SDFP: Speculative Decoding with FIT-Pruned Models for Training-Free and Plug-and-Play LLM Acceleration
作者: Hanyu Wei, Zunhai Su, Peng Lu, Chao Li, Spandan Tiwari, Ashish Sirasao, Yuhan Dong
分类: cs.AI
发布日期: 2026-02-05
💡 一句话要点
SDFP:基于FIT剪枝模型的免训练推测解码,加速LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推测解码 模型剪枝 Fisher信息迹 免训练 低延迟推理 多媒体应用
📋 核心要点
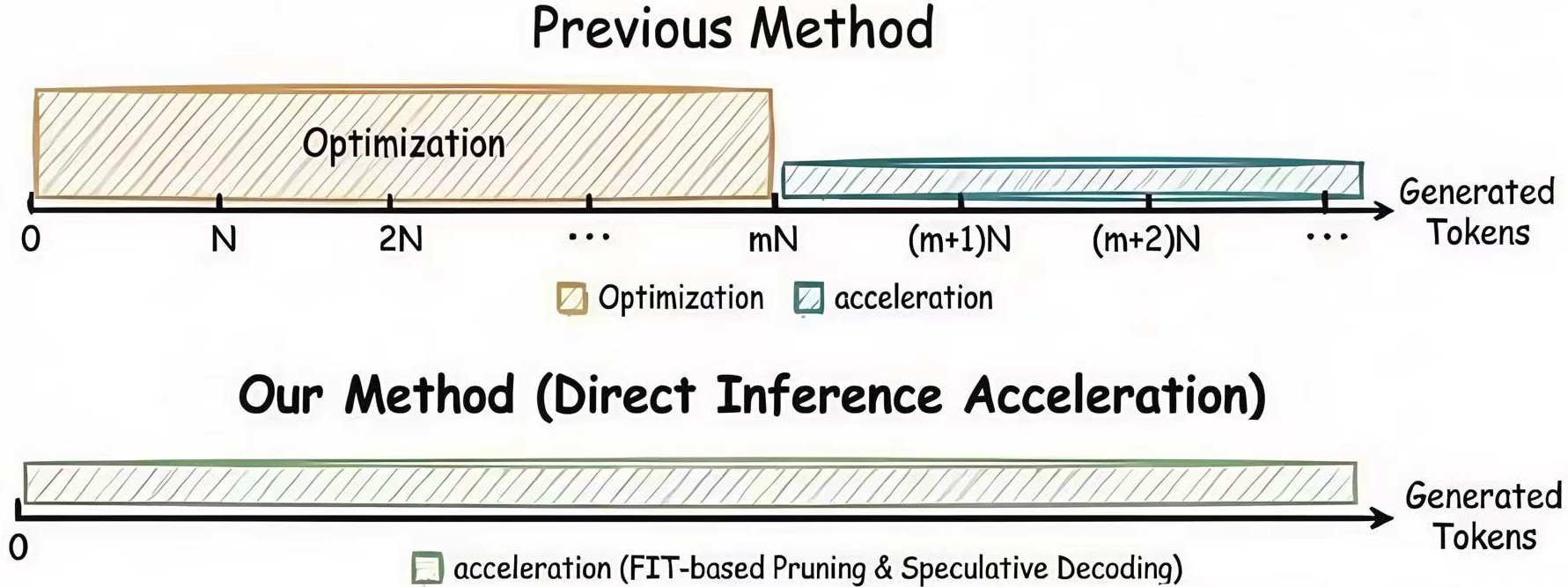
- 现有推测解码方法依赖于额外训练或复杂的搜索优化,增加了部署成本和难度。
- SDFP通过Fisher信息迹剪枝LLM,构建轻量级草稿模型,无需额外训练和调参。
- 实验表明,SDFP在多个基准测试中实现了1.32x-1.5x的解码加速,且不影响模型输出。
📝 摘要(中文)
大型语言模型(LLMs)是字幕生成、检索、推荐和创意内容生成等交互式多媒体应用的基础,但其自回归解码会产生显著的延迟。推测解码使用轻量级的草稿模型来减少延迟,但部署通常受到获取、调整和维护有效草稿模型的成本和复杂性的限制。最近的方法通常需要辅助训练或专门化,甚至免训练的方法也会产生昂贵的搜索或优化。我们提出了SDFP,一个完全免训练和即插即用的框架,通过基于Fisher信息迹(FIT)的给定LLM的层剪枝来构建草稿模型。SDFP使用层敏感性作为输出扰动的代理,移除低影响层以获得紧凑的草稿,同时保持与原始模型的兼容性以进行标准推测验证。SDFP不需要额外的训练、超参数调整或单独维护的草稿,从而能够快速构建易于部署的草稿。在多个基准测试中,SDFP提供1.32倍-1.5倍的解码加速,而不会改变目标模型的输出分布,从而支持低延迟多媒体应用。
🔬 方法详解
问题定义:大型语言模型推理速度慢,尤其是在自回归解码阶段。推测解码是一种加速方法,但需要一个轻量级的草稿模型。现有方法要么需要额外的训练数据和计算资源来训练草稿模型,要么需要复杂的搜索和优化过程,增加了部署成本和难度。这些方法难以在资源受限的环境中应用,并且可能引入额外的超参数调优负担。
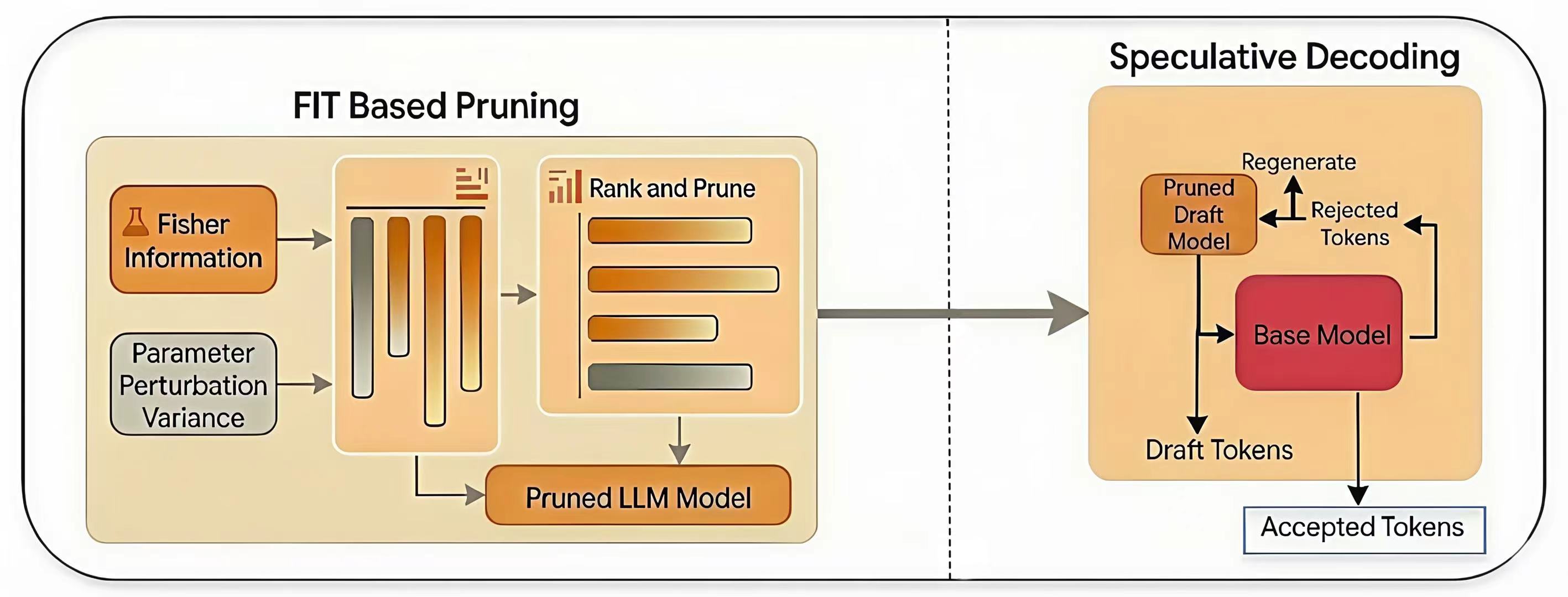
核心思路:SDFP的核心思路是利用Fisher信息迹(FIT)来评估LLM中每一层的重要性,并剪掉那些对输出影响较小的层,从而得到一个轻量级的草稿模型。这种方法无需额外的训练数据或训练过程,直接从原始LLM中提取草稿模型,降低了部署成本。通过保留重要的层,SDFP确保草稿模型与原始模型具有足够的兼容性,从而保证推测解码的准确性。
技术框架:SDFP框架主要包含两个阶段:1) 基于FIT的层剪枝:计算原始LLM每一层的Fisher信息迹,并根据其大小对层进行排序。然后,逐步剪掉FIT值较低的层,直到达到预期的模型大小。2) 推测解码:使用剪枝后的模型作为草稿模型,对原始LLM的输出进行推测。如果推测结果被原始模型验证通过,则接受该结果;否则,使用原始模型的输出。
关键创新:SDFP的关键创新在于提出了一种完全免训练的草稿模型构建方法。通过利用Fisher信息迹进行层剪枝,SDFP避免了额外的训练数据和计算资源的需求,降低了部署成本。此外,SDFP是一种即插即用的方法,可以直接应用于现有的LLM,无需修改原始模型的结构或参数。
关键设计:SDFP的关键设计在于Fisher信息迹的计算和层剪枝策略。Fisher信息迹用于衡量每一层对模型输出的影响,其计算公式涉及模型参数的梯度和损失函数。层剪枝策略则决定了如何选择要剪掉的层,以及剪枝的程度。论文中可能详细描述了具体的FIT计算方法和剪枝阈值的选择。
🖼️ 关键图片

📊 实验亮点
SDFP在多个基准测试中实现了显著的解码加速,达到了1.32x-1.5x的加速效果,且没有改变目标模型的输出分布。这意味着SDFP可以在不牺牲模型准确性的前提下,显著提升LLM的推理速度。与其他需要额外训练或优化的方法相比,SDFP具有更高的效率和更低的部署成本。
🎯 应用场景
SDFP适用于各种需要低延迟LLM推理的多媒体应用,例如实时字幕生成、快速信息检索、个性化推荐和创意内容生成。该方法无需额外训练,易于部署,可以显著降低LLM推理的延迟,提升用户体验。未来,SDFP可以应用于边缘设备,实现本地化的LLM推理。
📄 摘要(原文)
Large language models (LLMs) underpin interactive multimedia applications such as captioning, retrieval, recommendation, and creative content generation, yet their autoregressive decoding incurs substantial latency. Speculative decoding reduces latency using a lightweight draft model, but deployment is often limited by the cost and complexity of acquiring, tuning, and maintaining an effective draft model. Recent approaches usually require auxiliary training or specialization, and even training-free methods incur costly search or optimization. We propose SDFP, a fully training-free and plug-and-play framework that builds the draft model via Fisher Information Trace (FIT)-based layer pruning of a given LLM. Using layer sensitivity as a proxy for output perturbation, SDFP removes low-impact layers to obtain a compact draft while preserving compatibility with the original model for standard speculative verification. SDFP needs no additional training, hyperparameter tuning, or separately maintained drafts, enabling rapid, deployment-friendly draft construction. Across benchmarks, SDFP delivers 1.32x-1.5x decoding speedup without altering the target model's output distribution, supporting low-latency multimedia applications.