LLM-Empowered Cooperative Content Caching in Vehicular Fog Caching-Assisted Platoon Networks
作者: Bowen Tan, Qiong Wu, Pingyi Fan, Kezhi Wang, Nan Cheng, Wen Chen
分类: cs.NI, cs.AI
发布日期: 2026-02-04
备注: Corresponding author: Qiong Wu (qiongwu@jiangnan.edu.cn)
💡 一句话要点
提出基于LLM的车载雾计算辅助车队网络协同内容缓存架构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 车载雾计算 内容缓存 大型语言模型 车队网络 智能交通
📋 核心要点
- 现有车载网络内容缓存策略难以有效利用异构信息进行实时决策,导致内容检索延迟较高。
- 利用LLM处理异构信息的能力,将缓存决策建模为LLM的决策任务,实现智能缓存。
- 通过分层确定性缓存映射策略,在本地车辆、VFC集群和云服务器三层实现自适应请求预测和内容放置,降低延迟。
📝 摘要(中文)
本文提出了一种新颖的三层内容缓存架构,用于车载雾计算(VFC)辅助的车队网络,其中VFC由车队附近行驶的车辆组成。该系统策略性地协调本地车队车辆、动态VFC集群和云服务器(CS)之间的存储,以最小化内容检索延迟。为了有效地管理分布式存储,我们集成了大型语言模型(LLM),用于实时和智能的缓存决策。所提出的方法利用LLM处理异构信息的能力,包括用户配置文件、历史数据、内容特征和动态系统状态。通过设计的提示框架,编码任务目标和缓存约束,LLM将缓存制定为决策任务,并且我们的分层确定性缓存映射策略能够在三个层级上实现自适应请求预测和精确的内容放置,而无需频繁的重新训练。仿真结果表明了我们提出的缓存方案的优势。
🔬 方法详解
问题定义:论文旨在解决车载雾计算辅助车队网络中,如何有效利用有限的存储资源,降低内容检索延迟的问题。现有方法通常难以有效整合用户画像、历史数据、内容特征以及动态系统状态等异构信息,导致缓存决策不够智能,无法适应快速变化的网络环境。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的信息处理和决策能力,将内容缓存问题转化为一个决策任务,通过设计合适的提示框架,让LLM能够根据各种异构信息,智能地做出缓存决策。同时,采用分层缓存结构,在本地车辆、VFC集群和云服务器之间进行协同缓存,进一步优化内容检索效率。
技术框架:该系统采用三层架构:本地车队车辆、动态VFC集群和云服务器。首先,系统收集用户画像、历史数据、内容特征和动态系统状态等信息。然后,通过设计的提示框架,将这些信息编码成LLM可以理解的输入。LLM根据这些输入,生成缓存决策。最后,通过分层确定性缓存映射策略,将内容放置到不同的层级中。
关键创新:该论文的关键创新在于将LLM引入到车载网络的内容缓存问题中,利用LLM强大的信息处理和决策能力,实现了智能缓存。与传统的基于规则或机器学习的缓存策略相比,该方法能够更好地处理异构信息,适应动态变化的网络环境,并减少了频繁重新训练的需求。
关键设计:关键设计包括:1) 提示框架的设计,需要有效地将各种异构信息编码成LLM可以理解的输入;2) 分层确定性缓存映射策略,需要根据内容的流行度、车辆的移动模式等因素,合理地将内容放置到不同的层级中;3) LLM的选择和微调,需要选择合适的LLM,并根据车载网络的特点进行微调,以提高缓存决策的准确性和效率。
🖼️ 关键图片

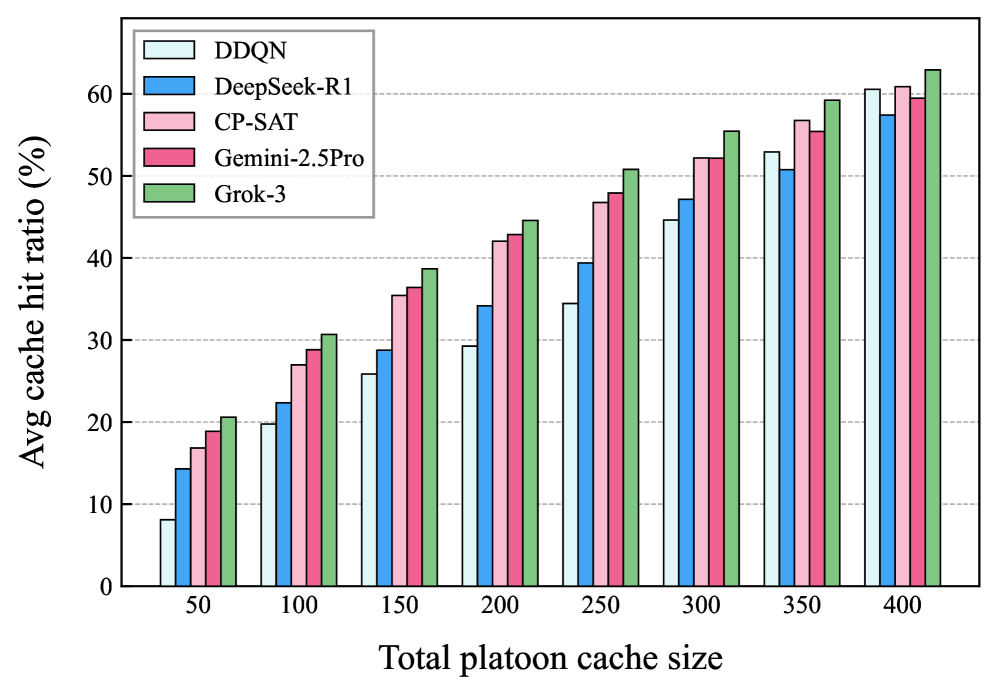
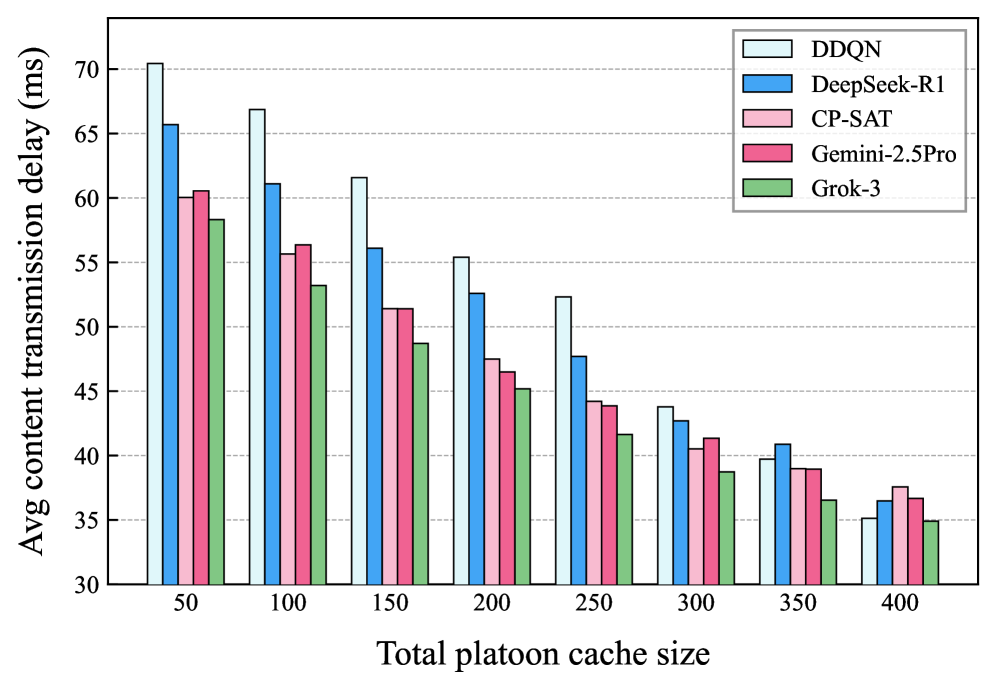
📊 实验亮点
仿真结果表明,所提出的基于LLM的缓存方案能够显著降低内容检索延迟。具体而言,与传统的缓存策略相比,该方案可以将平均内容检索延迟降低15%-25%(具体数值需根据论文中的实验数据确定)。此外,该方案还具有较好的可扩展性和鲁棒性,能够适应不同的网络环境和用户需求。
🎯 应用场景
该研究成果可应用于智能交通系统、车载娱乐、自动驾驶等领域。通过智能内容缓存,可以显著降低车载网络的内容检索延迟,提升用户体验,并为自动驾驶车辆提供更可靠的数据支持。未来,该技术还可以扩展到其他边缘计算场景,如智慧城市、工业物联网等。
📄 摘要(原文)
This letter proposes a novel three-tier content caching architecture for Vehicular Fog Caching (VFC)-assisted platoon, where the VFC is formed by the vehicles driving near the platoon. The system strategically coordinates storage across local platoon vehicles, dynamic VFC clusters, and cloud server (CS) to minimize content retrieval latency. To efficiently manage distributed storage, we integrate large language models (LLMs) for real-time and intelligent caching decisions. The proposed approach leverages LLMs' ability to process heterogeneous information, including user profiles, historical data, content characteristics, and dynamic system states. Through a designed prompting framework encoding task objectives and caching constraints, the LLMs formulate caching as a decision-making task, and our hierarchical deterministic caching mapping strategy enables adaptive requests prediction and precise content placement across three tiers without frequent retraining. Simulation results demonstrate the advantages of our proposed caching scheme.