Learning the Value Systems of Agents with Preference-based and Inverse Reinforcement Learning
作者: Andrés Holgado-Sánchez, Holger Billhardt, Alberto Fernández, Sascha Ossowski
分类: cs.CY, cs.AI, cs.LG
发布日期: 2026-02-04
备注: 42 pages, 5 figures. Published in Journal of Autonomous Agents and Multi-Agent Systems
期刊: Holgado-Sánchez, A., Billhardt, H., Fernández, A., Ossowski, S. Learning the value systems of agents with preference-based and inverse reinforcement learning. Autonomous Agents Multi-Agent Systems 40, 4 (2026)
DOI: 10.1007/s10458-026-09732-0
💡 一句话要点
提出基于偏好和逆强化学习的智能体价值系统学习方法,解决人机协作中的价值对齐问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 价值系统学习 逆强化学习 偏好学习 人机协作 多目标马尔可夫决策过程
📋 核心要点
- 现有方法依赖人工设计的规范来估计价值系统,但由于需要大量人工干预,其规模受到限制,难以适应复杂场景。
- 该论文提出一种自动学习价值系统的方法,通过观察和人类演示,学习智能体的价值偏好,实现人机价值对齐。
- 通过模拟用例验证了该方法的有效性,表明其能够学习到符合人类偏好的价值系统,提升人机协作的效率和质量。
📝 摘要(中文)
本文提出了一种新颖的方法,用于从观察和人类演示中自动学习智能体的价值系统。针对开放计算机系统中自主软件智能体之间的交互,为了达成各方都能接受的协议,这些协议必须与伦理原则和道德价值观保持一致。然而,确保这一点非常困难,尤其是在不同的人类用户(及其软件智能体)可能持有不同的价值体系时,他们可能对个体道德价值观的重要性有不同的权重。此外,通常难以以计算方式指定特定上下文中价值的精确含义。本文提出了价值系统学习问题的形式化模型,将其实例化为基于多目标马尔可夫决策过程的序列决策领域,并提出了定制的基于偏好和逆强化学习算法来推断价值基础函数和价值系统。通过两个模拟用例来说明和评估该方法。
🔬 方法详解
问题定义:论文旨在解决在人机协作场景中,如何让智能体理解并遵循人类的价值体系,从而达成双方都能接受的协议。现有方法主要依赖人工设计的价值规范,这种方式需要大量的人工干预,难以扩展到复杂的、动态变化的环境中。此外,不同的人类用户可能持有不同的价值体系,如何处理价值冲突也是一个挑战。
核心思路:论文的核心思路是通过观察人类的决策行为和偏好,利用机器学习的方法自动学习智能体的价值系统。具体来说,将价值系统建模为一个函数,该函数能够将环境状态映射到价值评估,并通过逆强化学习和基于偏好的学习方法来估计该函数。这样,智能体就可以根据学习到的价值系统做出决策,从而与人类的价值偏好保持一致。
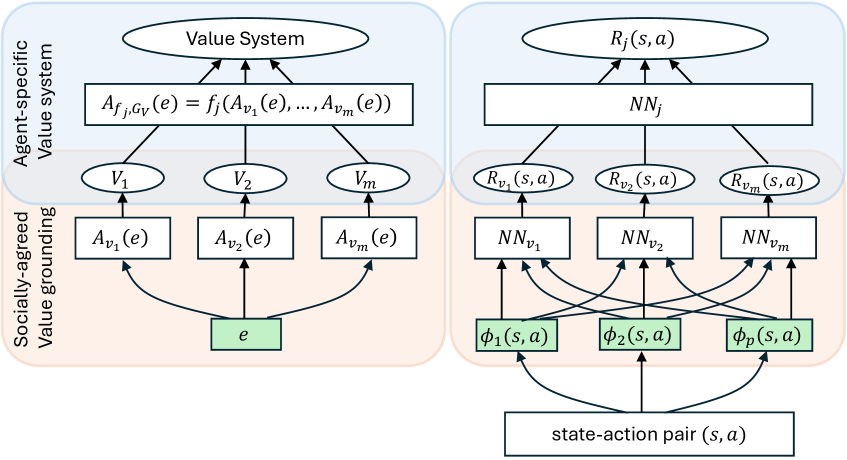
技术框架:整体框架包含以下几个主要模块:1) 环境建模:将问题建模为多目标马尔可夫决策过程(MOMDP),其中每个目标代表一个特定的价值维度。2) 数据收集:通过观察人类的决策行为或收集人类的偏好数据,构建训练数据集。3) 价值函数学习:利用逆强化学习(IRL)或基于偏好的学习方法,从数据中学习价值函数。具体而言,IRL方法通过最大化人类行为的概率来学习奖励函数,而基于偏好的学习方法则通过最小化模型预测与人类偏好之间的差异来学习价值函数。4) 决策制定:利用学习到的价值函数,智能体可以根据当前环境状态做出决策,从而实现与人类价值对齐的目标。
关键创新:论文的关键创新在于提出了一种自动学习价值系统的方法,该方法不需要人工设计价值规范,而是通过观察和学习人类的行为来推断价值偏好。此外,论文还提出了将价值系统学习问题建模为多目标马尔可夫决策过程,并利用逆强化学习和基于偏好的学习方法来解决该问题。这种方法能够有效地处理不同人类用户之间的价值冲突,并适应动态变化的环境。
关键设计:在价值函数学习方面,论文采用了两种主要方法:逆强化学习和基于偏好的学习。对于逆强化学习,论文采用了最大熵逆强化学习算法,该算法能够学习到更加鲁棒的奖励函数。对于基于偏好的学习,论文采用了pairwise comparison的方法,即要求人类对不同的决策方案进行两两比较,从而得到偏好数据。此外,论文还设计了一种价值基础函数,该函数能够将环境状态映射到价值评估,并利用神经网络来表示该函数。在训练过程中,论文采用了Adam优化器,并设置了合适的学习率和正则化参数。
🖼️ 关键图片

📊 实验亮点
论文通过两个模拟用例验证了所提出方法的有效性。实验结果表明,该方法能够有效地学习到符合人类偏好的价值系统,并能够提高人机协作的效率和质量。具体的性能数据和对比基线在论文中进行了详细的展示,表明该方法在价值对齐方面具有显著的优势。
🎯 应用场景
该研究成果可应用于人机协作机器人、自动驾驶、智能推荐系统等领域。例如,在人机协作机器人中,机器人可以学习人类操作员的价值偏好,从而更好地辅助人类完成任务。在自动驾驶领域,自动驾驶系统可以学习人类驾驶员的驾驶习惯和安全意识,从而提高驾驶安全性。在智能推荐系统中,推荐系统可以学习用户的兴趣偏好和道德价值观,从而提供更加个性化和符合伦理规范的推荐结果。
📄 摘要(原文)
Agreement Technologies refer to open computer systems in which autonomous software agents interact with one another, typically on behalf of humans, in order to come to mutually acceptable agreements. With the advance of AI systems in recent years, it has become apparent that such agreements, in order to be acceptable to the involved parties, must remain aligned with ethical principles and moral values. However, this is notoriously difficult to ensure, especially as different human users (and their software agents) may hold different value systems, i.e. they may differently weigh the importance of individual moral values. Furthermore, it is often hard to specify the precise meaning of a value in a particular context in a computational manner. Methods to estimate value systems based on human-engineered specifications, e.g. based on value surveys, are limited in scale due to the need for intense human moderation. In this article, we propose a novel method to automatically \emph{learn} value systems from observations and human demonstrations. In particular, we propose a formal model of the \emph{value system learning} problem, its instantiation to sequential decision-making domains based on multi-objective Markov decision processes, as well as tailored preference-based and inverse reinforcement learning algorithms to infer value grounding functions and value systems. The approach is illustrated and evaluated by two simulated use cases.