RaBiT: Residual-Aware Binarization Training for Accurate and Efficient LLMs
作者: Youngcheon You, Banseok Lee, Minseop Choi, Seonyoung Kim, Hyochan Chong, Changdong Kim, Youngmin Kim, Dongkyu Kim
分类: cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出RaBiT以解决大语言模型量化中的特征共适应问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化训练 残差二值化 特征共适应 推理速度提升 自然语言处理 高效推理
📋 核心要点
- 现有的量化方法在训练过程中容易导致特征共适应,影响模型的表达能力和性能。
- RaBiT通过算法性地强制残差层次结构,确保每个二进制路径都能有效纠正前一个路径的错误。
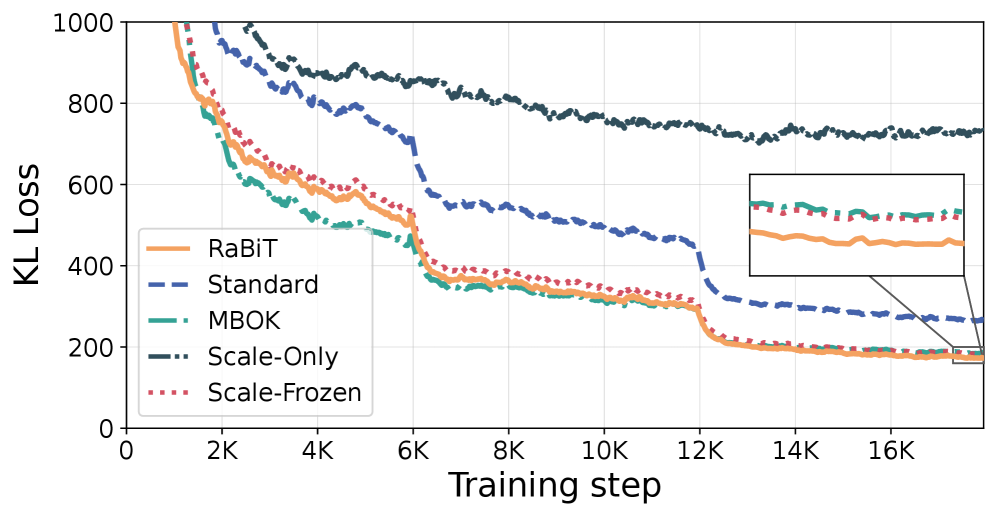
- 实验结果显示,RaBiT在2比特精度效率上达到了最先进的性能,并在推理速度上显著优于全精度模型。
📝 摘要(中文)
大语言模型(LLMs)的高效部署需要极端量化,这在低比特效率与性能之间形成了关键的权衡。残差二值化通过堆叠二进制层实现硬件友好的推理,但存在特征共适应的问题。本文提出RaBiT,一个新颖的量化框架,通过算法性地强制残差层次结构来解决共适应问题。RaBiT的核心机制是从单一共享的全精度权重中逐步推导每个二进制路径,确保每个路径都能纠正前一个路径的错误。实验结果表明,RaBiT在2比特精度效率的前沿重新定义了性能,甚至在RTX 4090上实现了相较于全精度模型的4.49倍推理速度提升。
🔬 方法详解
问题定义:本文旨在解决大语言模型在量化过程中出现的特征共适应问题。现有方法如路径冻结等启发式解决方案限制了解决空间,导致模型性能下降。
核心思路:RaBiT的核心思想是通过算法性地强制残差层次结构,确保每个二进制路径都能基于共享的全精度权重进行有效的错误修正,从而避免特征冗余。
技术框架:RaBiT的整体架构包括量化感知训练(QAT)阶段,首先初始化全精度权重,然后逐步推导二进制路径,确保每个路径都能纠正前一个路径的错误。
关键创新:RaBiT的主要创新在于通过算法性地构建残差层次结构,解决了现有方法中的特征共适应问题,使得模型在低比特量化下仍能保持高性能。
关键设计:RaBiT采用了稳健的初始化策略,优先考虑功能保留而非简单的权重近似,确保模型在训练过程中能够有效地保持其表达能力。实验中还使用了特定的损失函数来优化每个二进制路径的学习过程。
🖼️ 关键图片


📊 实验亮点
实验结果显示,RaBiT在2比特精度效率上达到了最先进的性能,甚至与硬件密集型的向量量化方法相媲美。此外,在RTX 4090上,RaBiT实现了相较于全精度模型的4.49倍推理速度提升,展示了其在实际应用中的巨大潜力。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和智能助手等需要高效推理的大语言模型。RaBiT的高效性和准确性使其在资源受限的环境中具有实际价值,能够推动大语言模型的广泛应用。
📄 摘要(原文)
Efficient deployment of large language models (LLMs) requires extreme quantization, forcing a critical trade-off between low-bit efficiency and performance. Residual binarization enables hardware-friendly, matmul-free inference by stacking binary ($\pm$1) layers, but is plagued by pathological feature co-adaptation. We identify a key failure mode, which we term inter-path adaptation: during quantization-aware training (QAT), parallel residual binary paths learn redundant features, degrading the error-compensation structure and limiting the expressive capacity of the model. While prior work relies on heuristic workarounds (e.g., path freezing) that constrain the solution space, we propose RaBiT, a novel quantization framework that resolves co-adaptation by algorithmically enforcing a residual hierarchy. Its core mechanism sequentially derives each binary path from a single shared full-precision weight, which ensures that every path corrects the error of the preceding one. This process is stabilized by a robust initialization that prioritizes functional preservation over mere weight approximation. RaBiT redefines the 2-bit accuracy-efficiency frontier: it achieves state-of-the-art performance, rivals even hardware-intensive Vector Quantization (VQ) methods, and delivers a $4.49\times$ inference speed-up over full-precision models on an RTX 4090.