Agent-Omit: Training Efficient LLM Agents for Adaptive Thought and Observation Omission via Agentic Reinforcement Learning
作者: Yansong Ning, Jun Fang, Naiqiang Tan, Hao Liu
分类: cs.AI, cs.LG
发布日期: 2026-02-04
备注: Under Review
🔗 代码/项目: GITHUB
💡 一句话要点
Agent-Omit:通过Agentic强化学习训练高效LLM Agent,自适应省略思考和观察
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: LLM Agent 强化学习 自适应省略 效率优化 Agentic Reinforcement Learning
📋 核心要点
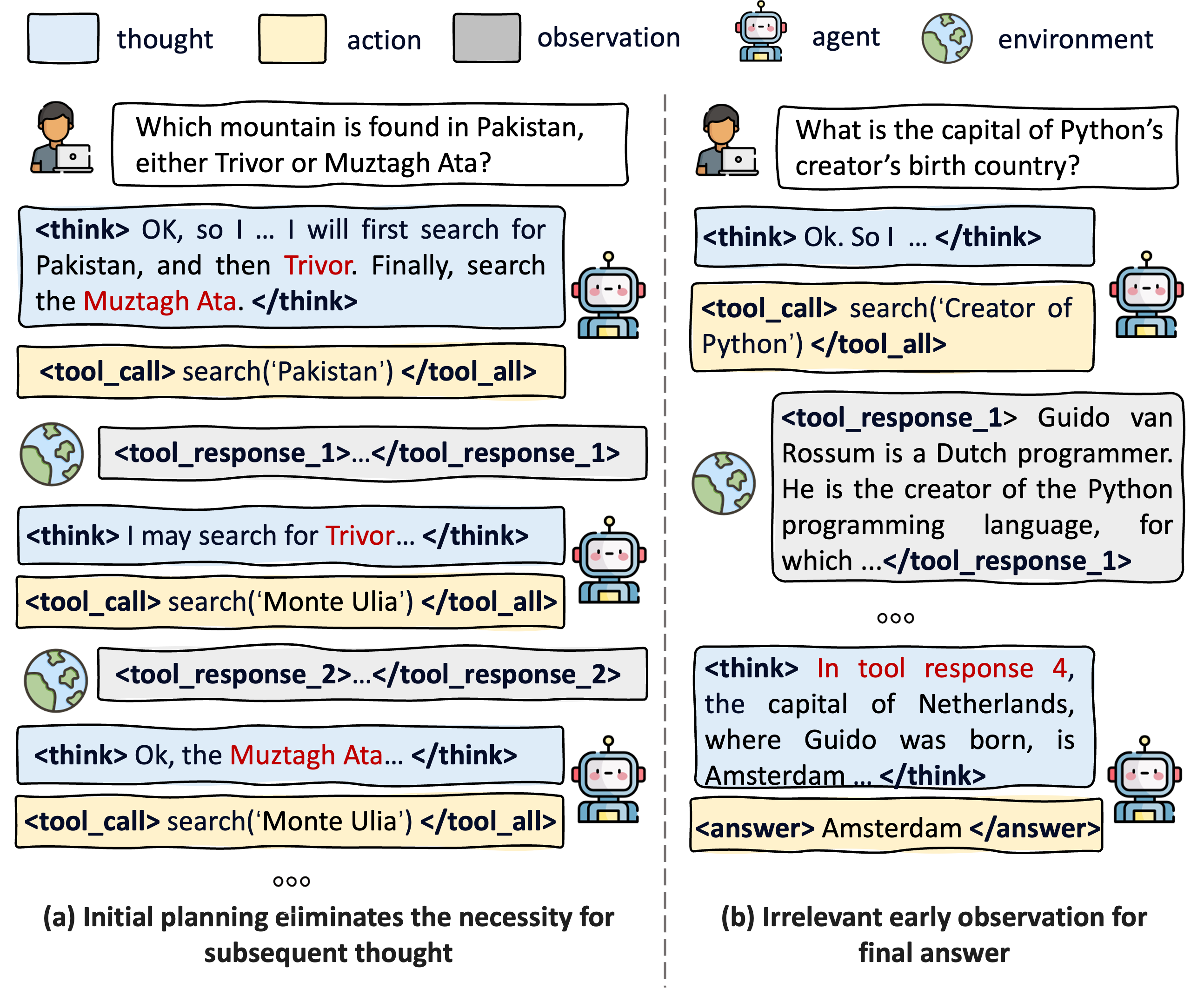
- 现有方法忽略了Agent在不同交互轮次中思考的必要性和观察的效用差异,导致效率低下。
- Agent-Omit通过Agentic强化学习,使LLM Agent能够自适应地省略冗余的思考和观察步骤。
- 实验表明,Agent-Omit在多个Agent基准测试中实现了与前沿模型相当的性能,并提升了效率。
📝 摘要(中文)
本文提出了一种名为Agent-Omit的统一训练框架,旨在提升LLM Agent在多轮交互中的效率,使其能够自适应地省略冗余的思考和观察。研究首先定量分析了思考和观察对Agent有效性和效率的影响。然后,通过合成少量冷启动数据,包含单轮和多轮省略场景,对Agent进行微调,使其具备初步的省略行为能力。进一步地,引入了一种omit-aware的Agentic强化学习方法,结合双重采样机制和定制的省略奖励,激励Agent的自适应省略能力。理论上证明了省略策略的偏差受KL散度上界约束。在五个Agent基准测试上的实验结果表明,Agent-Omit-8B的性能可与七个前沿LLM Agent相媲美,并且比七种高效LLM Agent方法实现了最佳的有效性-效率权衡。代码和数据已开源。
🔬 方法详解
问题定义:现有LLM Agent在多轮交互中,通常会进行大量的思考和观察,但并非所有步骤都是必要的。现有方法平等对待所有交互轨迹,忽略了不同轮次中思考的必要性和观察的效用差异,导致计算资源浪费和效率低下。因此,需要一种方法能够让Agent自适应地判断何时应该省略思考或观察,从而提高效率。
核心思路:Agent-Omit的核心思路是通过强化学习训练Agent,使其能够根据当前环境状态和历史交互信息,自适应地决定是否省略思考或观察步骤。通过引入省略奖励,鼓励Agent在不影响任务完成的情况下,尽可能地省略冗余步骤,从而实现效率和效果的平衡。
技术框架:Agent-Omit的整体框架包含以下几个主要阶段:1) 冷启动数据合成:合成包含单轮和多轮省略场景的少量数据,用于Agent的初步微调。2) Agent微调:使用合成数据对LLM Agent进行微调,使其具备初步的省略行为能力。3) Omit-aware Agentic强化学习:使用强化学习方法,结合双重采样机制和定制的省略奖励,进一步训练Agent的自适应省略能力。4) 推理阶段:Agent在与环境交互时,根据当前状态和历史信息,决定是否省略思考或观察步骤。
关键创新:Agent-Omit的关键创新在于:1) 提出了omit-aware的Agentic强化学习方法,能够有效地训练Agent的自适应省略能力。2) 引入了双重采样机制,平衡了省略和不省略两种行为的样本比例,提高了训练效率。3) 设计了定制的省略奖励,鼓励Agent在不影响任务完成的情况下,尽可能地省略冗余步骤。
关键设计:在强化学习阶段,Agent-Omit使用了PPO算法进行训练。双重采样机制包括行为采样和经验回放采样,分别用于探索新的省略策略和利用历史经验。省略奖励的设计考虑了任务完成情况和省略步骤的数量,旨在鼓励Agent在保证任务完成的前提下,尽可能地省略冗余步骤。KL散度被用于约束省略策略的偏差,保证训练的稳定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Agent-Omit-8B在五个Agent基准测试中取得了与七个前沿LLM Agent相媲美的性能,并且比七种高效LLM Agent方法实现了最佳的有效性-效率权衡。具体来说,Agent-Omit在保持甚至略微提升性能的同时,显著减少了Agent的思考和观察步骤,从而提高了效率。
🎯 应用场景
Agent-Omit具有广泛的应用前景,可以应用于各种需要与环境进行多轮交互的LLM Agent任务中,例如智能客服、自动化流程、游戏AI等。通过自适应地省略冗余的思考和观察步骤,可以显著提高Agent的效率,降低计算成本,并提升用户体验。该研究为开发更高效、更智能的LLM Agent提供了新的思路。
📄 摘要(原文)
Managing agent thought and observation during multi-turn agent-environment interactions is an emerging strategy to improve agent efficiency. However, existing studies treat the entire interaction trajectories equally, overlooking the thought necessity and observation utility varies across turns. To this end, we first conduct quantitative investigations into how thought and observation affect agent effectiveness and efficiency. Based on our findings, we propose Agent-Omit, a unified training framework that empowers LLM agents to adaptively omit redundant thoughts and observations. Specifically, we first synthesize a small amount of cold-start data, including both single-turn and multi-turn omission scenarios, to fine-tune the agent for omission behaviors. Furthermore, we introduce an omit-aware agentic reinforcement learning approach, incorporating a dual sampling mechanism and a tailored omission reward to incentivize the agent's adaptive omission capability. Theoretically, we prove that the deviation of our omission policy is upper-bounded by KL-divergence. Experimental results on five agent benchmarks show that our constructed Agent-Omit-8B could obtain performance comparable to seven frontier LLM agent, and achieve the best effectiveness-efficiency trade-off than seven efficient LLM agents methods. Our code and data are available at https://github.com/usail-hkust/Agent-Omit.