ProAct: Agentic Lookahead in Interactive Environments
作者: Yangbin Yu, Mingyu Yang, Junyou Li, Yiming Gao, Feiyu Liu, Yijun Yang, Zichuan Lin, Jiafei Lyu, Yicheng Liu, Zhicong Lu, Deheng Ye, Jie Jiang
分类: cs.AI
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
ProAct:通过Agent内部前瞻推理提升交互环境中LLM智能体的规划能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 模仿学习 前瞻推理 交互式环境
📋 核心要点
- 现有LLM智能体在长程规划交互环境中易累积误差,导致规划能力不足。
- ProAct框架通过两阶段训练,使智能体学习环境搜索轨迹中的前瞻推理逻辑。
- 实验表明,ProAct显著提升了智能体的规划准确性,并在泛化能力上表现出色。
📝 摘要(中文)
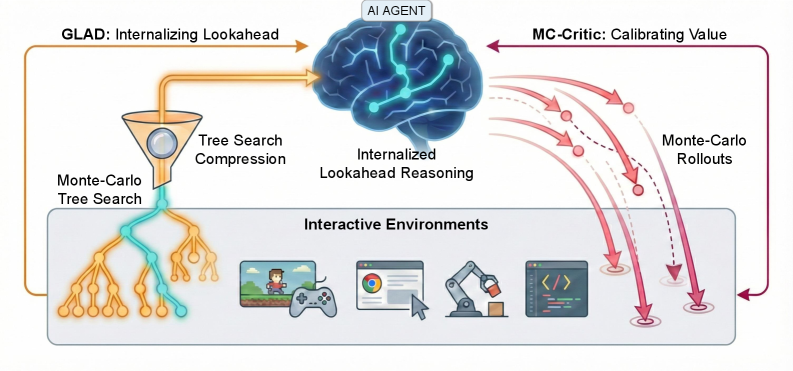
现有的大型语言模型(LLM)智能体在需要长程规划的交互式环境中表现不佳,这主要是由于模拟未来状态时产生的累积误差。为了解决这个问题,我们提出了ProAct框架,该框架使智能体能够通过两阶段训练范式内化准确的前瞻推理。首先,我们引入了Grounded LookAhead Distillation(GLAD),智能体在基于环境搜索的轨迹上进行监督微调。通过将复杂的搜索树压缩成简洁的因果推理链,智能体学习了前瞻的逻辑,而无需推理时搜索的计算开销。其次,为了进一步提高决策准确性,我们提出了蒙特卡洛评论家(MC-Critic),这是一个即插即用的辅助价值估计器,旨在增强策略梯度算法,如PPO和GRPO。通过利用轻量级的环境rollout来校准价值估计,MC-Critic提供了一个低方差的信号,有助于稳定的策略优化,而无需依赖昂贵的基于模型的价值近似。在随机环境(如2048)和确定性环境(如Sokoban)上的实验表明,ProAct显著提高了规划准确性。值得注意的是,一个使用ProAct训练的4B参数模型优于所有开源基线,并且可以与最先进的闭源模型相媲美,同时展示了对未见环境的强大泛化能力。
🔬 方法详解
问题定义:现有LLM智能体在交互式环境中进行长程规划时,由于无法准确模拟未来状态,导致误差累积,最终影响决策质量。现有方法要么计算开销大,要么依赖不准确的模型进行价值估计,难以实现高效且准确的规划。
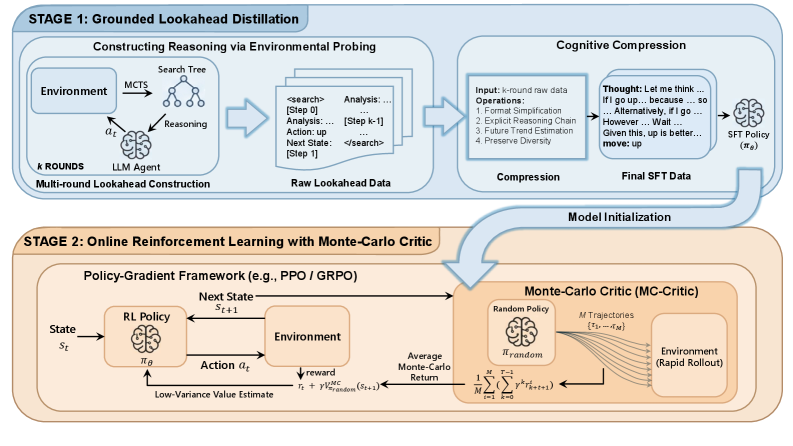
核心思路:ProAct的核心思路是通过模仿学习和强化学习相结合的方式,让智能体学习如何进行有效的前瞻推理。首先,通过模仿环境搜索得到的优质轨迹,让智能体学习到规划的基本逻辑。然后,利用蒙特卡洛方法对价值函数进行校准,从而提高策略优化的稳定性。
技术框架:ProAct框架包含两个主要阶段:Grounded LookAhead Distillation (GLAD) 和 Monte-Carlo Critic (MC-Critic)。在GLAD阶段,智能体通过监督学习,学习从环境搜索得到的轨迹中提取因果关系。在MC-Critic阶段,智能体使用轻量级的环境rollout来校准价值估计,并使用策略梯度算法进行优化。
关键创新:ProAct的关键创新在于将环境搜索与模仿学习相结合,从而避免了推理时进行昂贵的搜索。同时,MC-Critic通过利用环境rollout来校准价值估计,提供了一个低方差的信号,从而提高了策略优化的稳定性。这种方法避免了对复杂环境进行建模,降低了计算成本。
关键设计:GLAD阶段使用交叉熵损失函数来训练智能体模仿环境搜索得到的动作序列。MC-Critic使用蒙特卡洛方法来估计价值函数,并将其作为策略梯度算法的辅助信号。具体来说,MC-Critic通过对当前策略进行少量rollout,计算得到的回报来校准价值函数。这种方法可以有效地降低价值估计的方差,从而提高策略优化的稳定性。
🖼️ 关键图片

📊 实验亮点
ProAct在2048和Sokoban等环境中取得了显著的性能提升。例如,一个使用ProAct训练的4B参数模型在这些环境中的表现优于所有开源基线,并且可以与最先进的闭源模型相媲美。此外,ProAct还展示了对未见环境的强大泛化能力,表明其具有良好的鲁棒性。
🎯 应用场景
ProAct框架可应用于各种需要长程规划的交互式环境,例如游戏AI、机器人导航、任务规划等。该研究成果有助于提升智能体在复杂环境中的决策能力和泛化能力,使其能够更好地完成各种任务。未来,ProAct有望在智能家居、自动驾驶等领域发挥重要作用。
📄 摘要(原文)
Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct