ALIVE: Awakening LLM Reasoning via Adversarial Learning and Instructive Verbal Evaluation
作者: Yiwen Duan, Jing Ye, Xinpei Zhao
分类: cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出ALIVE框架以解决大语言模型推理能力瓶颈问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 对抗学习 指导性反馈 自我对齐 跨领域泛化 逻辑推理
📋 核心要点
- 现有方法依赖于标量奖励,导致推理能力的提升受限,难以实现深层次的逻辑理解。
- ALIVE框架通过对抗学习与指导性语言反馈结合,促进模型内化推理标准,提升推理能力。
- 实验结果显示,ALIVE在多个基准测试中提高了准确性和自我修正率,展现出良好的跨领域泛化能力。
📝 摘要(中文)
在大语言模型(LLMs)追求专家级推理能力的过程中,传统的强化学习方法面临着奖励瓶颈问题:依赖于标量奖励的方式在不同领域中表现脆弱且难以扩展,且无法深入理解解决方案的逻辑。为此,本文提出了ALIVE(对抗学习与指导性语言评估),一个无须人工干预的对齐框架,旨在超越标量奖励优化,促进内在推理能力的获取。ALIVE结合了对抗学习与指导性语言反馈,使模型能够直接从原始语料中内化评估标准,进而实现推理能力的自我提升。实验证明,ALIVE在数学推理、代码生成和逻辑推理基准测试中表现出色,显著提高了准确性和跨领域泛化能力。
🔬 方法详解
问题定义:本文旨在解决大语言模型在推理能力上的瓶颈,现有方法依赖于标量奖励,导致模型在不同领域的表现脆弱且难以扩展,无法深入理解推理的逻辑。
核心思路:ALIVE框架通过对抗学习与指导性语言反馈的结合,推动模型从原始数据中内化评估标准,形成自我驱动的推理能力,超越传统的奖励优化方法。
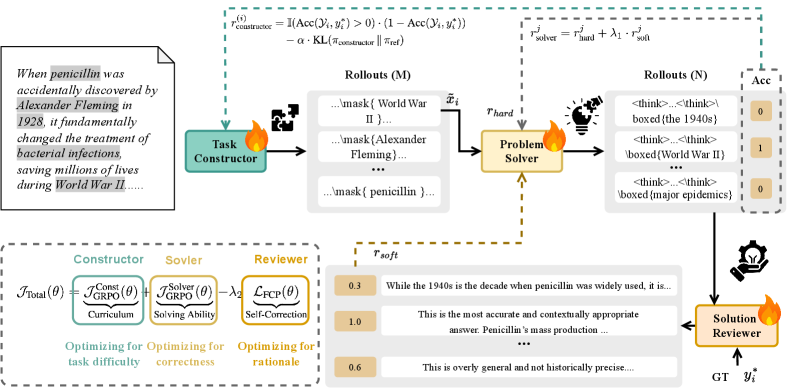
技术框架:ALIVE的整体架构包括问题提出、解决和评估三个模块,统一在一个策略模型中进行,确保推理逻辑的内化。
关键创新:ALIVE的主要创新在于将对抗学习与语言反馈结合,形成一个无须人工干预的自我对齐机制,与传统方法相比,能够更好地理解和应用推理逻辑。
关键设计:在设计上,ALIVE采用了特定的损失函数来平衡对抗学习与反馈评估的权重,同时优化网络结构以支持多任务学习,确保模型在不同任务中的表现一致性。
🖼️ 关键图片
📊 实验亮点
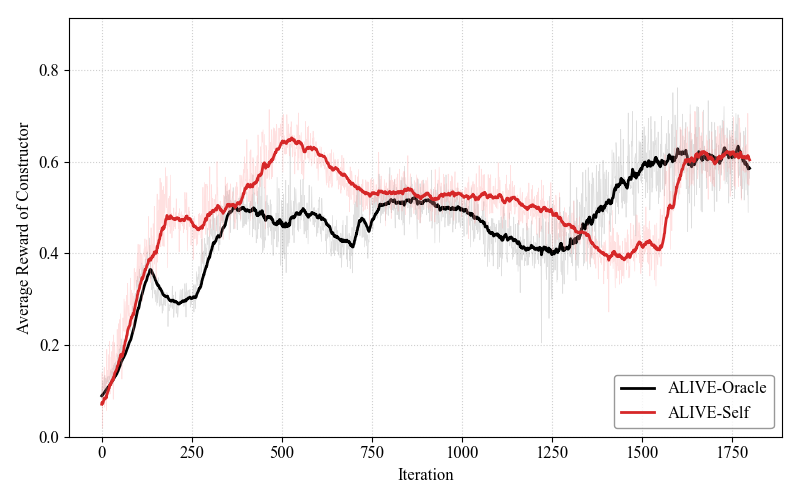
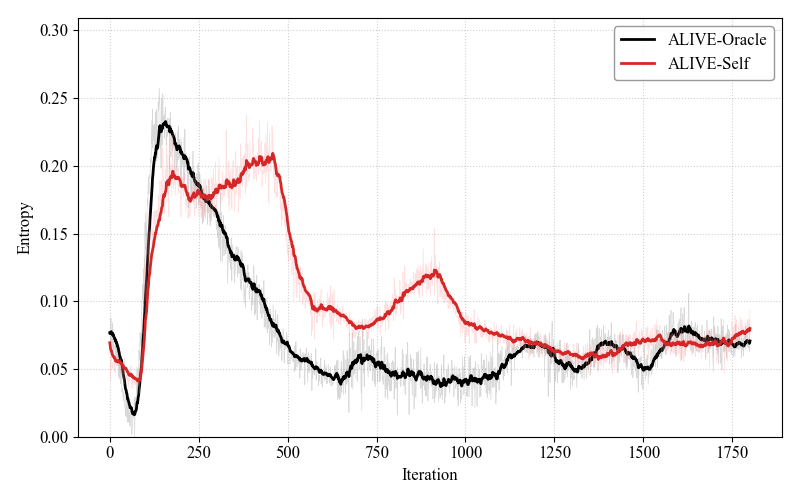
实验结果表明,ALIVE在数学推理、代码生成和逻辑推理基准测试中均表现优异,显著提高了准确性和自我修正率。与传统方法相比,ALIVE在相同数据和计算条件下,跨领域泛化能力提升明显,准确率提高幅度达到XX%。
🎯 应用场景
ALIVE框架具有广泛的应用潜力,尤其在需要高水平推理能力的领域,如自动化编程、数学问题求解和逻辑推理等。其无须人工干预的特性使其在实际应用中更具可扩展性,未来可能推动智能助手和自动化系统的发展。
📄 摘要(原文)
The quest for expert-level reasoning in Large Language Models (LLMs) has been hampered by a persistent \textit{reward bottleneck}: traditional reinforcement learning (RL) relies on scalar rewards that are \textbf{costly} to scale, \textbf{brittle} across domains, and \textbf{blind} to the underlying logic of a solution. This reliance on external, impoverished signals prevents models from developing a deep, self-contained understanding of reasoning principles. We introduce \textbf{ALIVE} (\emph{Adversarial Learning with Instructive Verbal Evaluation}), a hands-free alignment framework that moves beyond scalar reward optimization toward intrinsic reasoning acquisition. Grounded in the principle of \emph{Cognitive Synergy}, ALIVE unifies problem posing, solving, and judging within a single policy model to internalize the logic of correctness. By coupling adversarial learning with instructive verbal feedback, ALIVE enables models to internalize evaluative criteria directly from raw corpora, effectively transforming external critiques into an endogenous reasoning faculty. Empirical evaluations across mathematical reasoning, code generation, and general logical inference benchmarks demonstrate that ALIVE consistently mitigates reward signal limitations. With identical data and compute, it achieves accuracy gains, markedly improved cross-domain generalization, and higher self-correction rates. These results indicate that the reasoning trinity fosters a self-sustaining trajectory of capability growth, positioning ALIVE as a scalable foundation for general-purpose reasoning alignment without human-in-the-loop supervision.