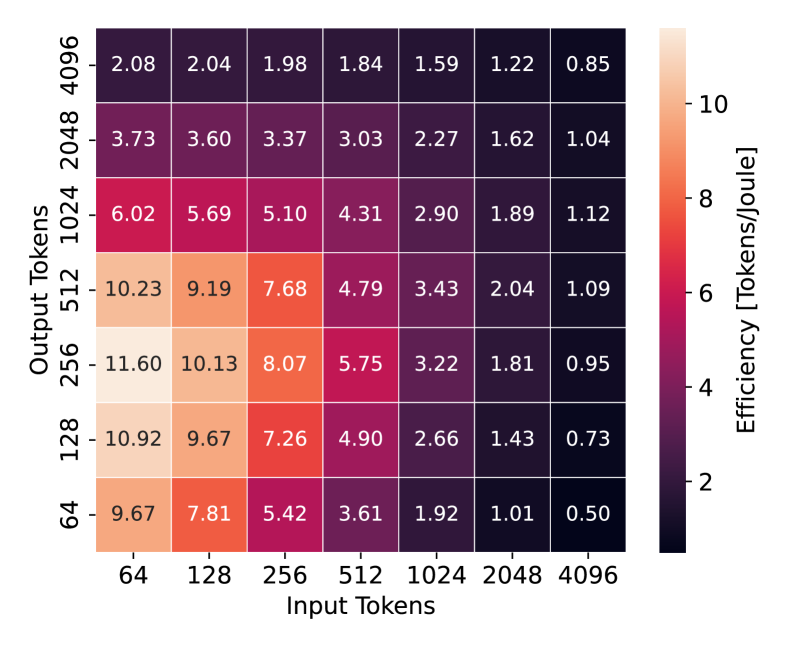
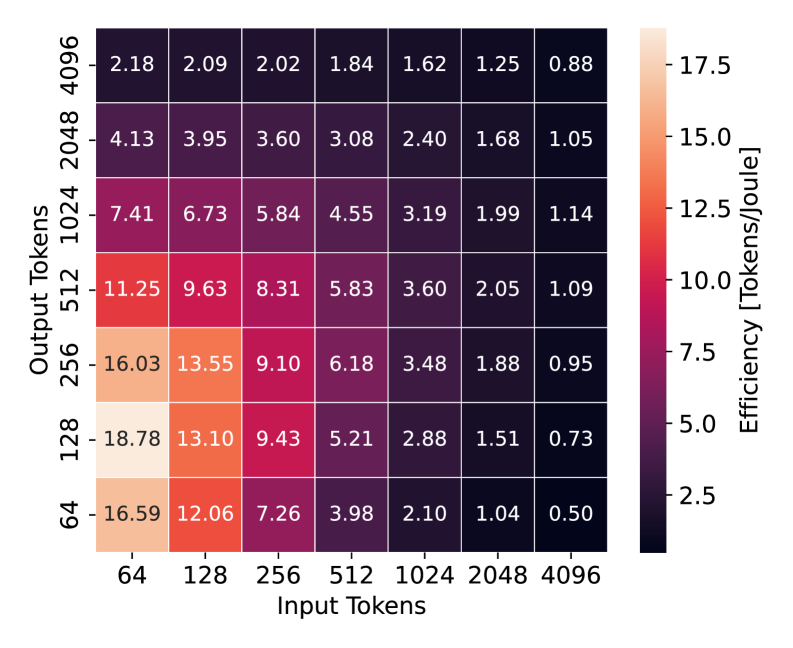
大型语言模型(LLM)推理是现代人工智能应用的核心,因此理解其能源消耗至关重要。现有方法通常通过输入和输出序列长度的简单线性函数来估计能耗,但我们的观察揭示了明显的能效状态:峰值效率出现在短到中等长度的输入和中等长度的输出时,而对于长输入或非常短的输出,效率会急剧下降,表明存在非线性依赖关系。在这项工作中,我们提出了一个分析模型,该模型源自Transformer架构的计算和内存访问复杂度,能够准确地表征效率曲线作为输入和输出长度的函数。为了评估其准确性,我们使用TensorRT-LLM在NVIDIA H100 GPU上评估了各种LLM(范围从1B到9B参数),包括OPT、LLaMA、Gemma、Falcon、Qwen2和Granite,并在64到4096个token的输入和输出长度上进行了测试,实现了1.79%的平均MAPE。我们的结果表明,将序列长度与这些效率“最佳点”对齐可以显著减少能源使用,从而支持生产系统中的知情截断、摘要和自适应生成策略。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)推理能耗评估方法,通常采用基于输入和输出序列长度的简单线性函数。这种方法忽略了LLM推理过程中复杂的计算和内存访问模式,无法准确反映实际的能耗情况,尤其是在不同输入输出长度组合下,能效存在显著差异。因此,如何精确建模LLM推理的能耗,并找到能效最佳的输入输出长度组合,是亟待解决的问题。
核心思路:论文的核心思路是基于Transformer架构的计算和内存访问复杂度,构建一个分析模型来表征LLM推理的能耗。Transformer架构是LLM的基础,其计算和内存访问模式直接影响能耗。通过分析Transformer架构中各个模块的计算量和内存访问量,可以建立能耗与输入输出长度之间的关系模型。该模型能够捕捉到能耗的非线性特性,从而更准确地预测LLM推理的能耗。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 分析Transformer架构的计算和内存访问复杂度;2) 基于分析结果,构建能耗分析模型,该模型以输入和输出长度为自变量,以能耗为因变量;3) 使用TensorRT-LLM在NVIDIA H100 GPU上对多个LLM进行能耗测量,包括OPT、LLaMA、Gemma、Falcon、Qwen2和Granite等;4) 使用测量数据验证能耗分析模型的准确性,并评估其在不同输入输出长度下的能效表现。
关键创新:该论文的关键创新在于提出了一个基于Transformer架构复杂度的能耗分析模型。与现有的线性模型相比,该模型能够更准确地表征LLM推理的能耗,并捕捉到能耗的非线性特性。此外,该研究还通过大量的实验验证了模型的准确性,并揭示了LLM推理的能效“最佳点”,为优化LLM部署提供了新的思路。
关键设计:该能耗分析模型基于Transformer架构的计算和内存访问复杂度。具体来说,模型考虑了以下几个关键因素:1) 注意力机制的计算复杂度,包括query、key和value的计算以及softmax操作;2) 前馈网络的计算复杂度,包括线性变换和激活函数;3) 内存访问量,包括模型参数的读取和中间结果的存储。模型通过对这些因素进行建模,建立了能耗与输入输出长度之间的关系。此外,该研究还使用了TensorRT-LLM来加速LLM推理,并使用NVIDIA H100 GPU进行能耗测量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的能耗分析模型能够准确地表征LLM推理的能耗,平均MAPE仅为1.79%。通过将序列长度与能效“最佳点”对齐,可以显著降低能源使用。例如,在某些情况下,通过调整输入输出长度,可以将能耗降低高达20%。该研究结果为优化LLM部署提供了有力的支持。
🎯 应用场景
该研究成果可应用于各种LLM推理场景,例如在线对话、文本摘要、机器翻译等。通过优化输入输出长度,使之与能效“最佳点”对齐,可以显著降低LLM推理的能耗,从而降低运营成本,并提高系统的可持续性。此外,该研究还可以为LLM的硬件加速器设计提供指导,促进更高效的LLM推理硬件的开发。
📄 摘要(原文)
Large Language Models (LLMs) inference is central in modern AI applications, making it critical to understand their energy footprint. Existing approaches typically estimate energy consumption through simple linear functions of input and output sequence lengths, yet our observations reveal clear Energy Efficiency regimes: peak efficiency occurs with short-to-moderate inputs and medium-length outputs, while efficiency drops sharply for long inputs or very short outputs, indicating a non-linear dependency. In this work, we propose an analytical model derived from the computational and memory-access complexity of the Transformer architecture, capable of accurately characterizing the efficiency curve as a function of input and output lengths. To assess its accuracy, we evaluate energy consumption using TensorRT-LLM on NVIDIA H100 GPUs across a diverse set of LLMs ranging from 1B to 9B parameters, including OPT, LLaMA, Gemma, Falcon, Qwen2, and Granite, tested over input and output lengths from 64 to 4096 tokens, achieving a mean MAPE of 1.79%. Our results show that aligning sequence lengths with these efficiency "Sweet Spots" can substantially reduce energy usage, supporting informed truncation, summarization, and adaptive generation strategies in production systems.