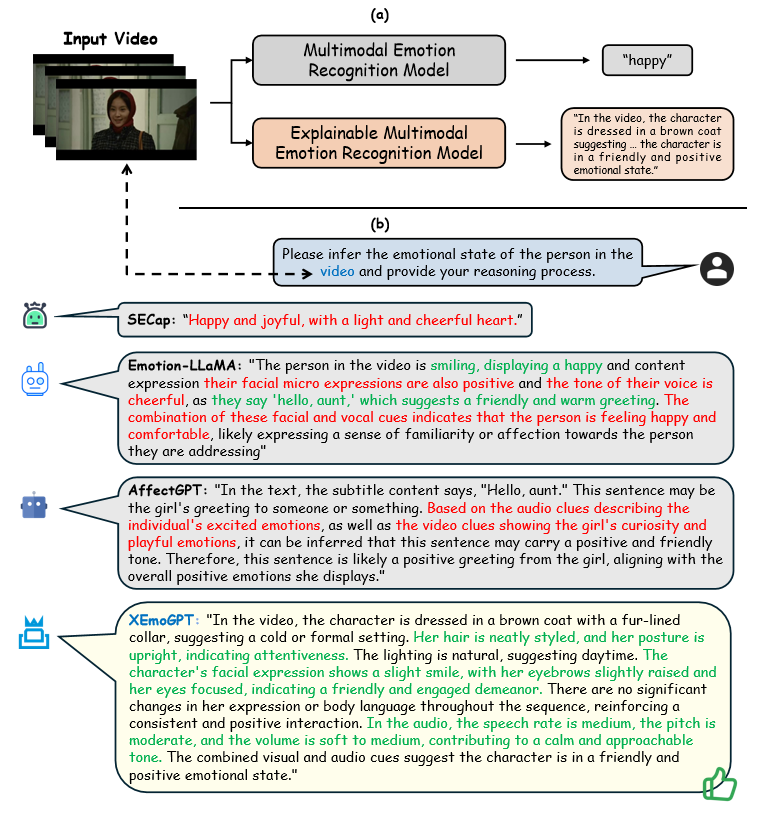
XEmoGPT: An Explainable Multimodal Emotion Recognition Framework with Cue-Level Perception and Reasoning
作者: Hanwen Zhang, Yao Liu, Peiyuan Jiang, Lang Junjie, Xie Jun, Yihui He, Yajiao Deng, Siyu Du, Qiao Liu
分类: cs.MM, cs.AI, cs.CV
发布日期: 2026-02-05
💡 一句话要点
XEmoGPT:提出一种可解释的多模态情感识别框架,关注线索级感知与推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感识别 情感线索感知 可解释性 人机交互 深度学习
📋 核心要点
- 现有方法难以捕捉细粒度情感线索,通用编码器对情感信号敏感性不足,数据集标注质量和规模存在权衡。
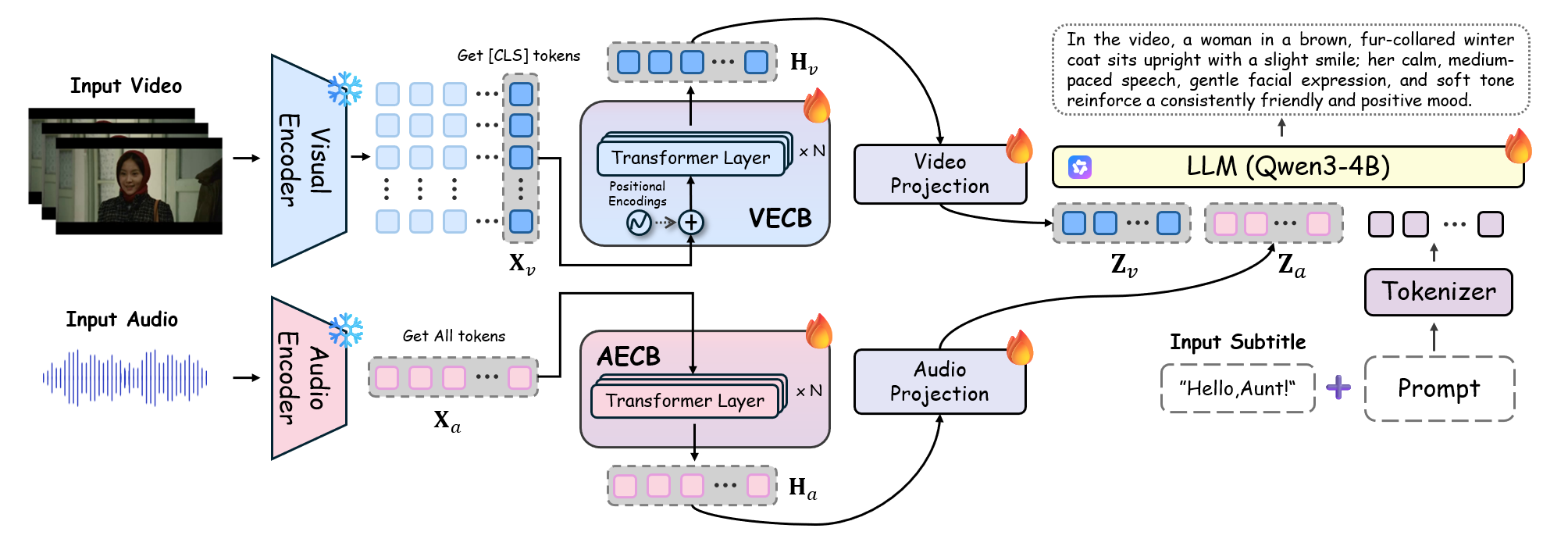
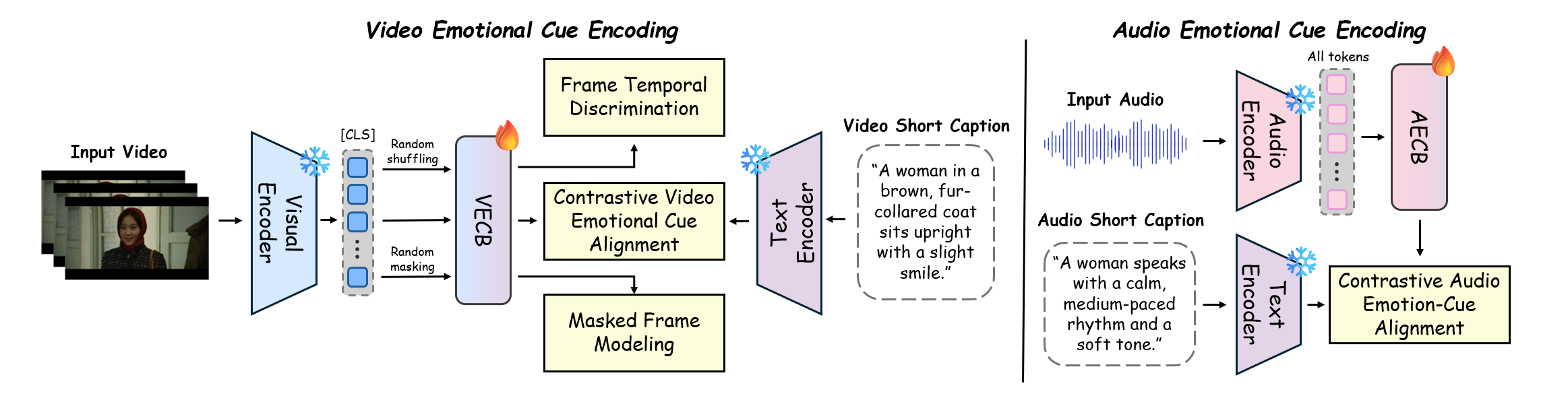
- XEmoGPT通过视频和音频情感线索桥(VECB和AECB)增强编码器,实现细粒度情感线索感知与推理。
- 构建大规模数据集EmoCue,并提出EmoCue-360自动化评估指标和EmoCue-Eval基准,实验表明XEmoGPT性能优异。
📝 摘要(中文)
可解释的多模态情感识别在人机交互和社交媒体分析等应用中至关重要。然而,现有方法在提示线索级别的感知和推理方面存在困难,主要面临两个挑战:1) 通用模态编码器预训练用于捕获全局结构和通用语义,而非细粒度的情感线索,导致对情感信号的敏感性有限;2) 可用数据集通常在标注质量和规模之间进行权衡,导致对情感线索的监督不足,最终限制了线索级别的推理。此外,现有的评估指标不足以评估线索级别的推理性能。为了应对这些挑战,我们提出了解释性情感GPT(XEmoGPT),这是一种新型的EMER框架,能够感知和推理情感线索。它包含两个专门的模块:视频情感线索桥(VECB)和音频情感线索桥(AECB),通过精心设计的任务来增强视频和音频编码器,以实现细粒度的情感线索感知。为了进一步支持线索级别的推理,我们构建了一个大规模数据集EmoCue,旨在教导XEmoGPT如何推理多模态情感线索。此外,我们引入了EmoCue-360,一种使用语义相似性提取和匹配情感线索的自动化指标,并发布了EmoCue-Eval,一个包含400个专家标注样本的基准,涵盖了各种情感场景。实验结果表明,XEmoGPT在情感线索感知和推理方面都取得了强大的性能。
🔬 方法详解
问题定义:现有方法在多模态情感识别中,难以有效感知和推理细粒度的情感线索。通用模态编码器侧重于全局语义,忽略了情感表达的细微之处。同时,现有数据集在标注质量和数据规模上存在trade-off,限制了模型对情感线索的学习能力。此外,缺乏针对线索级别推理的有效评估指标。
核心思路:XEmoGPT的核心思路是通过引入专门设计的模块(VECB和AECB)来增强视频和音频编码器,使其能够更好地感知细粒度的情感线索。同时,构建大规模数据集EmoCue,为模型提供更充分的训练数据,并设计新的评估指标EmoCue-360和EmoCue-Eval,以更准确地评估模型在线索级别推理上的性能。
技术框架:XEmoGPT框架主要包含以下几个部分:1) 视频编码器和音频编码器:用于提取视频和音频模态的特征。2) 视频情感线索桥(VECB):用于增强视频编码器对情感线索的感知能力。3) 音频情感线索桥(AECB):用于增强音频编码器对情感线索的感知能力。4) 多模态融合模块:用于融合视频和音频特征,进行情感预测。5) EmoCue数据集:用于训练模型。6) EmoCue-360和EmoCue-Eval:用于评估模型性能。
关键创新:XEmoGPT的关键创新在于:1) 提出了VECB和AECB模块,通过精心设计的任务来增强编码器对情感线索的感知能力。2) 构建了大规模数据集EmoCue,为模型提供了更充分的训练数据。3) 提出了EmoCue-360和EmoCue-Eval评估指标,可以更准确地评估模型在线索级别推理上的性能。与现有方法相比,XEmoGPT更注重细粒度情感线索的感知和推理,并提供了更全面的评估方法。
关键设计:VECB和AECB的具体设计细节未知,论文中可能未详细公开。EmoCue数据集的构建方式和标注规范是关键设计,EmoCue-360评估指标中语义相似性的计算方法也至关重要。损失函数的设计可能包括情感分类损失、线索预测损失等,以促进模型学习情感线索的表达。
🖼️ 关键图片
📊 实验亮点
实验结果表明,XEmoGPT在情感线索感知和推理方面都取得了显著的性能提升。具体的数据和对比基线需要在论文中查找,但摘要中强调了其在情感线索感知和推理方面的强大性能,表明其优于现有的多模态情感识别方法。EmoCue-360和EmoCue-Eval的引入也为更全面地评估模型性能提供了可能。
🎯 应用场景
XEmoGPT可应用于人机交互领域,例如情感智能助手,能够更准确地理解用户的情感状态并做出相应的反应。在社交媒体分析中,可以用于识别和分析用户的情绪,从而更好地理解舆情和用户需求。该研究有助于提升情感识别的准确性和可解释性,促进人机之间的有效沟通。
📄 摘要(原文)
Explainable Multimodal Emotion Recognition plays a crucial role in applications such as human-computer interaction and social media analytics. However, current approaches struggle with cue-level perception and reasoning due to two main challenges: 1) general-purpose modality encoders are pretrained to capture global structures and general semantics rather than fine-grained emotional cues, resulting in limited sensitivity to emotional signals; and 2) available datasets usually involve a trade-off between annotation quality and scale, which leads to insufficient supervision for emotional cues and ultimately limits cue-level reasoning. Moreover, existing evaluation metrics are inadequate for assessing cue-level reasoning performance. To address these challenges, we propose eXplainable Emotion GPT (XEmoGPT), a novel EMER framework capable of both perceiving and reasoning over emotional cues. It incorporates two specialized modules: the Video Emotional Cue Bridge (VECB) and the Audio Emotional Cue Bridge (AECB), which enhance the video and audio encoders through carefully designed tasks for fine-grained emotional cue perception. To further support cue-level reasoning, we construct a large-scale dataset, EmoCue, designed to teach XEmoGPT how to reason over multimodal emotional cues. In addition, we introduce EmoCue-360, an automated metric that extracts and matches emotional cues using semantic similarity, and release EmoCue-Eval, a benchmark of 400 expert-annotated samples covering diverse emotional scenarios. Experimental results show that XEmoGPT achieves strong performance in both emotional cue perception and reasoning.