Surgery: Mitigating Harmful Fine-Tuning for Large Language Models via Attention Sink
作者: Guozhi Liu, Weiwei Lin, Tiansheng Huang, Ruichao Mo, Qi Mu, Xiumin Wang, Li Shen
分类: cs.AI
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出Surgery,通过注意力Sink机制缓解大语言模型有害微调带来的安全风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 有害微调 安全对齐 注意力机制 Sink散度
📋 核心要点
- 有害微调会破坏大语言模型的安全对齐,现有方法难以有效缓解由此产生的安全风险。
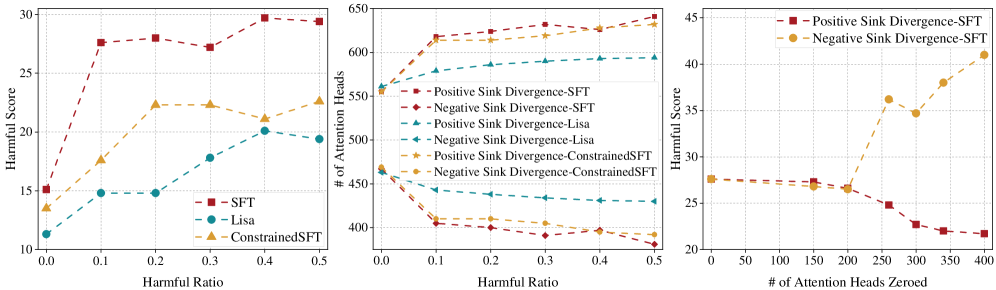
- 论文提出Surgery方法,通过正则化Sink散度,引导注意力头学习良性模式,从而降低模型学习有害模式的倾向。
- 实验结果表明,Surgery在多个基准测试中显著提升了防御性能,有效缓解了有害微调带来的安全问题。
📝 摘要(中文)
有害微调会破坏大型语言模型的安全对齐,带来严重的安全风险。本文利用注意力Sink机制来缓解有害微调。具体来说,我们首先为每个注意力头测量一个名为“Sink散度”的统计量,并观察到“不同的注意力头表现出两种不同的Sink散度符号”。为了理解其安全含义,我们进行了实验,发现当模型进行有害微调时,正Sink散度的注意力头数量随着模型有害性的增加而增加。基于这一发现,我们提出了一个可分离的Sink散度假设——“在微调期间与学习有害模式相关的注意力头可以通过其Sink散度的符号来分离”。基于该假设,我们提出了一种微调阶段的防御方法,称为Surgery。Surgery利用Sink散度抑制的正则化器,引导注意力头朝着负Sink散度组移动,从而降低模型学习和放大有害模式的倾向。大量实验表明,Surgery在BeaverTails、HarmBench和SorryBench基准测试中分别提高了5.90%、11.25%和9.55%的防御性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在经过有害微调后,其安全对齐遭到破坏,从而产生安全风险的问题。现有的防御方法可能无法充分缓解这种风险,导致模型在特定场景下表现出有害行为。
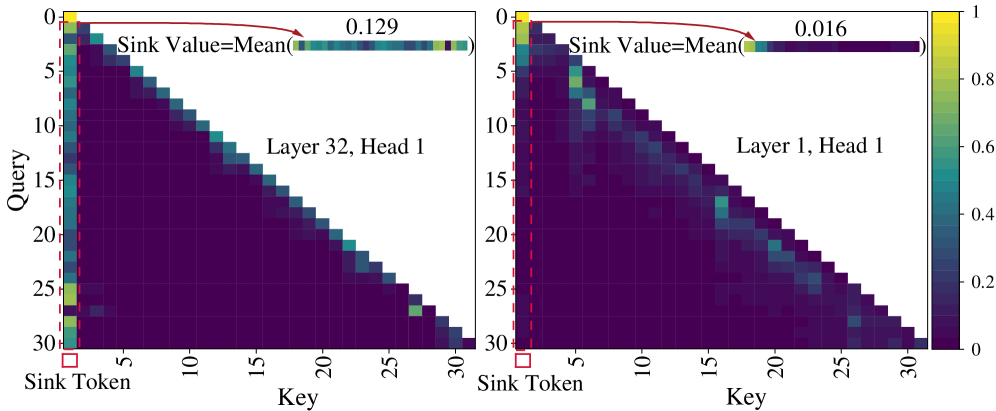
核心思路:论文的核心思路是利用注意力机制中的“Sink”现象,通过观察和分析不同注意力头的Sink散度,发现有害模式的学习与特定类型的注意力头相关联。通过抑制这些注意力头的活动,可以减少模型学习和放大有害模式的倾向。
技术框架:Surgery方法主要包含以下几个阶段:1) Sink散度计算:对每个注意力头计算Sink散度,用于区分不同类型的注意力头。2) Sink散度分析:分析Sink散度与模型有害性之间的关系,验证可分离的Sink散度假设。3) 正则化设计:设计Sink散度抑制的正则化项,用于在微调过程中引导注意力头朝着负Sink散度组移动。4) 微调训练:在微调过程中,将正则化项加入损失函数,从而实现对有害模式学习的抑制。
关键创新:论文的关键创新在于:1) 提出了Sink散度的概念,并将其与模型有害性联系起来。2) 提出了可分离的Sink散度假设,为防御有害微调提供了新的视角。3) 设计了Sink散度抑制的正则化器,实现了对有害模式学习的有效抑制。
关键设计:Surgery方法的关键设计包括:1) Sink散度的计算方式,需要选择合适的统计量来衡量注意力头的Sink行为。2) 正则化项的设计,需要平衡模型性能和安全性之间的关系。3) 正则化系数的选择,需要通过实验进行调整,以达到最佳的防御效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Surgery方法在BeaverTails、HarmBench和SorryBench三个基准测试中分别取得了5.90%、11.25%和9.55%的防御性能提升。这些结果表明,Surgery方法能够有效缓解有害微调带来的安全风险,并显著提升模型的安全性。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种场景下的安全性,例如,可以用于过滤有害内容、防止模型生成不当言论、以及提高模型在敏感领域的可靠性。此外,该方法还可以用于评估和改进现有模型的安全性,从而降低潜在的安全风险。
📄 摘要(原文)
Harmful fine-tuning can invalidate safety alignment of large language models, exposing significant safety risks. In this paper, we utilize the attention sink mechanism to mitigate harmful fine-tuning. Specifically, we first measure a statistic named \emph{sink divergence} for each attention head and observe that \emph{different attention heads exhibit two different signs of sink divergence}. To understand its safety implications, we conduct experiments and find that the number of attention heads of positive sink divergence increases along with the increase of the model's harmfulness when undergoing harmful fine-tuning. Based on this finding, we propose a separable sink divergence hypothesis -- \emph{attention heads associating with learning harmful patterns during fine-tuning are separable by their sign of sink divergence}. Based on the hypothesis, we propose a fine-tuning-stage defense, dubbed Surgery. Surgery utilizes a regularizer for sink divergence suppression, which steers attention heads toward the negative sink divergence group, thereby reducing the model's tendency to learn and amplify harmful patterns. Extensive experiments demonstrate that Surgery improves defense performance by 5.90\%, 11.25\%, and 9.55\% on the BeaverTails, HarmBench, and SorryBench benchmarks, respectively. Source code is available on https://github.com/Lslland/Surgery.