WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
作者: Zelai Xu, Zhexuan Xu, Ruize Zhang, Chunyang Zhu, Shi Yu, Weilin Liu, Quanlu Zhang, Wenbo Ding, Chao Yu, Yu Wang
分类: cs.AI, cs.LG, cs.MA
发布日期: 2026-02-04
💡 一句话要点
提出WideSeek-R1,通过多智能体强化学习扩展LLM宽度,解决广域信息检索问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 宽度扩展 广域信息检索 大型语言模型 并行计算
📋 核心要点
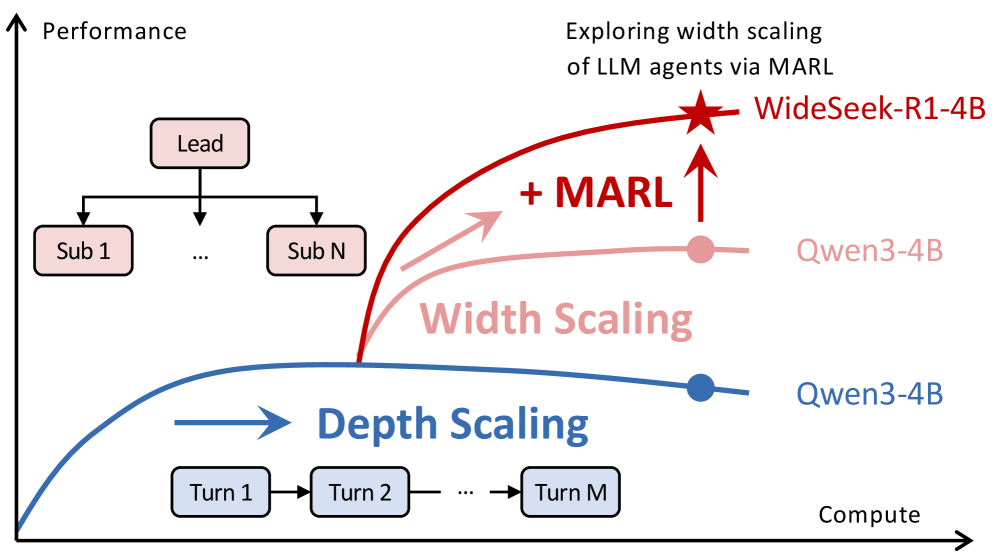
- 现有大型语言模型主要关注深度扩展,但在解决需要组织能力而非个体能力的任务时遇到瓶颈。
- WideSeek-R1通过多智能体强化学习训练领导者-子智能体框架,实现可扩展的编排和并行执行,从而扩展LLM的宽度。
- 实验表明,WideSeek-R1-4B在WideSearch基准测试中达到与DeepSeek-R1-671B相当的性能,并随着子智能体数量增加而提升。
📝 摘要(中文)
本文探讨了通过多智能体系统扩展大型语言模型(LLM)的宽度,以应对广域信息检索任务。现有方法通常依赖于手工设计的工作流程和轮流交互,无法有效并行化工作。为了解决这个问题,我们提出了WideSeek-R1,一个通过多智能体强化学习(MARL)训练的领导者-子智能体框架,旨在协同可扩展的编排和并行执行。WideSeek-R1利用共享的LLM,但具有隔离的上下文和专门的工具。我们在一个包含2万个广域信息检索任务的数据集上联合优化领导智能体和并行子智能体。实验结果表明,WideSeek-R1-4B在WideSearch基准测试中实现了40.0%的条目F1分数,与单智能体DeepSeek-R1-671B的性能相当。此外,WideSeek-R1-4B的性能随着并行子智能体数量的增加而持续提升,突显了宽度扩展的有效性。
🔬 方法详解
问题定义:论文旨在解决广域信息检索任务中,现有单智能体LLM在处理复杂、需要并行处理的任务时效率低下的问题。现有方法,如手工设计的多智能体系统,难以有效并行化工作,限制了整体性能的提升。
核心思路:论文的核心思路是通过宽度扩展,即利用多个并行工作的子智能体,共同完成广域信息检索任务。通过领导者智能体进行任务分解和协调,子智能体并行执行具体的信息检索和处理,从而提高整体效率和性能。这种方法旨在将单个大型模型的计算负担分散到多个较小的模型上,实现更高效的资源利用。
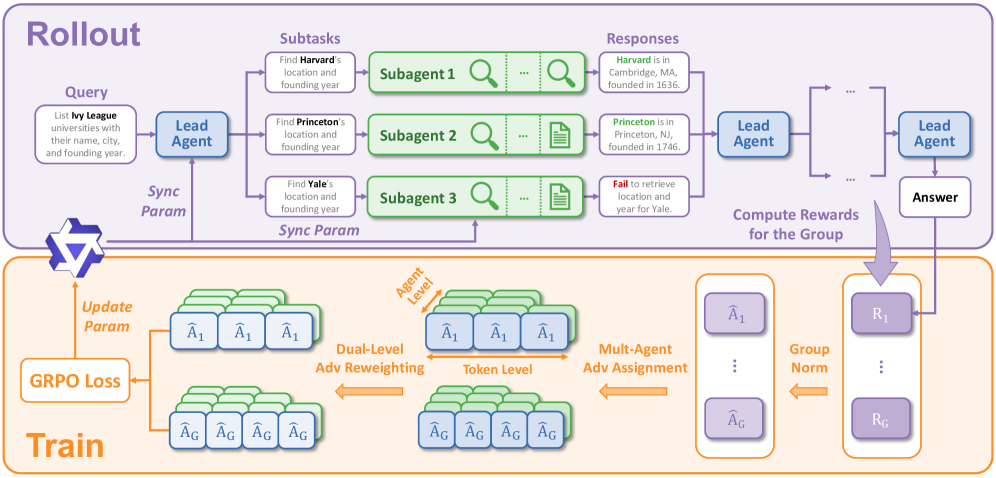
技术框架:WideSeek-R1采用领导者-子智能体框架。领导者智能体负责接收任务、进行任务分解、分配任务给子智能体,并整合子智能体的结果。子智能体则负责执行具体的检索和处理任务。所有智能体共享一个LLM,但具有独立的上下文和工具集。整个框架通过多智能体强化学习进行训练,以优化领导者和子智能体的协作策略。
关键创新:该论文的关键创新在于提出了一种基于多智能体强化学习的宽度扩展方法,用于解决广域信息检索问题。与传统的手工设计的多智能体系统相比,WideSeek-R1能够通过学习自动优化智能体之间的协作策略,实现更高效的并行执行。此外,通过共享LLM和隔离上下文,可以在保证性能的同时降低计算成本。
关键设计:WideSeek-R1的关键设计包括:1) 使用多智能体强化学习算法(具体算法未知)联合训练领导者和子智能体;2) 设计合适的奖励函数,鼓励智能体之间的有效协作和信息共享;3) 为每个智能体配备专门的工具集,以提高其在特定任务上的效率;4) 使用隔离的上下文,避免智能体之间的信息干扰;5) 通过实验确定最佳的子智能体数量,以平衡性能和计算成本。
🖼️ 关键图片

📊 实验亮点
WideSeek-R1-4B在WideSearch基准测试中实现了40.0%的条目F1分数,与单智能体DeepSeek-R1-671B的性能相当,证明了宽度扩展的有效性。更重要的是,WideSeek-R1-4B的性能随着并行子智能体数量的增加而持续提升,表明该框架具有良好的可扩展性。
🎯 应用场景
WideSeek-R1可应用于需要大规模信息收集和处理的场景,如市场调研、舆情分析、竞争情报、科学研究等。通过并行处理和智能协作,该方法能够显著提高信息检索的效率和准确性,为决策提供更全面的数据支持。未来,该技术有望应用于更广泛的领域,如智能客服、自动化报告生成等。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent-subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.