Empirical-MCTS: Continuous Agent Evolution via Dual-Experience Monte Carlo Tree Search
作者: Hao Lu, Haoyuan Huang, Yulin Zhou, Chen Li, Ningxin Zhu
分类: cs.AI, cs.CL
发布日期: 2026-02-04
备注: 9 pages, 5 figures
💡 一句话要点
提出 Empirical-MCTS,通过双重经验蒙特卡洛树搜索实现连续Agent进化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 蒙特卡洛树搜索 经验积累 大型语言模型 推理 元提示 Agent进化 持续学习
📋 核心要点
- 现有基于MCTS的LLM推理方法是无状态的,无法积累历史经验,限制了其解决复杂问题的能力。
- Empirical-MCTS通过双环框架,利用成对经验进化元提示和记忆优化Agent,实现经验的持续积累和利用。
- 在多个复杂推理基准测试中,Empirical-MCTS显著优于传统MCTS方法和独立的经验驱动Agent。
📝 摘要(中文)
本文提出 Empirical-MCTS,一个双环框架,将无状态搜索转变为连续的、非参数的学习过程,以提升大型语言模型(LLMs)的推理能力。该框架通过两个新颖机制统一了局部探索与全局记忆优化:成对经验进化元提示(PE-EMP)和记忆优化Agent。PE-EMP作为局部搜索中的自反优化器,利用成对反馈动态合成自适应标准,并实时进化元提示(系统提示)。同时,记忆优化Agent将全局知识库作为动态策略先验,采用原子操作提炼跨问题的高质量见解。在AIME25、ARC-AGI-2和MathArena Apex等复杂推理基准上的大量评估表明,Empirical-MCTS显著优于无状态MCTS策略和独立的经验驱动Agent。这些结果强调了将结构化搜索与经验积累相结合对于掌握复杂、开放式推理任务的关键必要性。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)推理方法,特别是基于蒙特卡洛树搜索(MCTS)的方法,通常是无状态的。这意味着每次解决新的问题时,模型都会从头开始搜索,无法利用之前解决问题的经验。这种方式与人类解决问题的模式不同,人类会不断积累经验并利用这些经验来更有效地解决新问题。因此,如何让LLMs能够像人类一样积累经验,并将其用于指导后续的推理过程,是一个重要的研究问题。
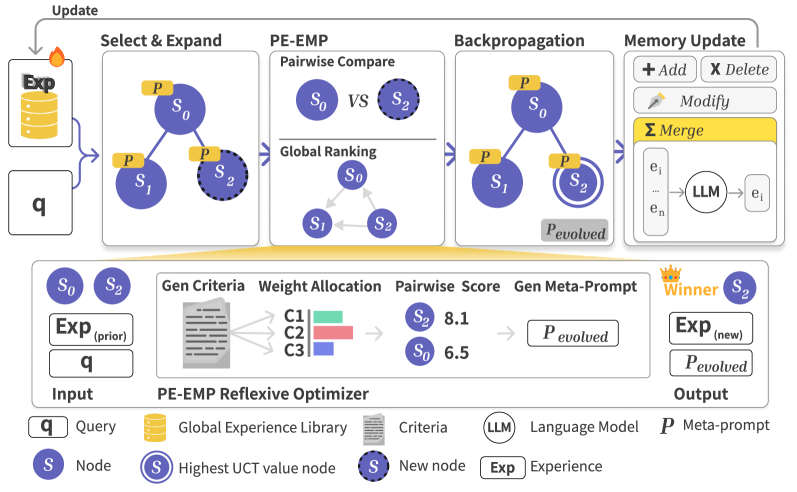
核心思路:Empirical-MCTS的核心思路是将无状态的MCTS搜索过程转化为一个连续的学习过程。通过维护一个全局的经验库,并利用这个经验库来指导后续的搜索过程,从而实现经验的积累和利用。具体来说,该方法通过两个关键机制来实现这一目标:成对经验进化元提示(PE-EMP)和记忆优化Agent。PE-EMP负责在局部搜索过程中动态优化元提示,而记忆优化Agent负责管理全局经验库,并从中提取有用的信息。
技术框架:Empirical-MCTS采用双环框架。内环是基于MCTS的局部搜索过程,其中PE-EMP负责动态优化元提示,以提高搜索效率。外环是全局经验优化过程,其中记忆优化Agent负责管理全局经验库,并利用原子操作来提炼高质量的见解。整个框架通过不断地迭代内环和外环,实现经验的持续积累和利用。具体流程如下:1. 初始化:初始化全局经验库和元提示。2. 内环搜索:使用MCTS进行局部搜索,并利用PE-EMP动态优化元提示。3. 经验更新:将本次搜索的经验添加到全局经验库中。4. 全局优化:利用记忆优化Agent对全局经验库进行优化,提取高质量的见解。5. 重复步骤2-4,直到达到停止条件。
关键创新:Empirical-MCTS的关键创新在于将无状态的MCTS搜索过程转化为一个连续的学习过程。通过引入全局经验库和记忆优化Agent,实现了经验的积累和利用。与传统的MCTS方法相比,Empirical-MCTS能够更好地利用历史经验,从而提高解决复杂问题的能力。此外,PE-EMP机制能够动态优化元提示,进一步提高了搜索效率。
关键设计:PE-EMP采用成对反馈机制来动态合成自适应标准,并进化元提示。记忆优化Agent采用原子操作来提炼跨问题的高质量见解。具体的参数设置和网络结构在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
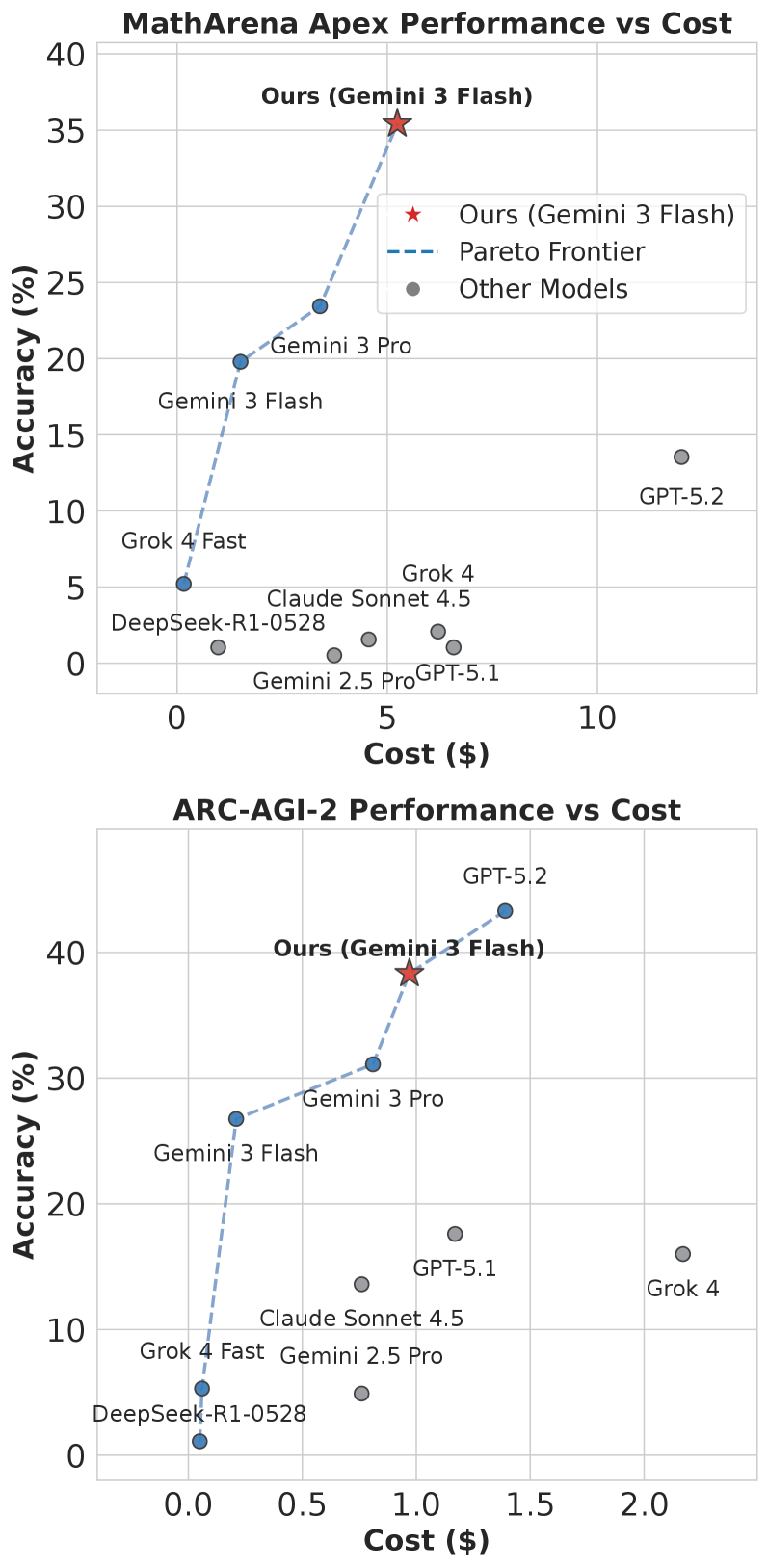
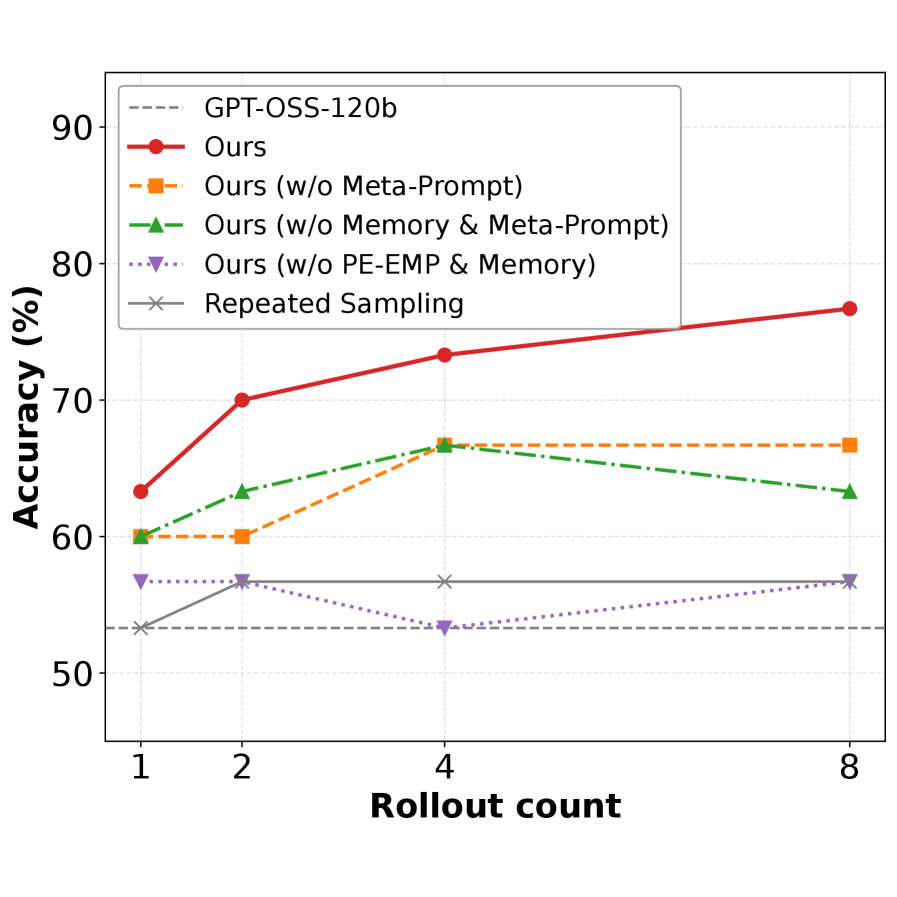
实验结果表明,Empirical-MCTS在AIME25、ARC-AGI-2和MathArena Apex等复杂推理基准上显著优于无状态MCTS策略和独立的经验驱动Agent。具体性能数据和提升幅度在论文中没有明确给出,属于未知信息。但总体而言,实验结果验证了将结构化搜索与经验积累相结合的有效性。
🎯 应用场景
Empirical-MCTS具有广泛的应用前景,可应用于需要复杂推理和决策的领域,例如:智能客服、自动驾驶、金融风险评估、医疗诊断等。通过不断积累经验和优化策略,该方法可以显著提高Agent在复杂环境中的表现,并为解决开放式问题提供新的思路。未来,该方法有望应用于更广泛的领域,并推动人工智能技术的发展。
📄 摘要(原文)
Inference-time scaling strategies, particularly Monte Carlo Tree Search (MCTS), have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). However, current approaches remain predominantly stateless, discarding successful reasoning patterns after each problem instance and failing to mimic the empirical accumulation of wisdom characteristic of human problem-solving. To bridge this gap, we introduce Empirical-MCTS, a dual-loop framework that transforms stateless search into a continuous, non-parametric learning process. The framework unifies local exploration with global memory optimization through two novel mechanisms: Pairwise-Experience-Evolutionary Meta-Prompting (PE-EMP) and a Memory Optimization Agent. PE-EMP functions as a reflexive optimizer within the local search, utilizing pairwise feedback to dynamically synthesize adaptive criteria and evolve meta-prompts (system prompts) in real-time. Simultaneously, the Memory Optimization Agent manages a global repository as a dynamic policy prior, employing atomic operations to distill high-quality insights across problems. Extensive evaluations on complex reasoning benchmarks, including AIME25, ARC-AGI-2, and MathArena Apex, demonstrate that Empirical-MCTS significantly outperforms both stateless MCTS strategies and standalone experience-driven agents. These results underscore the critical necessity of coupling structured search with empirical accumulation for mastering complex, open-ended reasoning tasks.