TangramSR: Can Vision-Language Models Reason in Continuous Geometric Space?
作者: Yikun Zong, Cheston Tan
分类: cs.AI
发布日期: 2026-02-05
备注: 13 pages, 4 figures
💡 一句话要点
TangramSR:提出基于视觉-语言模型的切磋拼图自精炼框架,提升连续几何空间推理能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 视觉-语言模型 几何推理 空间推理 上下文学习 自精炼 迭代优化 切磋拼图
📋 核心要点
- 现有视觉-语言模型在连续几何空间推理方面表现不足,尤其是在需要迭代细化的复杂任务中,例如切磋拼图。
- 论文提出一个测试时自精炼框架,通过结合上下文学习和奖励引导的反馈循环,模拟人类解决空间推理问题的认知过程。
- 实验表明,该框架无需模型重新训练,即可显著提升视觉-语言模型在切磋拼图任务中的几何推理能力,IoU提升显著。
📝 摘要(中文)
人类擅长空间推理任务,例如通过心理旋转、迭代细化和视觉反馈来完成切磋拼图。受人类解决切磋拼图的试错、观察和纠正方式的启发,本文设计了一个模拟这些人类认知机制的框架。然而,对五个代表性的视觉-语言模型(VLM)的全面实验表明,它们在连续几何推理方面存在系统性失败:单块任务的平均IoU仅为0.41,两块组合降至0.23,远低于儿童成功完成切磋拼图的人类表现。本文旨在解决自改进AI中的一个根本挑战:模型能否在测试时迭代地改进其预测而无需参数更新?我们引入了一个测试时自精炼框架,该框架结合了上下文学习(ICL)和奖励引导的反馈循环,灵感来自人类认知过程。我们的免训练验证器-精炼器代理应用递归精炼循环,根据几何一致性反馈迭代地自精炼预测,在中等三角形案例中实现了从0.63到0.932的IoU改进,而无需任何模型重新训练。这表明,通过ICL和奖励循环结合人类启发式迭代精炼机制可以显著增强VLM中的几何推理能力,从而将自改进AI从连续空间领域的承诺变为实践。
🔬 方法详解
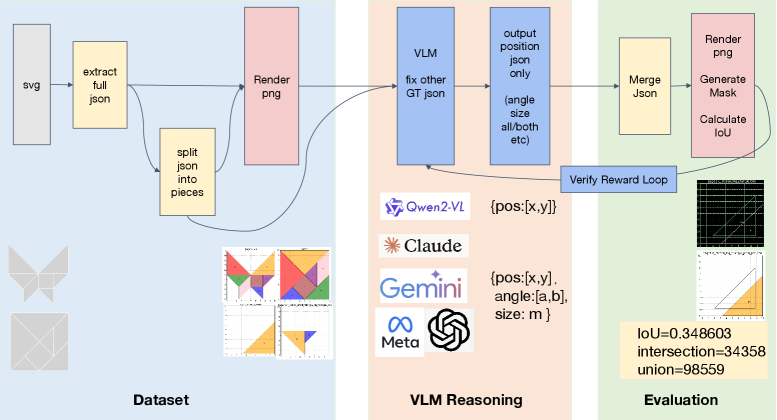
问题定义:论文旨在解决视觉-语言模型在连续几何空间进行复杂推理时表现不佳的问题,具体体现在切磋拼图任务上。现有方法通常难以进行迭代细化和利用几何约束,导致性能远低于人类水平。现有方法的痛点在于缺乏有效的自改进机制,无法在测试时动态调整和优化预测结果。
核心思路:论文的核心思路是模拟人类解决切磋拼图的认知过程,即通过试错、观察和纠正来进行迭代优化。通过引入上下文学习和奖励引导的反馈循环,使模型能够在测试时进行自精炼,从而提高几何推理能力。这种方法的核心在于利用几何一致性作为奖励信号,指导模型逐步改进预测结果。
技术框架:整体框架包含一个验证器-精炼器代理,该代理通过递归精炼循环进行迭代优化。首先,利用上下文学习(ICL)为视觉-语言模型提供初始提示。然后,验证器评估当前预测的几何一致性,并生成奖励信号。精炼器根据奖励信号调整预测结果,并重复此过程,直到达到预定的迭代次数或满足收敛条件。整个过程无需模型重新训练,完全在测试时进行。
关键创新:最重要的技术创新点在于提出了一个免训练的自精炼框架,该框架能够利用几何约束作为奖励信号,指导视觉-语言模型进行迭代优化。与现有方法相比,该框架不需要任何参数更新,即可显著提升几何推理能力。此外,该框架的设计灵感来源于人类认知过程,使其更具可解释性和泛化能力。
关键设计:框架的关键设计包括:1)上下文学习的提示工程,选择合适的示例以引导模型进行推理;2)几何一致性验证器的设计,用于评估预测结果的几何有效性;3)奖励函数的设计,用于量化几何一致性并指导精炼器进行优化;4)迭代次数的设置,需要在计算成本和性能提升之间进行权衡。
🖼️ 关键图片
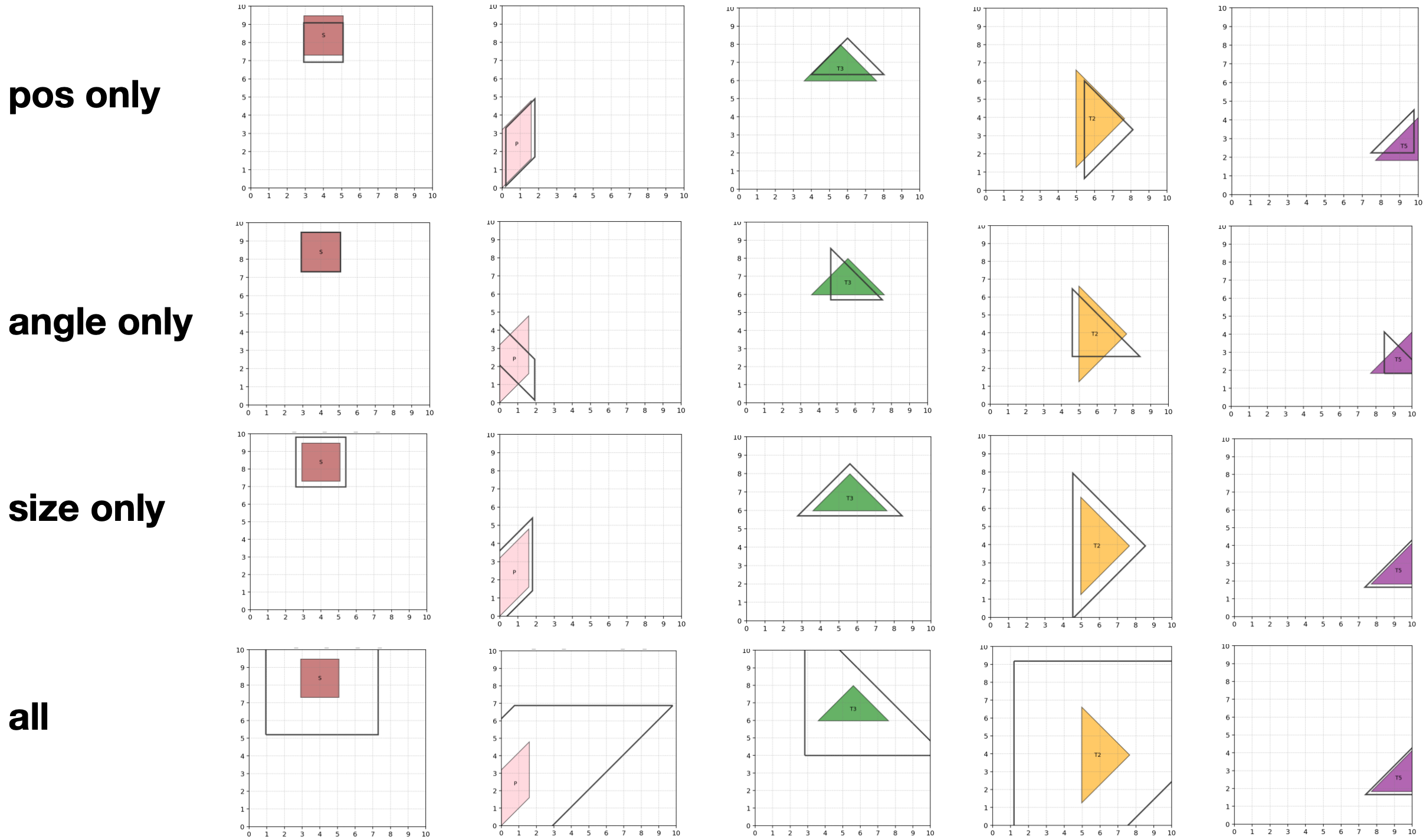
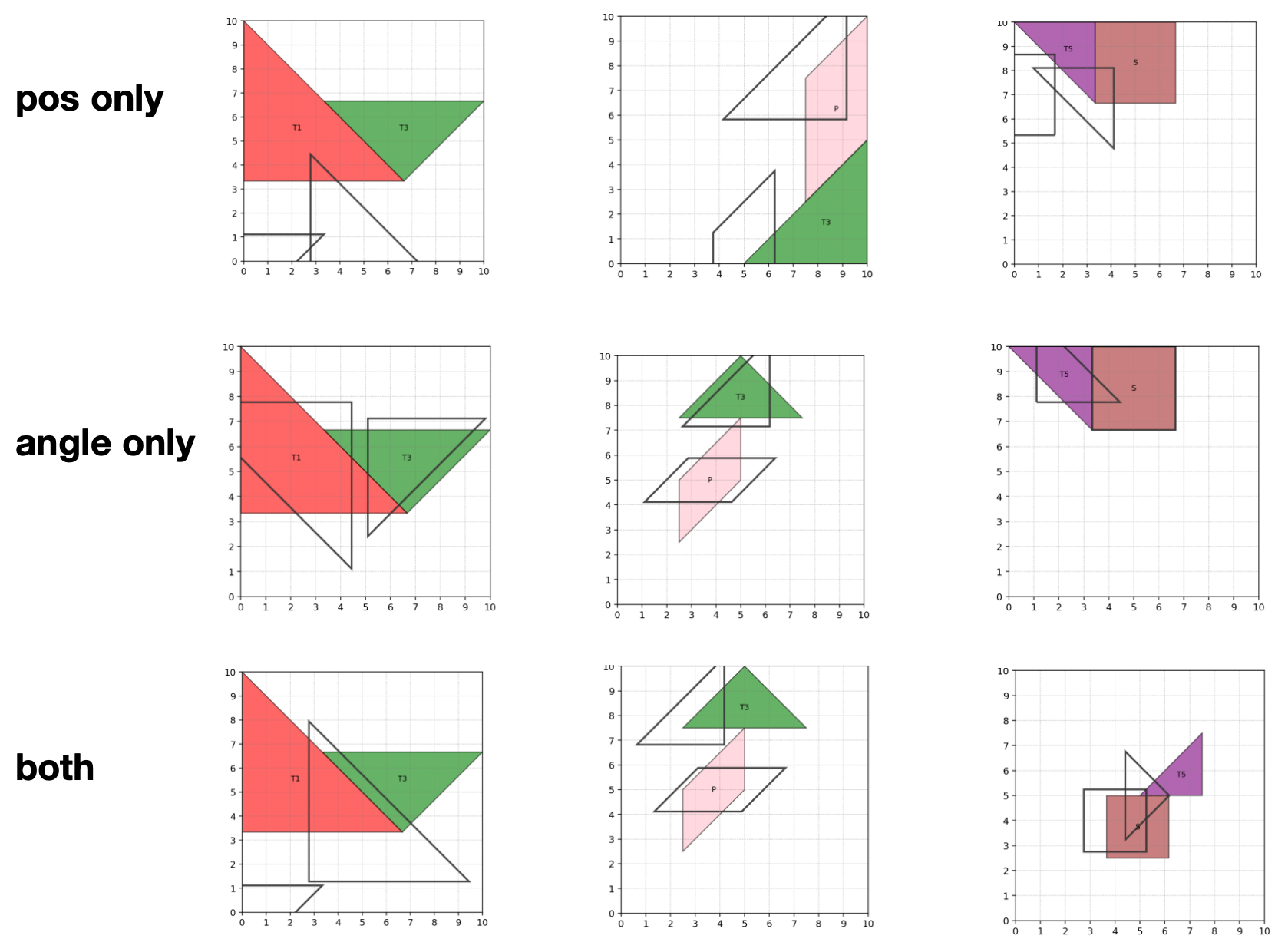
📊 实验亮点
实验结果表明,该框架在切磋拼图任务中取得了显著的性能提升。在中等三角形案例中,IoU从0.63提升至0.932,无需任何模型重新训练。与直接使用视觉-语言模型进行预测相比,该框架能够显著提高几何推理的准确性和鲁棒性。该结果验证了基于人类认知过程的自精炼框架的有效性。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、增强现实等领域,提升智能体在复杂空间环境中的感知和决策能力。例如,机器人可以利用该框架进行物体抓取、装配等任务,自动驾驶系统可以利用该框架进行场景理解和路径规划。此外,该研究还为开发更智能、更具适应性的AI系统提供了新的思路。
📄 摘要(原文)
Humans excel at spatial reasoning tasks like Tangram puzzle assembly through cognitive processes involving mental rotation, iterative refinement, and visual feedback. Inspired by how humans solve Tangram puzzles through trial-and-error, observation, and correction, we design a framework that models these human cognitive mechanisms. However, comprehensive experiments across five representative Vision-Language Models (VLMs) reveal systematic failures in continuous geometric reasoning: average IoU of only 0.41 on single-piece tasks, dropping to 0.23 on two-piece composition, far below human performance where children can complete Tangram tasks successfully. This paper addresses a fundamental challenge in self-improving AI: can models iteratively refine their predictions at test time without parameter updates? We introduce a test-time self-refinement framework that combines in-context learning (ICL) with reward-guided feedback loops, inspired by human cognitive processes. Our training-free verifier-refiner agent applies recursive refinement loops that iteratively self-refine predictions based on geometric consistency feedback, achieving IoU improvements from 0.63 to 0.932 on medium-triangle cases without any model retraining. This demonstrates that incorporating human-inspired iterative refinement mechanisms through ICL and reward loops can substantially enhance geometric reasoning in VLMs, moving self-improving AI from promise to practice in continuous spatial domains. Our work is available at this anonymous link https://anonymous.4open.science/r/TangramVLM-F582/.