LMMRec: LLM-driven Motivation-aware Multimodal Recommendation
作者: Yicheng Di, Zhanjie Zhang, Yun Wangc, Jinren Liue, Jiaqi Yanf, Jiyu Wei, Xiangyu Chend, Yuan Liu
分类: cs.IR, cs.AI
发布日期: 2026-02-05
💡 一句话要点
LMMRec:提出基于LLM的动机感知多模态推荐框架,提升推荐性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 多模态学习 大型语言模型 动机建模 对比学习
📋 核心要点
- 现有推荐方法忽略了评论文本等异构信息,且在多模态动机融合中难以实现稳定的跨模态对齐。
- LMMRec利用大型语言模型提取细粒度的用户和项目动机,并设计双编码器架构进行跨模态对齐。
- 实验结果表明,LMMRec在三个数据集上实现了显著的性能提升,最高可达4.98%。
📝 摘要(中文)
基于动机的推荐系统旨在挖掘用户行为的驱动因素。动机建模对于决策制定和内容偏好至关重要,并解释了推荐的生成过程。现有方法通常将动机视为来自交互数据的潜在变量,忽略了评论文本等异构信息。在多模态动机融合中,存在两个挑战:1)在噪声中实现稳定的跨模态对齐;2)识别反映跨模态相同底层动机的特征。为了解决这些问题,我们提出了LLM驱动的动机感知多模态推荐(LMMRec),这是一个模型无关的框架,利用大型语言模型进行深度语义先验和动机理解。LMMRec使用思维链提示从文本中提取细粒度的用户和项目动机。双编码器架构对基于文本和交互的动机进行建模,以实现跨模态对齐,而动机协调策略和交互-文本对应方法通过对比学习和动量更新来减轻噪声和语义漂移。在三个数据集上的实验表明,LMMRec实现了高达4.98%的性能提升。
🔬 方法详解
问题定义:现有推荐系统在建模用户和物品的动机时,主要依赖于交互数据,忽略了评论文本等异构信息,导致动机理解不充分。此外,在融合多模态信息时,容易受到噪声干扰,难以实现稳定的跨模态对齐,并且难以识别不同模态中反映相同底层动机的特征。
核心思路:LMMRec的核心思路是利用大型语言模型(LLM)的强大语义理解能力,从文本数据中提取细粒度的用户和物品动机,并将其与交互数据进行融合,从而更准确地建模用户和物品的动机。通过跨模态对齐和对比学习,减轻噪声干扰,提高模型的鲁棒性。
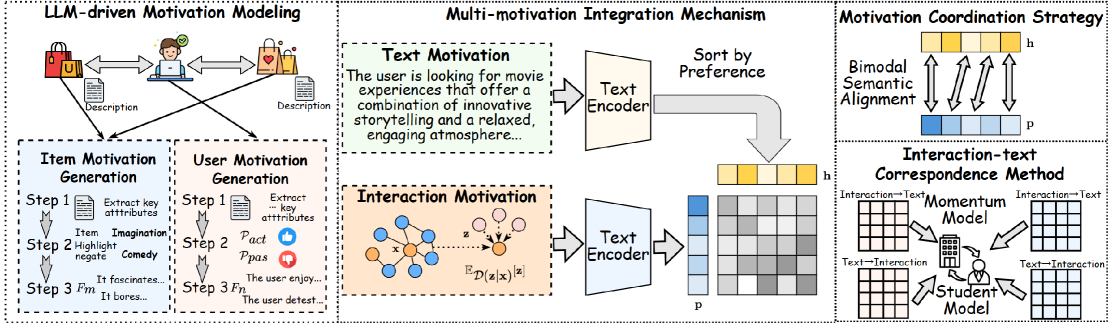
技术框架:LMMRec框架主要包含以下几个模块:1) LLM动机提取模块:利用Chain-of-Thought prompting从用户评论和物品描述中提取细粒度的用户和物品动机。2) 双编码器模块:分别对文本模态和交互模态的动机进行编码,得到相应的向量表示。3) 跨模态对齐模块:通过对比学习,将文本模态和交互模态的动机向量对齐到同一语义空间。4) 动机协调策略:通过动量更新机制,减轻噪声和语义漂移的影响。5) 交互-文本对应方法:进一步增强文本和交互数据之间的对应关系,提高模型的泛化能力。
关键创新:LMMRec的关键创新在于:1) 引入LLM进行动机提取:利用LLM的强大语义理解能力,从文本数据中提取细粒度的用户和物品动机,弥补了现有方法对文本信息利用不足的缺陷。2) 提出动机协调策略和交互-文本对应方法:通过对比学习和动量更新,减轻噪声干扰,提高模型的鲁棒性和泛化能力。
关键设计:1) LLM Prompt设计:采用Chain-of-Thought prompting,引导LLM逐步推理,提取更准确的动机信息。2) 对比学习损失函数:设计对比学习损失函数,促使文本模态和交互模态的动机向量对齐。3) 动量更新机制:采用动量更新机制,平滑模型参数,减轻噪声和语义漂移的影响。4) 双编码器结构:采用双编码器结构,分别对文本模态和交互模态的动机进行编码,便于后续的跨模态对齐。
🖼️ 关键图片

📊 实验亮点
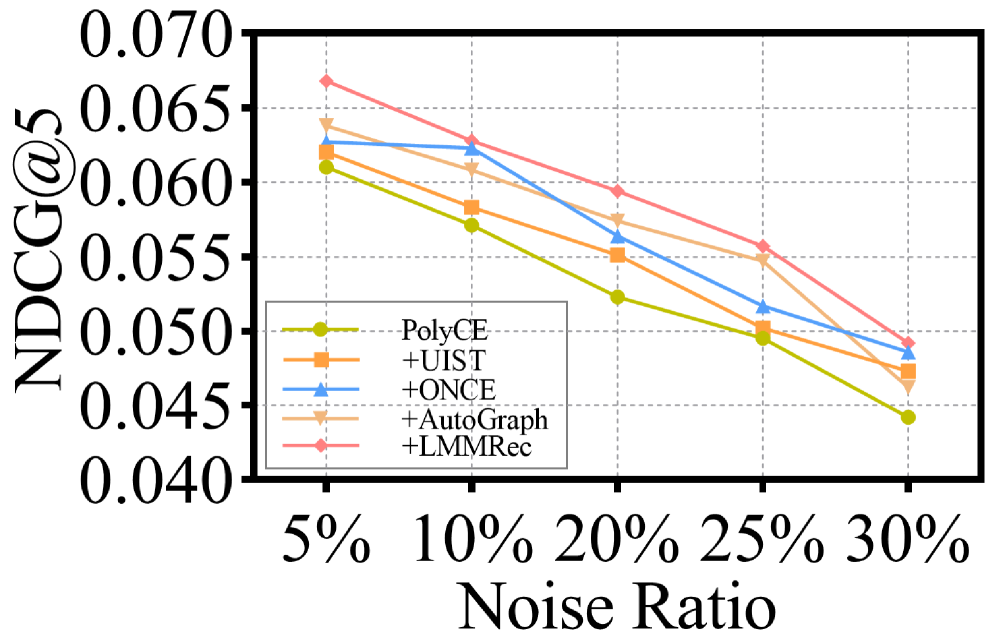
在三个数据集上的实验结果表明,LMMRec相比于现有方法取得了显著的性能提升。具体来说,LMMRec在Recall@K和NDCG@K等指标上均优于基线模型,最高可实现4.98%的性能提升。实验结果验证了LMMRec在建模用户和物品动机方面的有效性,以及其在跨模态对齐和噪声抑制方面的优势。
🎯 应用场景
LMMRec可应用于电商推荐、电影推荐、音乐推荐等领域,通过更准确地理解用户和物品的动机,提高推荐的个性化程度和用户满意度。该研究有助于提升推荐系统的解释性,使用户更容易理解推荐的原因,从而增强用户对推荐系统的信任感。未来,可以将LMMRec扩展到更多的模态数据,例如图像和视频,以进一步提高推荐性能。
📄 摘要(原文)
Motivation-based recommendation systems uncover user behavior drivers. Motivation modeling, crucial for decision-making and content preference, explains recommendation generation. Existing methods often treat motivation as latent variables from interaction data, neglecting heterogeneous information like review text. In multimodal motivation fusion, two challenges arise: 1) achieving stable cross-modal alignment amid noise, and 2) identifying features reflecting the same underlying motivation across modalities. To address these, we propose LLM-driven Motivation-aware Multimodal Recommendation (LMMRec), a model-agnostic framework leveraging large language models for deep semantic priors and motivation understanding. LMMRec uses chain-of-thought prompting to extract fine-grained user and item motivations from text. A dual-encoder architecture models textual and interaction-based motivations for cross-modal alignment, while Motivation Coordination Strategy and Interaction-Text Correspondence Method mitigate noise and semantic drift through contrastive learning and momentum updates. Experiments on three datasets show LMMRec achieves up to a 4.98\% performance improvement.