Hallucination-Resistant Security Planning with a Large Language Model
作者: Kim Hammar, Tansu Alpcan, Emil Lupu
分类: cs.AI, cs.CR
发布日期: 2026-02-05
备注: Accepted to IEEE/IFIP Network Operations and Management Symposium 2026. To appear in the conference proceedings
💡 一句话要点
提出一种抗幻觉的安全规划框架,利用大语言模型提升事件响应效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全规划 事件响应 幻觉抑制 上下文学习
📋 核心要点
- 大语言模型在安全管理任务中展现潜力,但其幻觉问题严重影响了可靠性,阻碍了实际应用。
- 论文提出迭代框架,通过一致性检查、外部反馈和上下文学习,降低LLM的幻觉风险,提升决策质量。
- 实验表明,该框架在事件响应场景中,相比现有LLM方法,能显著缩短恢复时间,提升响应效率。
📝 摘要(中文)
本文提出了一种原则性的框架,用于在使用大语言模型(LLM)进行安全管理决策支持时,解决其不可靠性和幻觉问题。该框架将LLM集成到一个迭代循环中,LLM生成候选动作,并检查其与系统约束和前瞻性预测的一致性。当一致性较低时,框架会避免使用生成的动作,而是收集外部反馈,例如通过在数字孪生中评估动作。然后,使用上下文学习(ICL)来改进候选动作。理论证明,该设计允许通过调整一致性阈值来控制幻觉风险。此外,本文还在一定假设下建立了ICL遗憾的界限。为了评估该框架,将其应用于事件响应用例,目标是基于系统日志生成响应和恢复计划。在四个公共数据集上的实验表明,与前沿LLM相比,该框架可将恢复时间缩短高达30%。
🔬 方法详解
问题定义:现有的大语言模型在安全事件响应规划中容易产生幻觉,即生成不符合实际情况或无效的行动方案。这导致安全管理人员无法信任LLM的建议,降低了事件响应的效率和准确性。现有的方法缺乏有效的机制来识别和纠正LLM的幻觉,因此难以在实际的安全管理场景中应用。
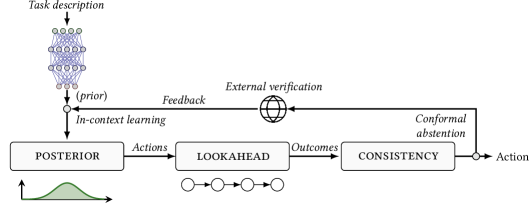
核心思路:论文的核心思路是通过一个迭代的反馈循环来约束LLM的生成过程,并利用外部知识来纠正LLM的幻觉。具体来说,首先让LLM生成候选的行动方案,然后通过一致性检查来评估这些方案的合理性。如果一致性较低,则从外部来源(例如数字孪生)获取反馈,并利用这些反馈来改进LLM的生成结果。通过这种迭代的方式,可以逐步提高LLM的生成质量,并降低幻觉的风险。
技术框架:该框架包含以下几个主要模块:1) LLM行动生成器:利用LLM生成候选的行动方案。2) 一致性检查器:评估候选方案与系统约束和前瞻性预测的一致性。3) 外部反馈收集器:当一致性较低时,从外部来源(例如数字孪生)获取反馈。4) 上下文学习模块:利用外部反馈来改进LLM的生成结果。整个流程是一个迭代循环,直到生成满足一致性要求的行动方案。
关键创新:该论文最重要的技术创新点在于将LLM集成到一个迭代的反馈循环中,并利用外部知识来纠正LLM的幻觉。与现有方法相比,该方法能够更有效地控制LLM的生成过程,并提高生成结果的质量。此外,论文还提出了一个基于一致性检查的幻觉风险控制机制,并给出了ICL遗憾的理论界限。
关键设计:一致性检查器通过对比LLM生成的行动方案与预定义的系统约束和前瞻性预测来评估一致性。一致性得分低于阈值时,触发外部反馈收集。外部反馈通过数字孪生环境模拟行动方案的效果来获得。上下文学习模块使用收集到的反馈作为示例,通过prompting的方式引导LLM生成更符合实际情况的行动方案。一致性阈值的设置是关键参数,需要在幻觉风险和响应效率之间进行权衡。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架在四个公共数据集上,与前沿LLM相比,可以将事件恢复时间缩短高达30%。这表明该框架能够有效地降低LLM的幻觉风险,并提高事件响应的效率。此外,实验还验证了该框架的理论分析结果,即可以通过调整一致性阈值来控制幻觉风险。
🎯 应用场景
该研究成果可应用于各种安全管理场景,例如事件响应、漏洞修复、安全策略制定等。通过利用该框架,安全管理人员可以更有效地利用LLM的强大能力,提高安全管理的效率和准确性,降低安全风险。未来,该框架还可以扩展到其他领域,例如智能制造、金融风控等。
📄 摘要(原文)
Large language models (LLMs) are promising tools for supporting security management tasks, such as incident response planning. However, their unreliability and tendency to hallucinate remain significant challenges. In this paper, we address these challenges by introducing a principled framework for using an LLM as decision support in security management. Our framework integrates the LLM in an iterative loop where it generates candidate actions that are checked for consistency with system constraints and lookahead predictions. When consistency is low, we abstain from the generated actions and instead collect external feedback, e.g., by evaluating actions in a digital twin. This feedback is then used to refine the candidate actions through in-context learning (ICL). We prove that this design allows to control the hallucination risk by tuning the consistency threshold. Moreover, we establish a bound on the regret of ICL under certain assumptions. To evaluate our framework, we apply it to an incident response use case where the goal is to generate a response and recovery plan based on system logs. Experiments on four public datasets show that our framework reduces recovery times by up to 30% compared to frontier LLMs.